






Modified Sub space Algorithms for
D oA Es tima tion With Larg e Ar rays
X. Mestre, M.A. Lagunas
Publication: IEEE Transactiosns on Signal Processing
Vol.: 56
No.: 2
Date: February 2008
This publication has been included here just to fac ilitate downloads to those people asking for
personal use copies. This material may be published at copyrighted journals or conference pro-
ceedings, so personal use of the download is required. In particular, publications from IEEE
have to be downloaded according to the following IEEE note:
c
°2008 IEEE. Personal use of this material is permitted. However, permission to reprint/republish
this material for advertising or promotional purposes or for creating new collective works for
resale or redistribution to servers or lists, or to reuse any copyrighted component of this work
in other works m u st be obtained from the IEEE.

598 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 56, NO. 2, FEBRUARY 2008
Modified Subspace Algorithms for DoA
Estimation With Large Arrays
Xavier Mestre, Member, IEEE, and Miguel Ángel Lagunas, Fellow, IEEE
Abstract—This paper proposes the use of a new generalized
asymptotic paradigm in order to analyze the performance of sub-
space-based direction-of-arrival (DoA) estimation in array signal
processing applications. Instead of assuming that the number of
samples is high whereas the number of sensors/antennas remains
fixed, the asymptotic situation analyzed herein assumes that both
quantities tent to infinity at the same rate. This asymptotic situa-
tion provides a more accurate description of a potential situation
where these two quantities are finite and hence comparable in
magnitude. It is first shown that both MUSIC and SSMUSIC
are inconsistent when the number of antennas/sensors increases
without bound at the same rate as the sample size. This is done
by analyzing and deriving closed-form expressions for the two
corresponding asymptotic cost functions. By examining these
asymptotic cost functions, one can establish the minimum number
of samples per antenna needed to resolve closely spaced sources
in this asymptotic regime. Next, two alternative estimators are
constructed, that are strongly consistent in the new asymptotic
situation, i.e., they provide consistent DoA estimates, not only
when the number of snapshots goes to infinity, but also when the
number of sensors/antennas increases without bound at the same
rate. These estimators are inspired by the theory of G-estimation
and are therefore referred to as G-MUSIC and G-SSMUSIC,
respectively. Simulations show that the proposed algorithms
outperform their traditional counterparts in finite sample-size
situations, although they still present certain limitations.
Index Terms—Direction-of-arrival (DoA) estimation, G-estima-
tion, MUSIC, random matrix theory, SSMUSIC.
I. INTRODUCTION
M
ANY applications in array signal processing require the
determination of the direction of arrival (DoA) of dif-
ferent sources impinging from distinct directions on an array
of spatially distributed sensors or antennas. A vast number of
DoA estimation methods have been proposed and analyzed in
the literature. Among them, subspace-based algorithms, also re-
ferred to as super-resolution techniques, offer a good compro-
mise between resolution and computational complexity. They
Manuscript received October 16, 2006; revised June 19, 2007. The associate
editor coordinating the review of this manuscript and approving it for publica-
tion was Prof. Zhengyuan Xu. This work was partially supported by the Catalan
Government under Grant SGR2005-00690 and the European Commission under
project 6FP IST 26957. Part of the material in this paper has been presented at
the IEEE International Conference on Acoustics, Speech and Signal Processing,
Toulouse, France, May 14–19, 2006, and at the Adaptive Sensor Array Pro-
cessing Workshop, Lexington, MA, June 6–7, 2006.
The authors are with the Centre Tecnològic de Telecomunicacions de
Catalunya, 08860 Castelldefels, Barcelona, Spain (e-mail: xavier.mestre@cttc.
cat; m.a.lagunas@cttc.cs).
Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TSP.2007.907884
do not require extensive multidimensional search, and still can
provide a reasonably good performance. On the downside, these
algorithms suffer from the well-known threshold effect [1], [2],
meaning that the performance of these algorithms rapidly breaks
down when either the number of samples or the signal-to-noise
ratio (SNR) fall below a certain threshold. This threshold effect
is less relevant in multidimensional search algorithms such as
maximum likelihood (ML), where the performance breakdown
occurs at much lower values of the sample size and/or the signal
to noise ratio, usually far below the performance threshold as-
sociated with the estimation of the number of sources in the sce-
nario via information theoretic criteria [3].
In this paper, we concentrate on two different subspace-based
techniques for DoA detection in array processing applications:
the “Multiple-SIgnal Classification” (MUSIC) algorithm [4],
[27] and the “Signal subspace Scaled MUSIC” (SSMUSIC)
technique [5], which is a modified MUSIC algorithm especially
suitable for low sample-size situations. The performance of the
MUSIC algorithm has received a lot of attention in the past
[see, e.g., [6]–[12] (this list does not intend to be exhaustive)].
The performance of the SSMUSIC approach, on the contrary,
has received significantly less attention. Most of the perfor-
mance analyses are asymptotic in the number of snapshots,
assuming that the number of array elements remains fixed. As
a consequence, these studies are not very appropriate in order
to characterize the performance of the algorithms in a finite
sample-size situation.
In this paper, we take another approach to the performance
assessment of these subspace-based DoA detection algorithms.
Our approach is also asymptotic, but more representative of
the finite sample-size regime than previous asymptotic studies.
Indeed, we consider the asymptotic situation where both the
number of snapshots and the number of sensors/antennas are
high, but are comparable in magnitude. This type of asymp-
totic analysis, which is based on random matrix theory, gen-
eralizes traditional asymptotic assumptions (which can be re-
covered as a special case of the analysis provided here) and
leads to a more generic description of a reality where these two
quantities are finite and are comparable in magnitude. More pre-
cisely, we will be able to characterize the effect of the number
of samples per antenna on the resolution capabilities of sub-
space-based algorithms using only first-order approximations
(in classical asymptotics, this effect can only be characterized
with at least second-order approximations). Using the same type
of technique, we are able to propose two alternatives to the clas-
sical MUSIC and SSMUSIC estimators that are consistent under
more generic conditions. Contrary to the classical approaches,
where an objective cost function is simply estimated by an ob-
servation-based function that is consistent when the sample size
1053-587X/$25.00 © 2007 IEEE

MESTRE AND LAGUNAS: MODIFIED SUBSPACE ALGORITHMS FOR DOA ESTIMATION WITH LARGE ARRAYS 599
tends to infinity, the new estimators are designed to be also con-
sistent when the number of array elements increases to infinity
with the sample size. In general terms, this provides better prop-
erties to the estimators in the nonasymptotic regime because
consistency is guaranteed under more generic conditions.
The rest of the paper is organized as follows. Section II
introduces the signal model, as well as the MUSIC and SS-
MUSIC techniques for DoA estimation of multiple sources
impinging on an array of sensors/antennas. Section III re-
views some basic results on the asymptotic behavior of the
eigenvalues of sample covariance matrices that are used in this
paper. Section IV presents two asymptotic expressions for the
MUSIC and SSMUSIC cost functions when both the number
of snapshots and the number of array elements tend to infinity
at the same rate, proving inconsistency of both MUSIC and
SSMUSIC in this asymptotic regime. Section V introduces
two alternative estimators that achieve consistency in this new
asymptotic situation. Finally, Section VI presents a numerical
evaluation comparing the performance of the traditional and
proposed DoA detection algorithms, and Section VII concludes
the paper. All the technical derivations have been relegated to
the appendices.
II. S
IGNAL MODEL AND
CLASSICAL APPROACHES
Let us consider a collection of
complex-valued array ob-
servations,
obtained from an array
of
elements. We consider the case where the array is re-
ceiving the signal from
different sources, , in white
noise. In this case, the observations can be modeled to be inde-
pendent, identically distributed (i.i.d.) random vectors with zero
mean and covariance
(1)
where
is an matrix that contains the
steering vectors corresponding to the
different sources,
(2)
is a source correlation matrix, and is the noise
power. Without loss of generality we normalize the signature of
the array manifold so that
for all . The problem
of DoA detection can be stated as follows. Assuming that we
know the number of sources in the scenario
and the array
manifold
and that we do not have access to or ,
determine the DoAs
, from the collection of observa-
tions
.
Now, let
and
denote the eigenvectors and associated eigenvalues of the true
covariance matrix of the observations. Each eigenvalue is re-
peated according to its multiplicity, and the eigenvectors asso-
ciated with eigenvalues of multiplicity higher than one are taken
to be an arbitrary orthonormal basis of the associated subspace.
According to the structure of the covariance matrix in (1), the
smallest eigenvalue has multiplicity
and is exactly equal
to the noise power, namely
. Hence,
we can express the true covariance matrix as
(3)
where
is a diagonal matrix containing the largest
eigenvalues of
is an matrix that contains the
eigenvectors corresponding to the
largest eigenvalues, and
is an matrix that contains the eigenvectors as-
sociated with the smallest eigenvalue
. Now, the eigenvalues
and eigenvectors of the correlation matrix
can be split into
two sets that generate independent linear spaces: the signal sub-
space, generated by the columns of
, and the noise subspace,
generated by the columns of
.
Subspace identification algorithms are based on the property
that any vector lying on the signal subspace is orthogonal to the
columns of
. In our case, we will have
(4)
for any
. This rapidly suggests the idea behind the
MUSIC approach: we can find
as the values
of
such that the column vector lies on the signal subspace
of
or, equivalently, the values of such that
(5)
In practice, though, the eigenvectors
are not known, and
must be estimated from the received data. Let
represent the
sample covariance matrix drawn from
samples or snapshots,
i.e.,
(6)
We will denote by and
the eigenvectors and associated eigenvalues of the sample
covariance matrix
(they will be referred to as sample eigen-
vectors and sample eigenvalues respectively). The MUSIC al-
gorithm follows from the approach described above, replacing
the unknown matrix of the true noise eigenvectors
with its
sample estimate, namely
(7)
so that the left-hand side of (5) is estimated as
(8)
where we made explicit the fact that it is constructed from a set
samples and sensors/antennas. Of course, the cost func-
tion
does not need to be zero anywhere, so that the

600 IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 56, NO. 2, FEBRUARY 2008
estimated DoAs are selected as the deepest
local minima [4], [13], [27]. When the number of samples in-
creases without bound
and the observation dimen-
sion is taken to be a fixed quantity
tends
almost surely to the deterministic original objective function
. If this convergence is uniform in , one can
ensure that the estimates obtained are consistent as
. In practice, however, the number of samples is
finite and its magnitude is comparable to the observation dimen-
sion
. Therefore, it seems more natural to investigate the
performance of the MUSIC algorithm whenever
are also
comparable in magnitude. This issue has been less studied in the
literature, mainly due to the high complexity involved. However,
a lot of insight can be gained by analyzing the asymptotic be-
havior of the objective function in (8) when
for
. Note that this is a good approximation
of reality, in the sense that
are comparable in magnitude as
in a practical situation. In order to carry out such bidimensional
limits, one must resort to random matrix theory techniques.
A similar DoA estimation approach has been presented in [5]
under the name of SSMUSIC, which has been shown to outper-
form traditional MUSIC in the finite sample-size regime. The
SSMUSIC algorithm is derived by considering the following
identity (see further [5]), which holds whenever the source cor-
relation matrix
is diagonal (uncorrelated sources):
#
(9)
Here,
is the signal-part
of the true covariance matrix,
#
denotes the Moore–Penrose
pseudoinverse and
are the following oblique pro-
jection matrices:
#
#
(10)
Now, when
is a true direction of ar-
rival of one of the sources in the scenario, and hence
belongs to the column space of turns out
to be the oblique projection matrix with range space generated
by
and null space generated by the rest of the columns
of
. Correspondingly, is equal to the complemen-
tary projection, and consequently
accepts the decomposi-
tion
, meaning
that the second term on the right hand side of (9) must be equal
to zero. The SSMUSIC algorithm is based on a search for the
values of
for which the trace of the second term on the right-
hand side of (9) is equal to zero, namely
#
(11)
On the other hand, using the eigendecomposition of
, we can express
#
(12)
Now, in practice the true covariance matrix is unknown, and
is replaced by its corresponding sample estimate. Hence, the
SSMUSIC algorithm selects the estimated DoAs as the highest
local maxima of the objective function
(13)
where
.
.
.
(14)
and
(15)
The objective of this paper is to establish the inconsistency
of both
and as estimators of the cor-
responding objective functions when
at the same
rate. Then, we will propose two equivalent estimators that are
strongly consistent under these generalized asymptotic condi-
tions. The tools to derive these results are based on random ma-
trix theory and the asymptotic description of the eigenvalues of
sample covariance matrix as
at the same rate. We
introduce these concepts in the following section.
III. A
SYMPTOTIC DESCRIPTION OF THE
EIGENVALUES AND
EIGENVECTORS OF
Random matrix theory is a branch of statistics that is devoted
to the study of the asymptotic behavior of the eigenvalues and
eigenvectors of some random matrix models when the dimen-
sions of the matrices increase without bound at the same rate.
In particular, using random matrix theory we can show that,
under some technical assumptions, the distribution of eigen-
values of
tends to a compactly supported nonrandom mea-
sure. More specifically, consider the empirical distribution func-
tion of the eigenvalues of
for a fixed number of array elements
, namely
# (16)
where #
denotes the cardinality of a set. is an eigen-
value counting function that, for each
, returns the proportion
of sample eigenvalues that are lower than or equal to
. Note that
this is a random function, because
are also random. Now, it
turns out that, under some statistical assumptions that will be
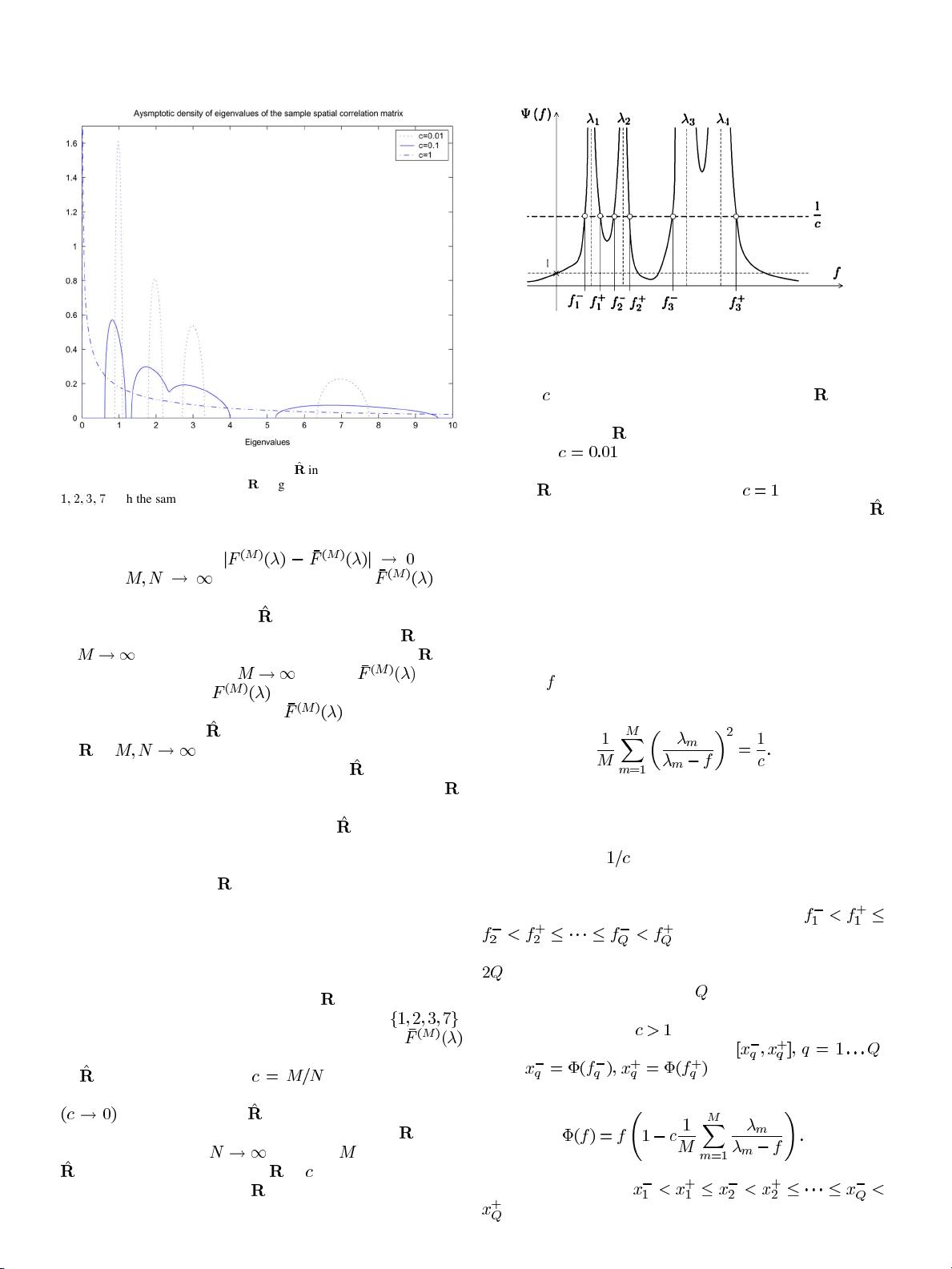
MESTRE AND LAGUNAS: MODIFIED SUBSPACE ALGORITHMS FOR DOA ESTIMATION WITH LARGE ARRAYS 601
Fig. 1. Asymptotic eigenvaluedistribution of
^
R
in a situation where the asymp-
totic distribution of eigenvalues of
R
is given by four different eigenvalues
1
;
2
;
3
;
7
with the same multiplicity.
specified in Section IV, almost
surely as
at the same rate. Here, is a
deterministic distribution function that gives an asymptotic de-
scription of the eigenvalues of
. We remark here that this de-
scription is valid regardless of how the eigenvalues of
behave
as
, i.e., the empirical eigenvalue distribution of may
not converge to anything as
but, still, will be
asymptotically close to
in that asymptotic regime.
Now, by examining the form of
, one can conclude
that the eigenvalues of
tend to cluster around the eigenvalues
of
as at the same rate. This way, one can think
of the asymptotic eigenvalue distribution of
as a collection
of clusters, each one centered at a different eigenvalue of
.
The size of the support of these clusters depends on the number
of samples per sensor/antenna from which
is constructed. If
the number of samples per sensor/antenna is low, the support of
each cluster will be large, implying that clusters associated with
different eigenvalues of
may merge. If, on the contrary, the
number of samples per sensor/antenna is high, each eigenvalue
will be associated with a different cluster, separated from the
rest of the sample eigenvalue distribution.
Example 1: In order to fix ideas, we will consider a partic-
ular example. Assume that the asymptotic eigenvalue distribu-
tion of the true spatial correlation matrix
is given by four dif-
ferent eigenvalues with equal multiplicity, namely
.
In Fig. 1, we represent the density associated with
(which describes the asymptotic behavior of the eigenvalues
of
) for different values of . Observe that, as the
number of samples increases in terms of the number of antennas
, the eigenvalues of tend to concentrate around the
four eigenvalues of the true spatial correlation matrix
. This is
reasonable, because as
with fixed , the elements of
tend almost surely to those of .If is sufficiently low, or if
the asymptotic eigenvalues of
are sufficiently separated, each
asymptotic eigenvalue generates a different cluster. If, on the
Fig. 2. Typical representation of the function on the left-hand side of (17).
contrary, is high or the asymptotic eigenvalues of are very
close to one another, one cluster can contain multiple asymp-
totic eigenvalues of
. In the example we are considering, we
see that for
(100 samples per array element), we can
clearly distinguish a different cluster for each asymptotic eigen-
value of
. However, for the case where (one sample per
array element) the asymptotic distribution of eigenvalues of
is concentrated in a single cluster.
The number and position of the different clusters in the
asymptotic distribution of eigenvalues of sample covari-
ance matrices has been studied by several authors (see, e.g.,
[14]–[16]). In [17], we re-derive the characterization of the
position of the connected components (or clusters) of the
asymptotic eigenvalue distribution given in [14], which can be
summarized as follows. Consider the following equation in the
unknown
:
(17)
In Fig. 2, we give a typical representation of the function on the
left-hand side of the above equation. The solutions of the equa-
tion can be graphically represented as the crossing points with
a horizontal line at
. It is formally shown in [17] that, as il-
lustrated in Fig. 2, the number of real-valued solutions counting
multiplicities (i.e., counting twice the roots with double multi-
plicity) is always even and they can be ordered as
, where equality is understood to
hold when there exists a solution with double multiplicity (here,
is the total number of real-valued solutions counting multi-
plicities). Now, it turns out that
is the number of different
clusters of the asymptotic distribution of eigenvalues, excluding
atoms at zero whenever
. Moreover, each of these clusters
is supported by an interval of the type
,
where
and
(18)
It is shown in [17] that
, so we can express the support of the asymptotic eigenvalue















