Introduction to Intel AVX
需积分: 10 34 浏览量
2018-07-23
16:28:23
上传
评论
收藏 1.44MB PDF 举报


Introduction to Intel® Advanced Vector Extensions
By Chris Lomont
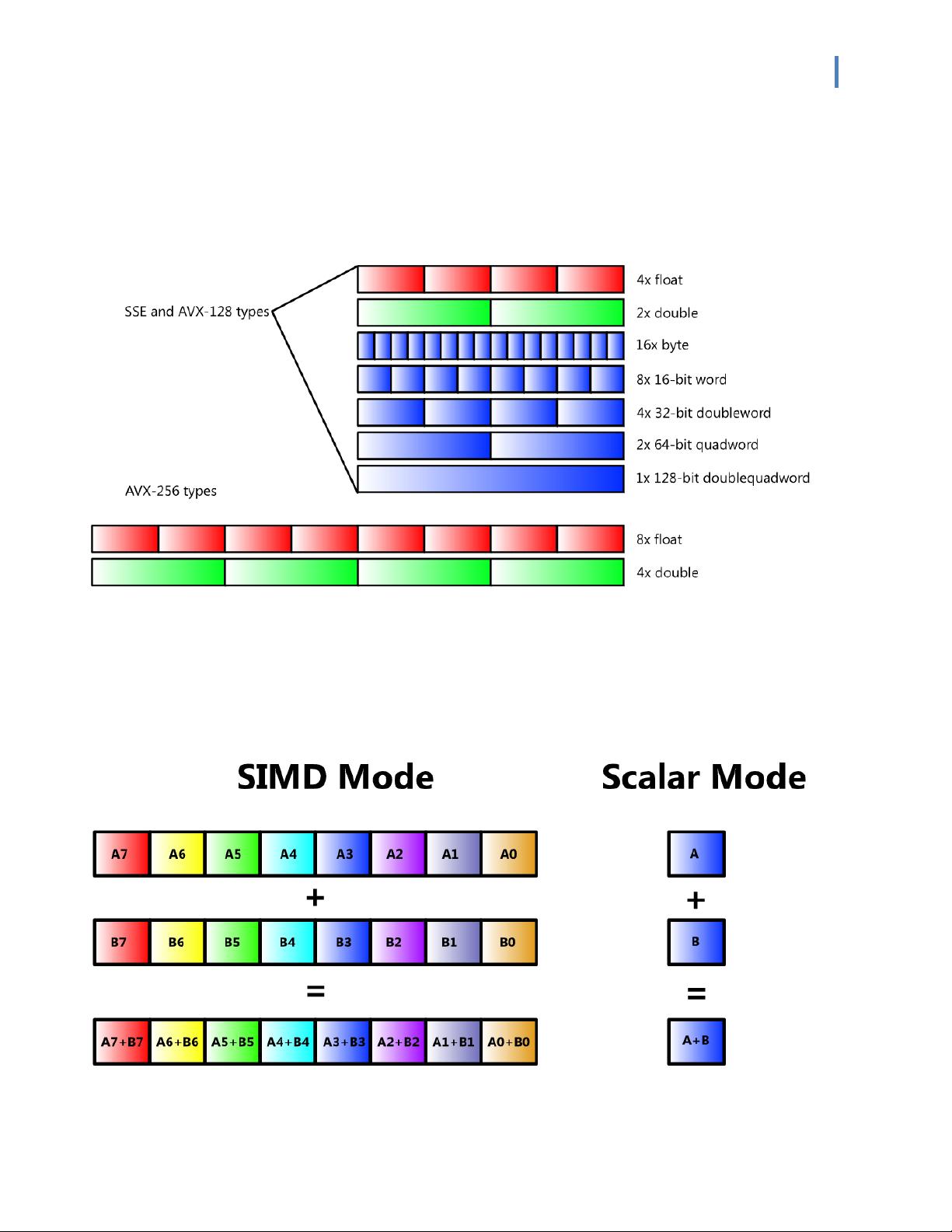
Intel® Advanced Vector Extensions (Intel® AVX) is a set of instructions for doing Single
Instruction Multiple Data (SIMD) operations on Intel® architecture CPUs. These instructions
extend previous SIMD offerings (MMX™ instructions and Intel® Streaming SIMD Extensions
(Intel® SSE)) by adding the following new features:
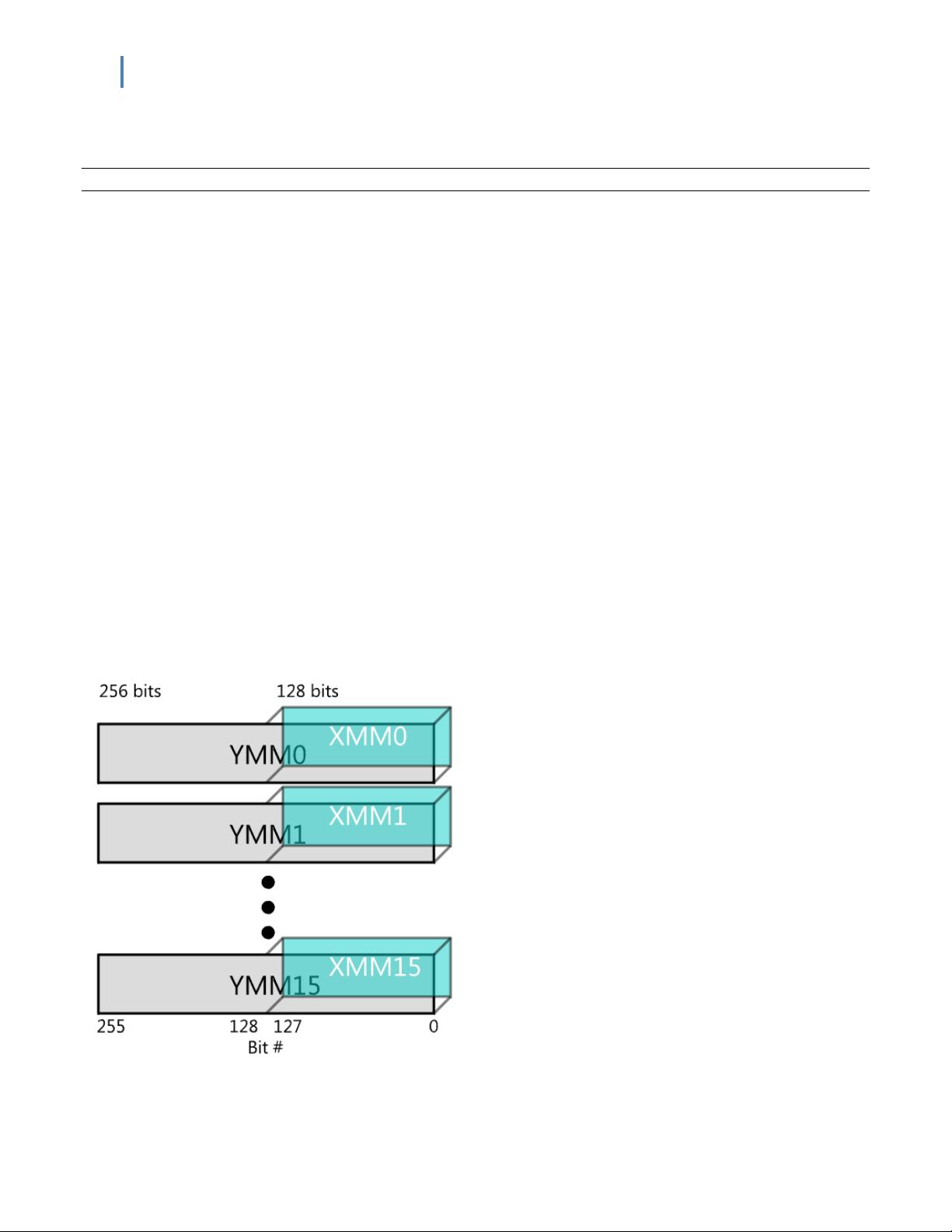
The 128-bit SIMD registers have been expanded to 256 bits. Intel® AVX is designed to
support 512 or 1024 bits in the future.
Three-operand, nondestructive operations have been added. Previous two-operand
instructions performed operations such as A = A + B, which overwrites a source operand;
the new operands can perform operations like A = B + C, leaving the original source
operands unchanged.
A few instructions take four-register operands, allowing smaller and faster code by
removing unnecessary instructions.
Memory alignment requirements for operands are relaxed.
A new extension coding scheme (VEX) has been designed to make future additions easier
as well as making coding of instructions smaller and faster to execute.
Closely related to these advances are the new Fused–Multiply–Add (FMA) instructions, which
allow faster and more accurate specialized operations such as single instruction A = A * B + C. The
FMA instructions should be available in the second-generation Intel® Core™ CPU. Other features
include new instructions for dealing with Advanced Encryption Standard (AES) encryption and
decryption, a packed carry-less multiplication operation (PCLMULQDQ) useful for certain
encryption primitives, and some reserved slots for future instructions, such as a hardware random
number generator.
Instruction Set Overview
The new instructions are encoded using what Intel calls a VEX prefix, which is a two- or three-byte
prefix designed to clean up the complexity of current and future x86/x64 instruction encoding.
The two new VEX prefixes are formed from two obsolete 32-bit instructions—Load Pointer Using
DS (LDS—0xC4, 3-byte form) and Load Pointer Using ES (LES—0xC5, two-byte form)—which load
the DS and ES segment registers in 32-bit mode. In 64-bit mode, opcodes LDS and LES generate an
invalid-opcode exception, but under Intel® AVX, these opcodes are repurposed for encoding new
instruction prefixes. As a result, the VEX instructions can only be used when running in 64-bit
mode. The prefixes allow encoding more registers than previous x86 instructions and are required
for accessing the new 256-bit SIMD registers or using the three- and four-operand syntax. As a
user, you do not need to worry about this (unless you’re writing assemblers or disassemblers).


剩余20页未读,继续阅读
资源评论


Dgelom
- 粉丝: 0
- 资源: 3









最新资源
- ### 1、项目介绍 本项目Scrapy进行数据爬取,并使用Django框架+PyEcharts实现可视化大屏 效果如下:
- # 微信小程序-健康菜谱 基于微信小程序的一个查找检索菜谱的应用 ### 效果 !动态图(./res/gif/demo
- zabbix-get命令包资源
- 毕业设计,基于PyQt5实现的可视化界面的Python车牌自动识别系统源码
- 26-朴素贝叶斯分类.rar
- 没有安Matlab 也可以 生成FIR抽头系数工具.py
- python烟花代码.rar
- 实验目的: 1.构建基于verilog语言的组合逻辑电路和时序逻辑电路; 2.掌握verilog语言的电路设计技巧 3.完成如
- 扩展卡尔曼滤波matlab仿真
- 3_base.apk.1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


