

Published as a conference paper at ICLR 2024
WHEN SCALING MEETS LLM FINETUNING:
THE EFFECT OF DATA, MODEL AND FINETUNING
METHOD
Biao Zhang
†
Zhongtao Liu
⋄
Colin Cherry
⋄
Orhan Firat
†
†
Google DeepMind
⋄
Google Research
{biaojiaxing,zhongtao,colincherry,orhanf}@google.com
ABSTRACT
While large language models (LLMs) often adopt finetuning to unlock their ca-
pabilities for downstream applications, our understanding on the inductive biases
(especially the scaling properties) of different finetuning methods is still limited.
To fill this gap, we conduct systematic experiments studying whether and how dif-
ferent scaling factors, including LLM model size, pretraining data size, new fine-
tuning parameter size and finetuning data size, affect the finetuning performance.
We consider two types of finetuning – full-model tuning (FMT) and parameter ef-
ficient tuning (PET, including prompt tuning and LoRA), and explore their scaling
behaviors in the data-limited regime where the LLM model size substantially out-
weighs the finetuning data size. Based on two sets of pretrained bilingual LLMs
from 1B to 16B and experiments on bilingual machine translation and multilin-
gual summarization benchmarks, we find that 1) LLM finetuning follows a power-
based multiplicative joint scaling law between finetuning data size and each other
scaling factor; 2) LLM finetuning benefits more from LLM model scaling than
pretraining data scaling, and PET parameter scaling is generally ineffective; and
3) the optimal finetuning method is highly task- and finetuning data-dependent.
We hope our findings could shed light on understanding, selecting and developing
LLM finetuning methods.
1 INTRODUCTION
Leveraging and transferring the knowledge encoded in large-scale pretrained models for downstream
applications has become the standard paradigm underlying the recent success achieved in various
domains (Devlin et al., 2019; Lewis et al., 2020; Raffel et al., 2020; Dosovitskiy et al., 2021; Baevski
et al., 2020), with the remarkable milestone set by large language models (LLMs) that have yielded
ground-breaking performance across language tasks (Brown et al., 2020; Zhang et al., 2022b; Scao
et al., 2022; Touvron et al., 2023). Advanced LLMs, such as GPT-4 (OpenAI, 2023) and PaLM
2 (Anil et al., 2023), often show emergent capabilities and allow for in-context learning that could
use just a few demonstration examples to perform complex reasoning and generation tasks (Wei
et al., 2022; Zhang et al., 2023; Fu et al., 2023; Shen et al., 2023). Still, LLM finetuning is required
and widely adopted to unlock new and robust capabilities for creative tasks, get the most for focused
downstream tasks, and align its value with human preferences (Ouyang et al., 2022; Yang et al.,
2023; Gong et al., 2023; Schick et al., 2023). This becomes more significant in traditional industrial
applications due to the existence of large-scale annotated task-specific data accumulated over years.
There are many potential factors affecting the performance of LLM finetuning, including but not
limited to 1) pretraining conditions, such as LLM model size and pretraining data size; and 2) fine-
tuning conditions, such as downstream task, finetuning data size and finetuning methods. Intuitively,
the pretraining controls the quality of the learned representation and knowledge in pretrained LLMs,
and the finetuning affects the degree of transfer to the donwstream task. While previous studies have
well explored the scaling for LLM pretraining or training from scratch (Kaplan et al., 2020; Hoff-
mann et al., 2022) and the development of advanced efficient finetuning methods (Hu et al., 2021;
He et al., 2022), the question of whether and how LLM finetuning scales with the above factors
unfortunately receives very little attention (Hernandez et al., 2021), which is the focus of our study.
1
arXiv:2402.17193v1 [cs.CL] 27 Feb 2024


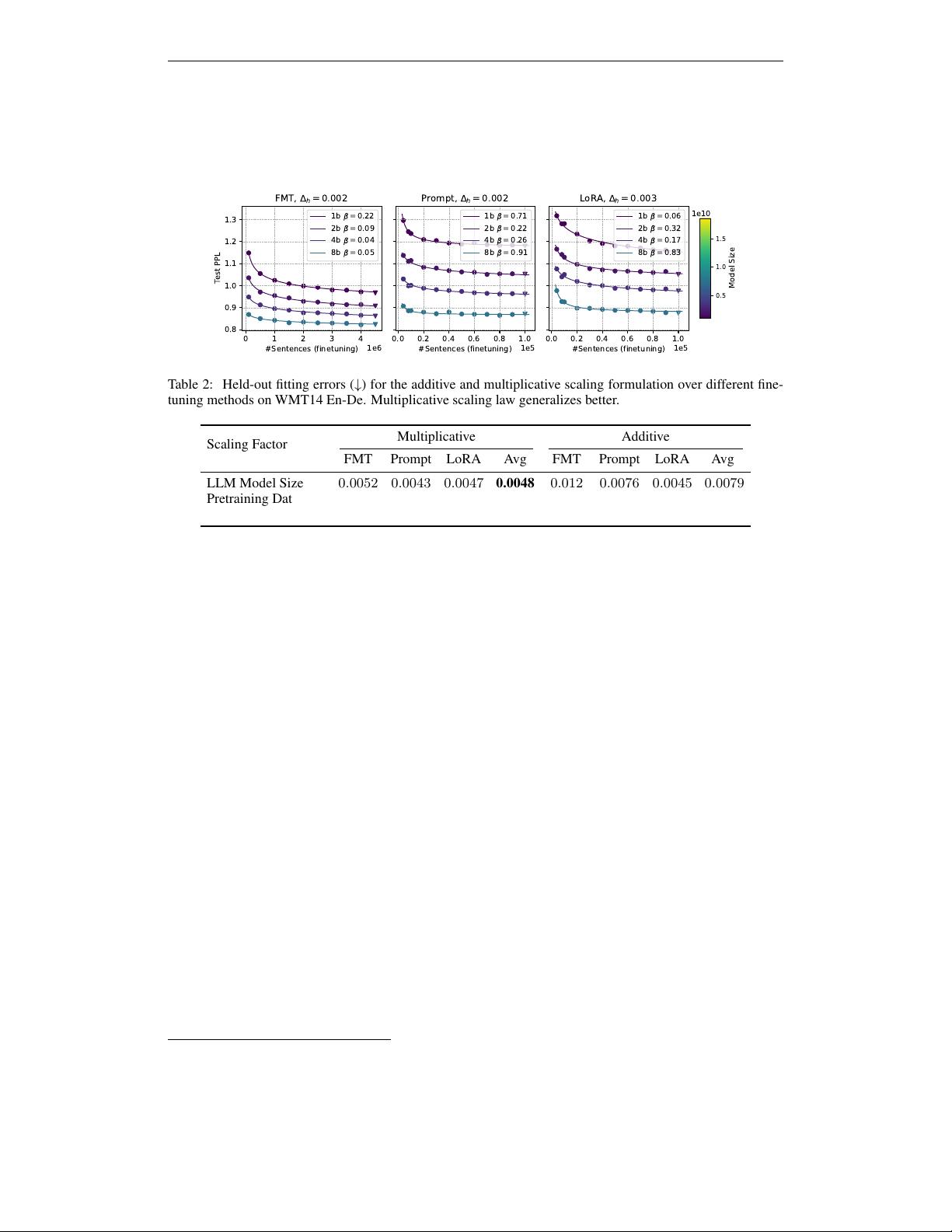
剩余19页未读,继续阅读
资源评论


pk_xz123456
- 粉丝: 2275
- 资源: 2353

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- JAVA的SpringBoot项目记账本源码带开发文档数据库 MySQL源码类型 WebForm
- NetBox2及大疆智图影像缓存lrc模板
- 123456789自用解答題
- JAVA的SpringBoot个人理财系统源码数据库 MySQL源码类型 WebForm
- 全屋智能全球市场报告:2023年中国全屋智能行业市场规模已达到3705亿元
- 康复医疗全球市场报告:2023年年复合增长率高达18.19%
- 微信小程序期末大作业-商城-2024(底部导航栏,轮播图,注册登录,购物车等等)
- 碘产业全球市场报告:2023年全球碘需求量已攀升至约3.86万吨
- 基于CNN、RNN、GCN、BERT的中文文本分类源码Python高分期末大作业
- 最新源支付Ypay系统开心稳定最新免授权源码,三平台免挂免签约支付
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


