






一、项目介绍
项目名称:天气预测和天气可视化
天气预测和天气可视化是一个基于 python 机器学习(ml)的长春地区的天气预报
项目,它实现了天气数据的爬取,预测和可视化。
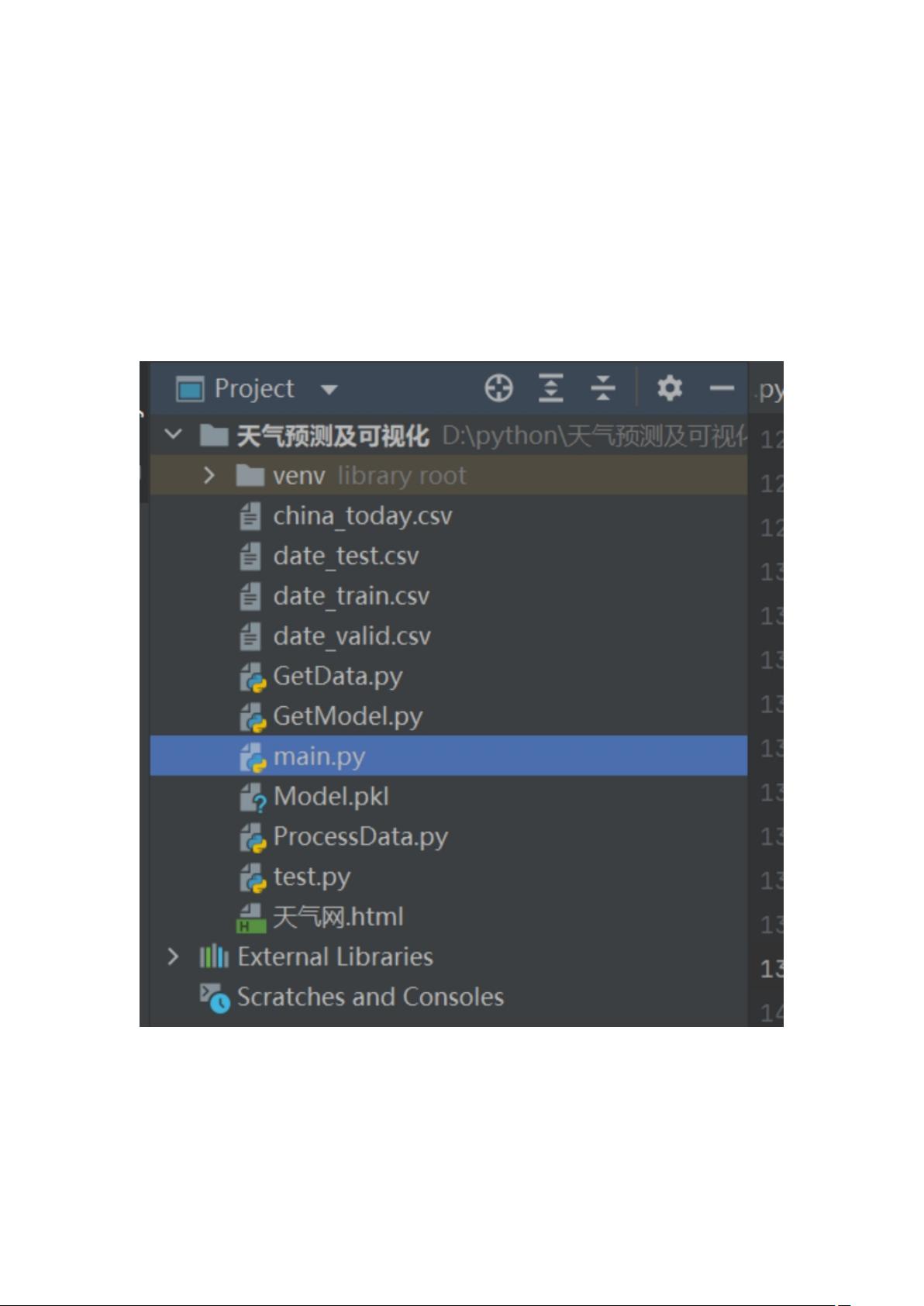
项目结构如下:
� 天气数据的来源
GetData 文件使用 python 爬虫技术,爬取长春和全国的天气信息数据
爬取网站:http://tianqi.2345.com/wea_history/54161.htm
ProcessDate 文件对爬取的天气数据进行了预处理
几个 CSV 文件保存的是爬取后并经过处理的数据
� 天气数据的预测
GetModel 文件通过训练预测模型来预测长春近一周的天气,该文件利用 Joblib
将模型保存到本地
Main 文件是项目主文件,通过运行该文件即可运行整个项目,该文件前部分获
取保存到本地的预测模型来进行预测,并将预测结果打印到控制台
� 天气数据的可视化
Main 文件后部分实现了天气数据的可视化
二、详细介绍
本项目分为三个部分,即爬取和处理数据,数据预测(包含评价方法)和数据
可视化
1. 爬取和处理数据
数据爬取代码:
resq = requests.get(url, headers=headers, params=params)
data = resq.json()["data"]
# data frame
df = pd.read_html(data)[0]
即使用 python 爬取网站的 json 数据
数据预处理:
获取到的天气信息包括最高温,最低温都不是 int 格式的数字,通过对数据截
取,将部分指标的数据变换为 int 类型
并对缺失值进行了处理
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
通过 SimpleImputer ,可以将现实数据中缺失的值通过同一列的均值、中值、
或者众数补充起来,本项目使用了 SimpleImputer 的 fit_transform 对缺失值进
行填充
2. 数据预测和模型评价方法
预测数据采用了机器学习算法——线性回归 模型使用过程:
A. 提取数据
获取测试集、训练集、验证集
[X_train, X_valid, y_train, y_valid, X_test] = ProcessData.ProcessData()
其中 ProcessData()函数里使用了如下语句:
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8,
test_size=0.2, random_state=0)
train_test_split()是 sklearn 包的 model_selection 模块中提供的随机划分训练集
和验证集的函数;使用 train_test_split 函数将完整的数据集和验证集以同等的
比例分成 2 组不同的数据集和验证集

B. 训练模型
选择了随机树森林模型(randomforest),然后用 fit 来训练模型
# 随机树森林模型
model = RandomForestRegressor(random_state=0, n_estimators=1001)
# 训练模型
model.fit(X_train, y_train)
C. 根据数据预测
# 最终预测结果
preds = model.predict(r[1])
D. 模型评价方法
# 用 MAE 评估
score = mean_absolute_error(y_valid, preds)
对于评估模型准确率的评价方法,本处使用的是 MAE,也就是
mean_absolute_error 平均绝对误差,就每个预测的数值离正确数值错误数值
的平均数
假设:
平均绝对误差(Mean Absolute Error)等于:
















