数据仓库开发模型是构建高效、适应性强的数据分析平台的关键步骤。这一过程涉及到从现实世界的复杂情况抽象到适合计算机处理的概念、逻辑和物理模型。在数据仓库(DW)的开发中,模型扮演着至关重要的角色,它们帮助开发者理解和转化用户需求,同时确保系统能够随着需求变化而灵活调整。
我们要理解数据模型的层次。概念模型是描述真实世界中问题领域的事物,包括记号、内涵和外延,通常通过改进的E-R图来表示。E-R图在数据仓库构建中尤其有用,因为它允许与业务处理系统保持一致,同时强调DW的独特性质。在DW中,E-R图被扩展为三层:高层模型(E-R图)、逻辑层和物理层。然而,与业务处理系统不同,DW不包含实时操作数据,而是侧重于分析数据、描述数据和细节数据。
逻辑模型进一步细化了概念模型,为物理实现做准备。在DW中,数据类型有别于操作型系统,它包含了历史数据和衍生数据,以反映业务的演变。时间属性被纳入描述,以便分析趋势和变化。此外,数据的概括性体现在增加的衍生数据上,这在操作型系统中通常是看不到的。
接下来,我们关注物理模型,这是数据仓库的实际存储形式。为了优化性能,常常会进行反规范化处理,将多个小表合并,减少I/O操作,以提高查询效率。
在数据仓库开发模型中,元数据模型、粒度模型和聚集模型同样重要。元数据模型记录关于数据仓库本身的元数据,如数据源、转换规则和业务含义,它是管理和理解DW的关键。粒度模型定义了数据的详细程度,决定了数据如何被细分和聚合。聚集模型则涉及数据的汇总方式,它影响查询性能和分析的灵活性。
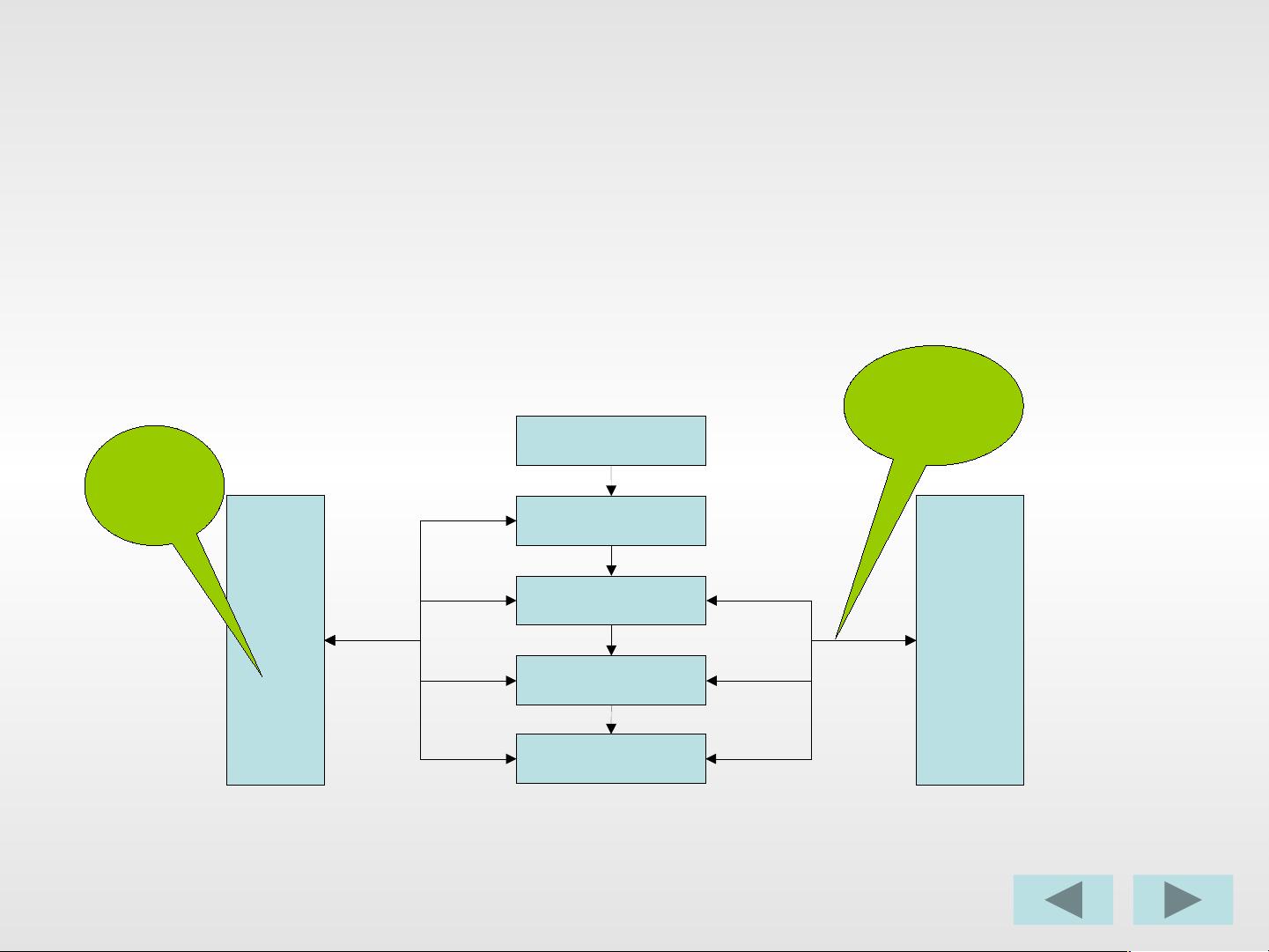
粒度模型是DW的灵魂,因为它决定了数据仓库的结构和性能。数据仓库通常包含指标实体、维实体和详细类别实体。指标实体是分析的核心,包含业务关键指标;维实体提供了过滤和组织数据的框架;详细类别实体则提供更深入的分析数据。这三个实体共同作用,支持了数据仓库的高效查询和深度分析。
数据仓库开发模型是一个多层次、综合性的过程,涉及到从现实世界到计算机世界的转化,并且需要根据业务需求和性能优化进行不断的调整和改进。通过概念模型、逻辑模型、物理模型、元数据模型、粒度模型和聚集模型的协同工作,数据仓库能够提供强大的分析能力,支持企业决策和业务洞察。