

REAL: Response Embedding-based Alignment for LLMs
Honggen Zhang
1
, Igor Molybog
1
, June Zhang
1
*
, Xufeng Zhao
2
,
1
Univerity of Hawaii at Manoa,
2
University of Hamburg,
Email:{honggen,molybog,zjz}@hawaii.edu{xufeng.zhao}@uni-hamburg.de
Abstract
Aligning large language models (LLMs) to hu-
man preferences is a crucial step in building
helpful and safe AI tools, which usually in-
volve training on supervised datasets. Popular
algorithms such as Direct Preference Optimiza-
tion rely on pairs of AI-generated responses
ranked according to human feedback. The la-
beling process is the most labor-intensive and
costly part of the alignment pipeline, and im-
proving its efficiency would have a meaning-
ful impact on AI development. We propose a
strategy for sampling a high-quality training
dataset that focuses on acquiring the most in-
formative response pairs for labeling out of a
set of AI-generated responses. Experimental
results on synthetic HH-RLHF benchmarks in-
dicate that choosing dissimilar response pairs
enhances the direct alignment of LLMs while
reducing inherited labeling errors. We also
applied our method to the real-world dataset
SHP2, selecting optimal pairs from multiple
responses. The model aligned on dissimilar
response pairs obtained the best win rate on
the dialogue task. Our findings suggest that
focusing on less similar pairs can improve
the efficiency of LLM alignment, saving up
to
65%
of annotators’ work. The code of
the work can be found
https://github.com/
honggen-zhang/REAL-Alignment
1 Introduction
Large Language models (LLMs), empowered by
the enormous pre-trained dataset from the Internet,
show the power to generate the answers to vari-
ous questions and solutions to challenging tasks.
However, they might generate undesirable content
that is useless or even harmful to humans (Wang
et al., 2024). Additional training steps are required
to optimize LLMs and, thus, align their responses
with human preferences. For that purpose, Chris-
tiano et al. (2017) proposed Reinforcement learning
*
Corresponding Author
from human feedback (RLHF). It consists of esti-
mating the human preference reward model (RM)
from response preference data (Ouyang et al., 2022)
and steering LLM parameters using a popular re-
inforcement learning algorithm of proximal pol-
icy optimization (PPO). RLHF requires extensive
computational resources and is prone to training
instabilities.
Recently, direct alignment from preference
(DAP) approach, which does not explicitly learn
the reward model, has emerged as an alternative to
RLHF (Zhao et al., 2022; Song et al., 2023; Zhao
et al., 2023; Xu et al., 2023; Rafailov et al., 2024).
Direct Preference Optimization (DPO) (Rafailov
et al., 2024; Azar et al., 2023) is a milestone
DAP method. It formulates the problem of learn-
ing human preferences through finetuning LLM
with implicit reward model using a training set
D = {x
i
, y
+
i
, y
−
i
}
N
i=1
, where
x
i
is the
i
th prompt,
y
+
i
, y
−
i
are the corresponding preferred and not-
preferred responses.
DPO requires the explicit preference signal from
an annotator within the dataset. Some DPO varia-
tions such as Contrastive Post-training (Xu et al.,
2023), RPO(Song et al., 2023) were proposed to
augment
D
using AI but might generate low-quality
pairs. The labeling rough estimate is $0.1 - $1
per prompt; with 100,000-1,000,000 prompts, it
would cost approximately $100,000 to augment the
dataset. Some other DPO variation methods(Guo
et al., 2024; Yu et al., 2024) actively choose better
samples using additional annotators at the cost of
increased computations.
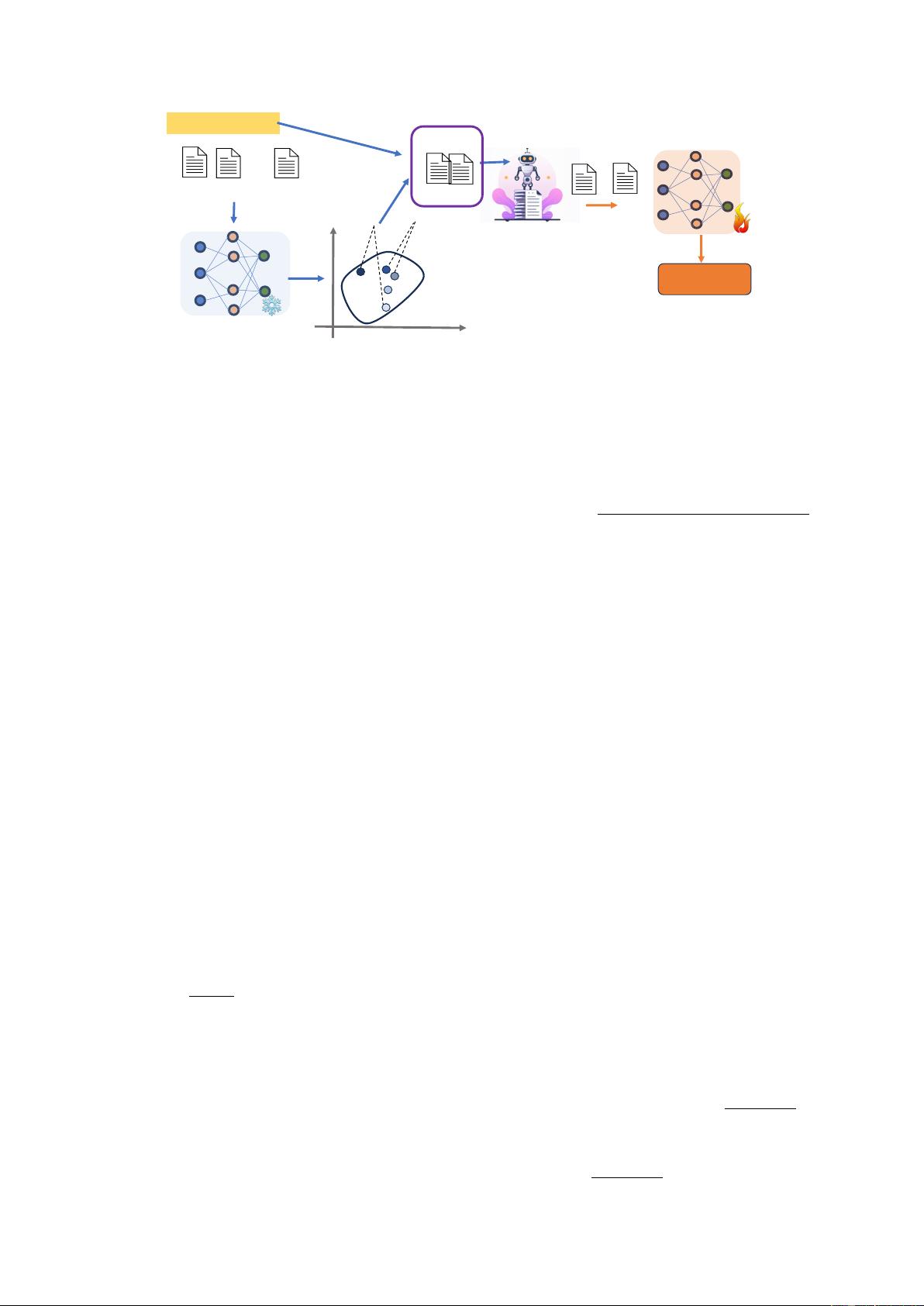
In this paper, we propose a novel method for en-
hancing DPO learning with efficient data selection
(see Fig. 1). We should only train DPO on the most
informative subset of samples in
D
. Inspired by
works in contrastive learning(Chen et al., 2020), we
connect the usefulness of response pair
(y
i
, y
j
)
to
the cosine similarity between their representations
in the embedding space. Sampling similar pairs
1
arXiv:2409.17169v1 [cs.CL] 17 Sep 2024

剩余12页未读,继续阅读
资源评论


sp_fyf_2024
- 粉丝: 2103
- 资源: 66











