Copyright © 2016, Oracle and/or its affiliates. All rights reserved Page 2 of 26
Table of Contents
1! Introduction+...................................................................................................................................+3!
2! What+is+MySQL+Cluster?+..................................................................................................................+3!
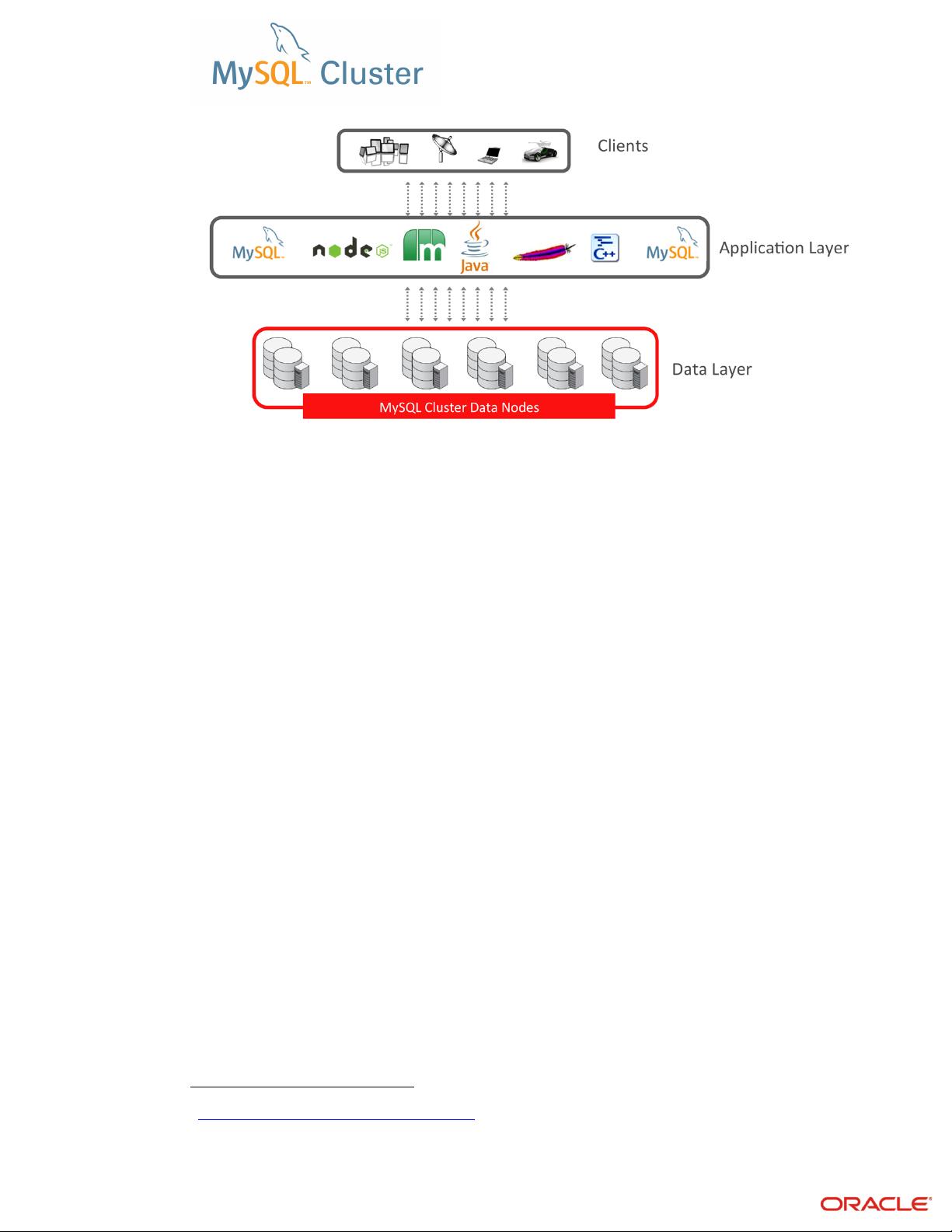
2.1! MySQL!Cluster!Architecture!.........................................................................................................................................................!3!
3! Key+New+Features+of+MySQL+Cluster+...............................................................................................+5!
4! Points+to+Consider+Before+Starting+an+Evaluation+............................................................................+6!
4.1! Will!MySQL!Cluster!“out!of!the!box”!run!an!application!faster!than!my!existing!MySQL!database?!............!6!
4.2! How!do!I!install!MySQL!Cluster?!................................................................................................................................................!6!
4.3! Does!the!database!need!to!run!on!a!particular!operating!system?!.............................................................................!7!
4.4! Will!the!entire!database!fit!in!memory?!..................................................................................................................................!7!
4.5! Does!the!application!make!use!of!complex!JOIN!operations?!........................................................................................!8!
4.6! Does!the!application!make!extensive!use!of!full!table!scans?!........................................................................................!9!
4.7! Does!the!database!require!Foreign!Keys?!..............................................................................................................................!9!
4.8! Does!the!application!require!full-text!search?!.....................................................................................................................!9!
4.9! How!will!MySQL!Cluster!perform!compared!to!other!storage!engines?!...................................................................!9!
4.10! Does!MySQL!Cluster’s!data!distribution!add!complexity!to!my!application!and!limit!the!types!of!
queries!I!can!run?!.......................................................................................................................................................................................!11!
4.11! What!does!my!application!observe!during!the!(sub-second)!failover!of!a!node?!............................................!11!
4.12! Where!does!MySQL!Cluster!sit!with!respect!to!the!CAP!(Consistency,!!Availability!&!Performance)!
Theorem?!.......................................................................................................................................................................................................!12!
5! Evaluation+Best+Practices+..............................................................................................................+12!
5.1! Hardware!............................................................................................................................................................................................!12!
5.2! Performance!metrics!.....................................................................................................................................................................!13!
5.3! Test!tools!............................................................................................................................................................................................!14!
5.4! SQL!and!NoSQL!interfaces!...........................................................................................................................................................!14!
5.5! Data!model!and!query!design!....................................................................................................................................................!15!
5.6! Using!disk!data!tables!or!in-memory!tables!........................................................................................................................!17!
5.7! User!defined!partitioning!and!distribution!awareness!..................................................................................................!17!
5.8! Parallelizing!applications!an d!o th er !tips!..............................................................................................................................!18!
6! Advice+Concerning+Configuration+Files+..........................................................................................+19!
6.1! config.ini!..............................................................................................................................................................................................!19!
6.2! my.cnf!...................................................................................................................................................................................................!20!
7! Sanity+Check+.................................................................................................................................+20!
7.1! A!few!basic!tests!to!confirm!the!Cluster!is!ready!for!testing!........................................................................................!20!
8! Troubleshooting+...........................................................................................................................+21!
8.1! Table!Full!(Memory!or!Disk)!......................................................................................................................................................!21!
8.2! Space!for!REDO!Logs!Exhausted!...............................................................................................................................................!24!
8.3! Deadlock!Timeout!...........................................................................................................................................................................!25!
8.4! Distribution!Changes!.....................................................................................................................................................................!25!
9! Conclusion+....................................................................................................................................+25!
10! Additional+Resources+..................................................................................................................+26!