

<Insert Picture Here>
<Insert Picture Here>
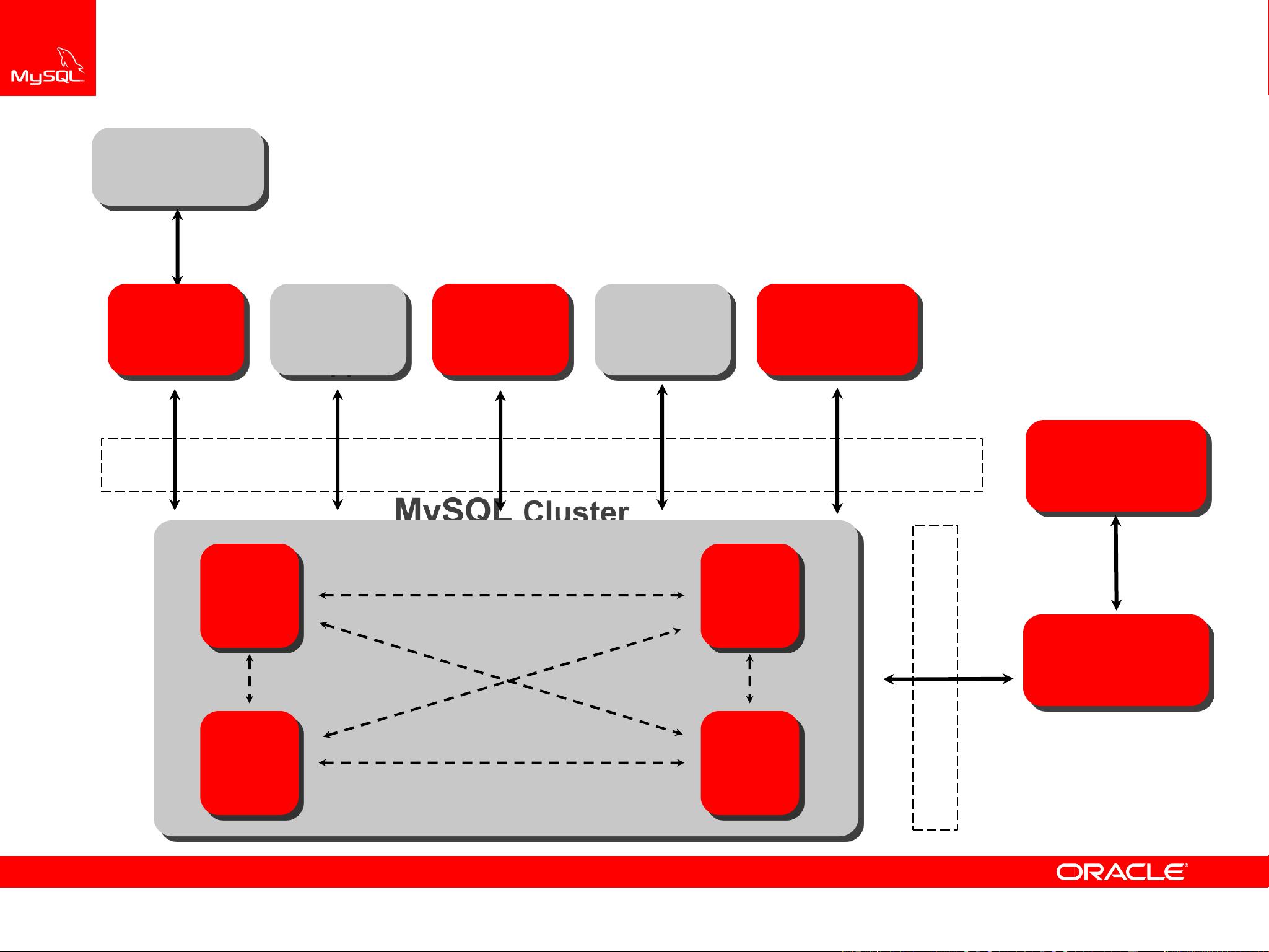
MySQL Cluster – Architecture and Internals
Massimo Brignoli
EMEA Principal Sales Consultant – MySQL


剩余110页未读,继续阅读
资源评论

 violabruce2012-06-26心里总是有一股云计算情结。
violabruce2012-06-26心里总是有一股云计算情结。

sabotageus
- 粉丝: 1
- 资源: 4









最新资源
- swift-Swift资源
- MATLAB chord chart-Matlab资源
- ToolsFx-Kotlin资源
- ChatGPT-GPTCMS-AI人工智能资源
- zino-Rust资源
- HeartRateSPO2-硬件开发资源
- gallery-移动应用开发资源
- APITable-Typescript资源
- energy-Go资源
- goploy-PHP资源
- G6-JavaScript资源
- GraduationProject-毕业设计资源
- 蓝桥杯嵌入式 停车收费系统相关代码 2021省赛-蓝桥杯资源
- control-simulation-matlab仿真资源
- cocos-cocos资源
- LingLongGUI-硬件开发资源
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


