2023/6/28 09:39
大模型综述来了!一文带你理清全球AI巨头的大模型进化史
https://mp.weixin.qq.com/s/wxgP42EI1ypcLKPsVqdH5A
1/10
大模型综述来了!一文带你理清全球AI巨头的大模型进化史
夕 小 瑶 科 技 说 原 创
作 者 | 小 戏 , Python
如果自己是一个大模型的小白,第 一 眼 看 到 GPT 、 PaLm、 LLaMA 这 些 单 词 的 怪 异 组 合 会
作 何 感 想 ?假如再往深里入门,又 看 到 BERT、 BART、 Ro BERTa、 ELMo 这 些 奇 奇 怪 怪 的
词 一 个 接 一 个 蹦 出 来 , 不 知 道 作 为 小 白 的 自 己 心 里 会 不 会 抓 狂 ?
哪怕是一个久居 NLP 这个小圈子的老鸟,伴随着大模型这爆炸般的发展速度,可 能 恍 惚 一 下
也 会 跟 不 上 这 追 新 打 快 日 新 月 异 的 大 模 型 到 底 是 何 门 何 派 用 的 哪 套 武 功 。这个时候可能就
需要请出一篇大模型综述来帮忙了!这篇由亚马逊、得克萨斯农工大学与莱斯大学的研究者推
出 的 大 模 型 综 述 《 Harnessing the P ower of LLMs in Practice: A Survey on ChatGPT
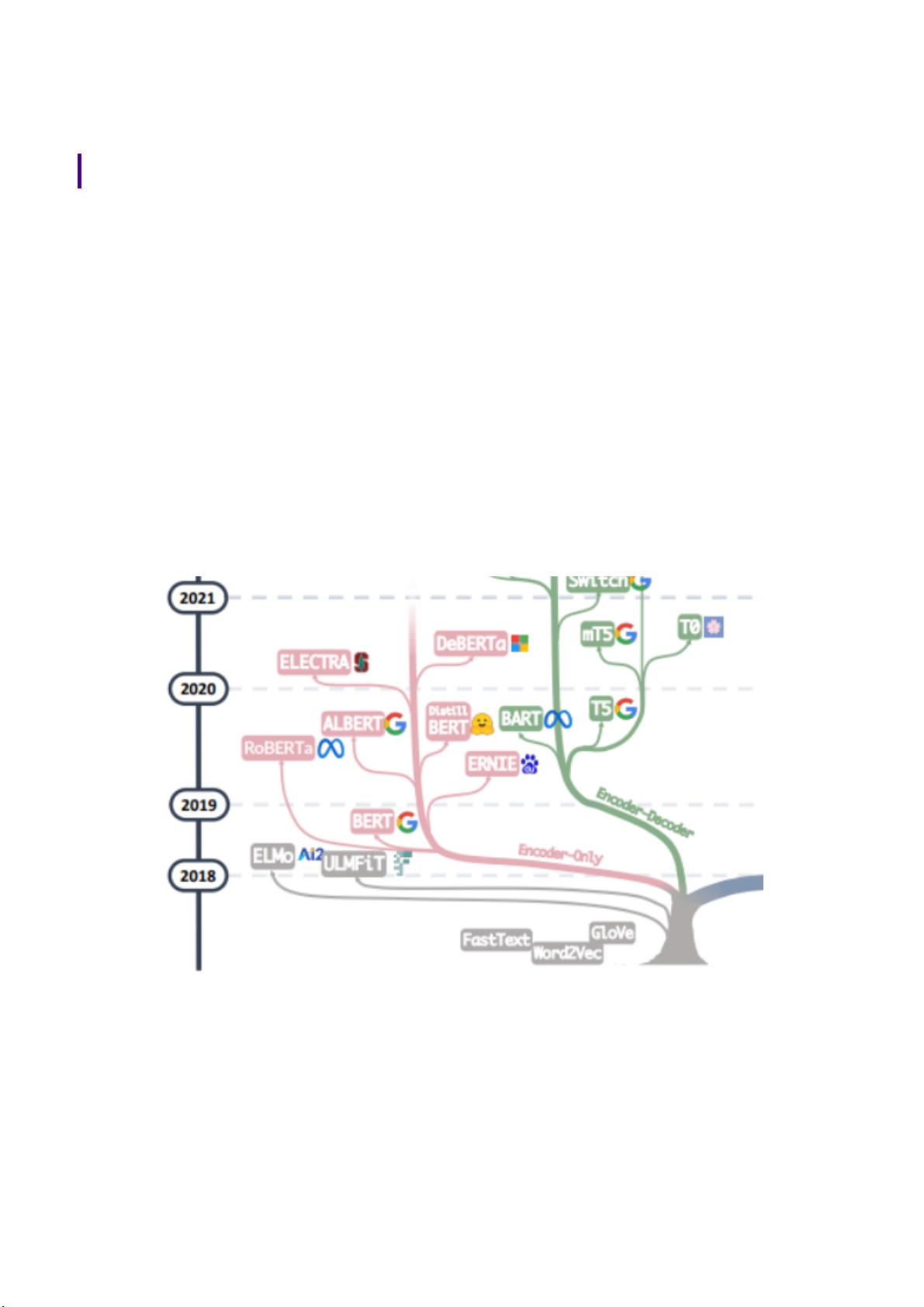
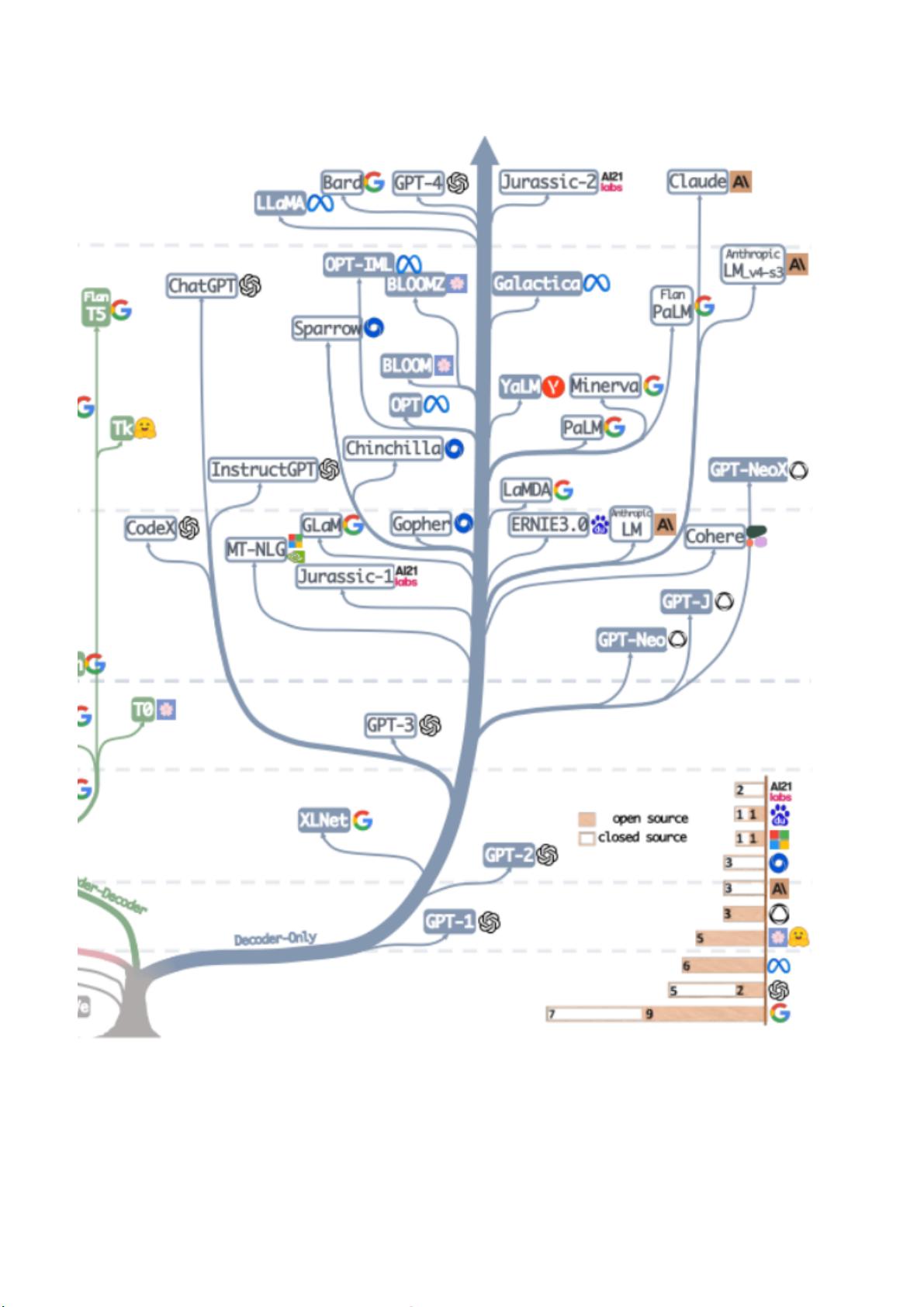
andBeyond》,为我们以构建一颗“ 家谱树”的方式梳理了以 ChatGPT 为代表的大模型的前世
今生与未来,并且从任务出发,为我们搭建了非常全面的大模型实用指南,为我们介绍了大模
型在不同任务中的优缺点,最后还指出了大模型目前的风险与挑战。
论 文 题 目 :
Harnessing thePowerof LLMsin Practice: A Surveyo n ChatGPT and Beyond
论 文 链 接 :
https://arxiv .org/pdf/2304.13712.pdf
小戏,Python 2023-05-16 12:05 发表于四川
原创
夕小瑶科技说