
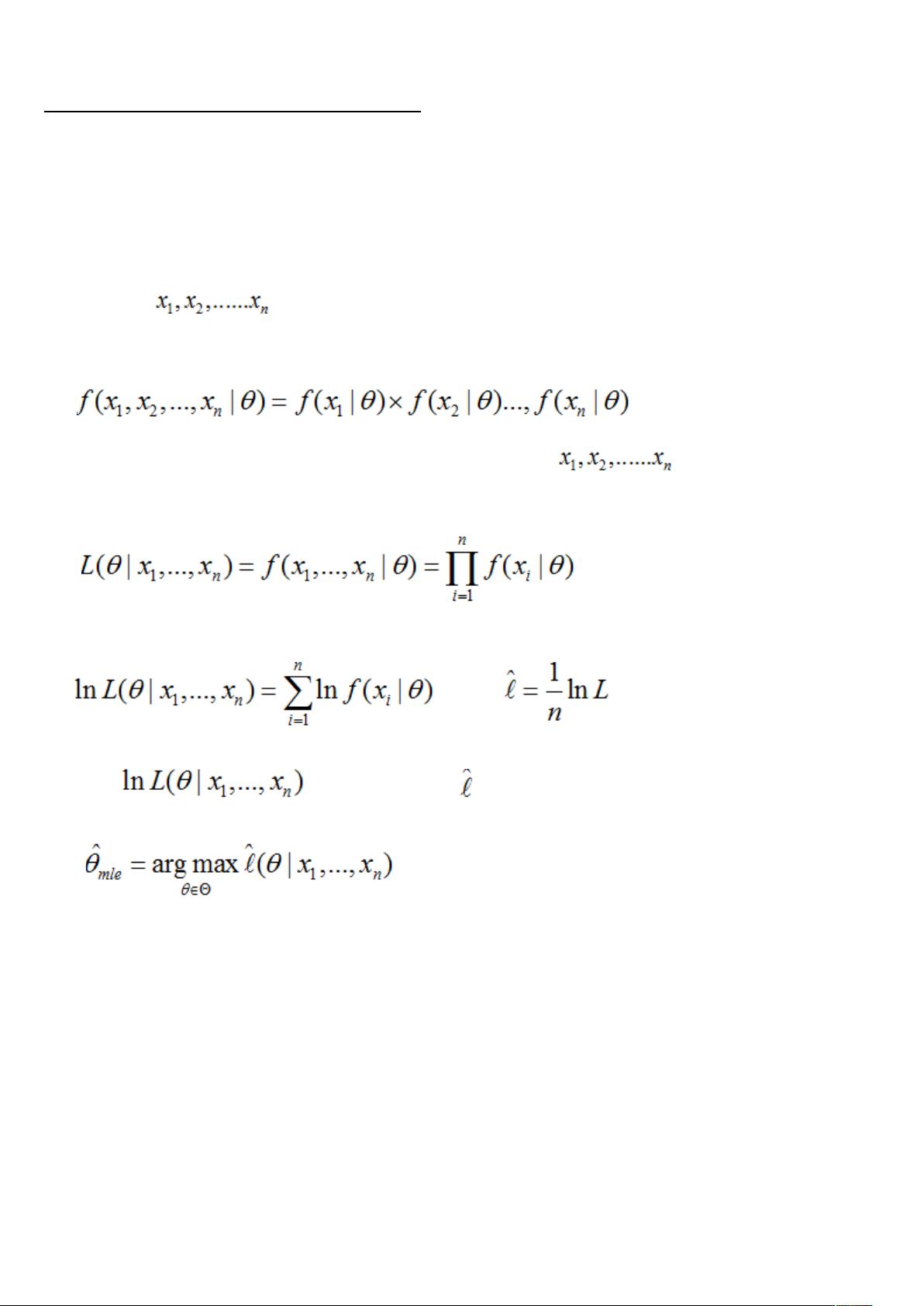
最大似然估计 (Maximum likelihood estimation)
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。简单而
言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方
差未知。我们没有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然
后通过最大似然估计来获取上述假设中的正态分布的均值与方差。
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。下面我们具体
描述一下最大似然估计:
首先,假设 为独立同分布的采样,θ 为模型参数,f 为我们所使用的模型,遵循我们上述
的独立同分布假设。参数为 θ 的模型 f 产生上述采样可表示为
回到上面的“模型已定,参数未知”的说法,此时,我们已知的为 ,未知为 θ,故似然定义
为:
在实际应用中常用的是两边取对数,得到公式如下:
其中 称为对数似然,而 称为平均对数似然。而我们平时所称的最大似然
为最大的对数平均似然,即:
举个别人博客中的例子,假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的
比例也不知。我 们想知道罐中白球和黑球的比例,但我们不能把罐中的球全部拿出来数。现在我们可
以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球 再放回罐中。这个过
程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,
有七十次是白球,请问罐中白球所占的比例最有可能是多少?很多人马上就有答案了:70%。而其后的
理论支撑是什么呢?
我们假设罐中白球的比例是 p,那么黑球的比例就是 1-p。因为每抽一个球出来,在记录颜色之后,
我们把抽出的球放回了罐中并摇匀,所以每次抽出来的球的颜 色服从同一独立分布。这里我们把一次
抽出来球的颜色称为一次抽样。题目中在一百次抽样中,七十次是白球的概率是 P(Data | M),这里
Data 是所有的数据,M 是所给出的模型,表示每次抽出来的球是白色的概率为 p。如果第一抽样的结果
记为 x1,第二抽样的结果记为 x2... 那么 Data = (x1,x2,…,x100)。这样,
资源评论













