

MySQL-Cluster 架构图文详解
1
1
1
1 / 14
14
14
14
MySQL-Cluster
MySQL-Cluster
MySQL-Cluster
MySQL-Cluster 架构图文详解
架构图文详解
架构图文详解
架构图文详解
Stan,2011/6/7
前言:
前言:
前言:
前言:
这是我第一次接触 Linux , CentOS , MySQL , 用了 5 天的时间终于将基于 CentOS5.0 系
统下 MySQL-Cluster 架构成功 , 下面将我这些经验分享给大家 。 若发现有什么错误和疏忽之
处,请发邮件给我: stan_home@qq.com 。
配置之前,先补充一些 Linux 常用命令:
ls 浏览
ls -l 查看文件夹及文件权限
vi 文本编辑器(搜索、编辑)
i 状态为修改
退出: “ Esc ” 键后,然后输入 ":", 然后输入 “ wq ” 写入、退出
:q! 强制退出
vim -f [ 文件名 ] 强制恢复文件
cp 拷贝文件命令
rm 删除文件
mkdir 创建文件夹
ln 连接问价或目录
man [ 命令 ] 查看命令参数
ifconfig 网卡信息命令
dig (域信息搜索器)
df 查看系统文件
vmstat 系统状态
ps 查看进程 (-e 显示全部, -f 全格式输出 )
ps -ef|grep mysql 查看所有 mysql 进程
Tips :输入一个文件或文件名,按一下 Tab 键,会自动完成改文件名(前提是这个文件或文
件夹必须存在 ) ;
例如:
输入
[root@localhost tmp]# tar – xzvf mysql-c
按一下 Tab 键自动完成:
[root@localhost tmp]# tar – xzvf
mysql-cluster-gpl-7.1.13-linux-i686-glibc23.tar.gz
下面,我们一起来架构吧!
一、配置环境:
一、配置环境:
一、配置环境:
一、配置环境:
OS : Linux CentOS 5.0
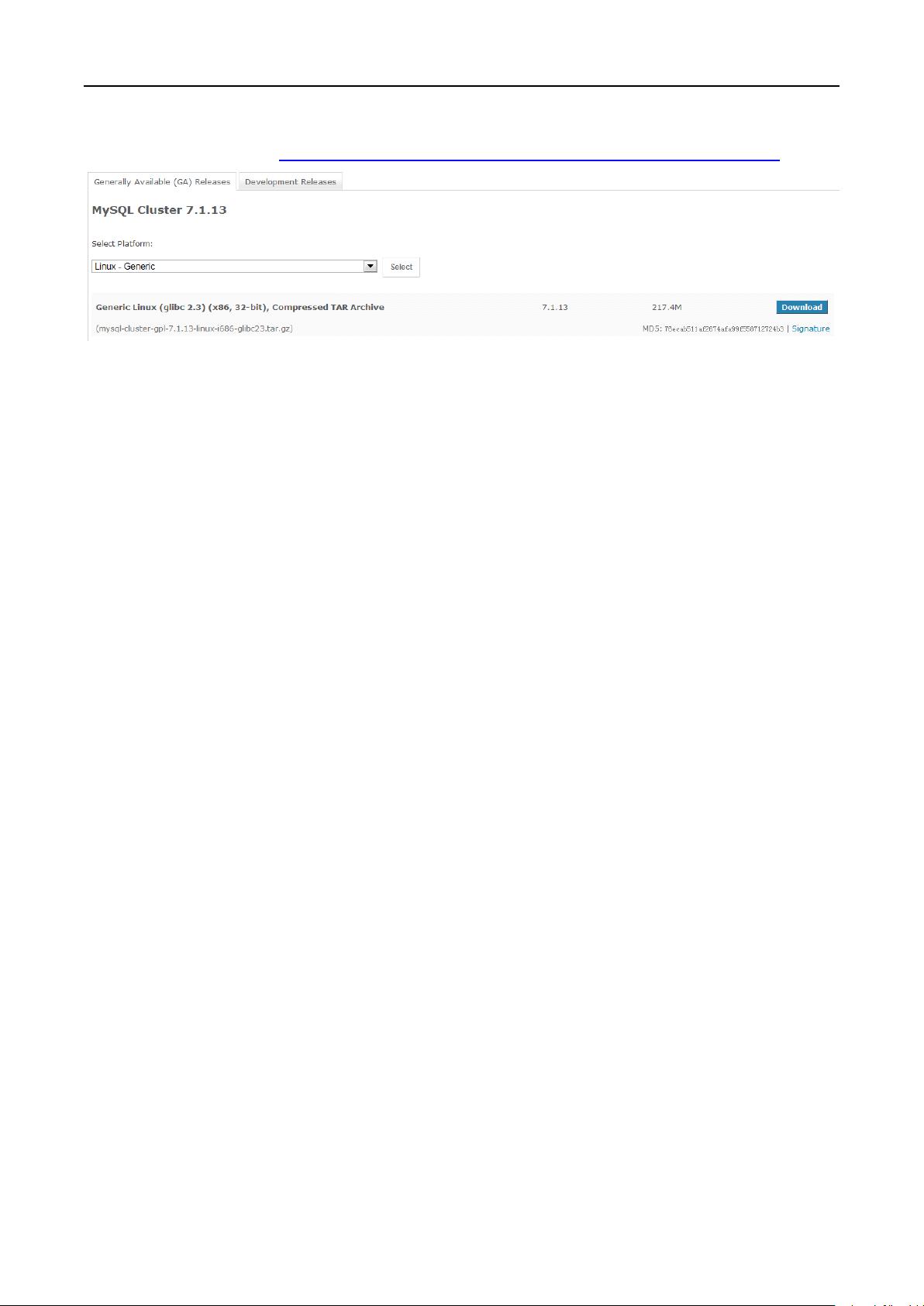
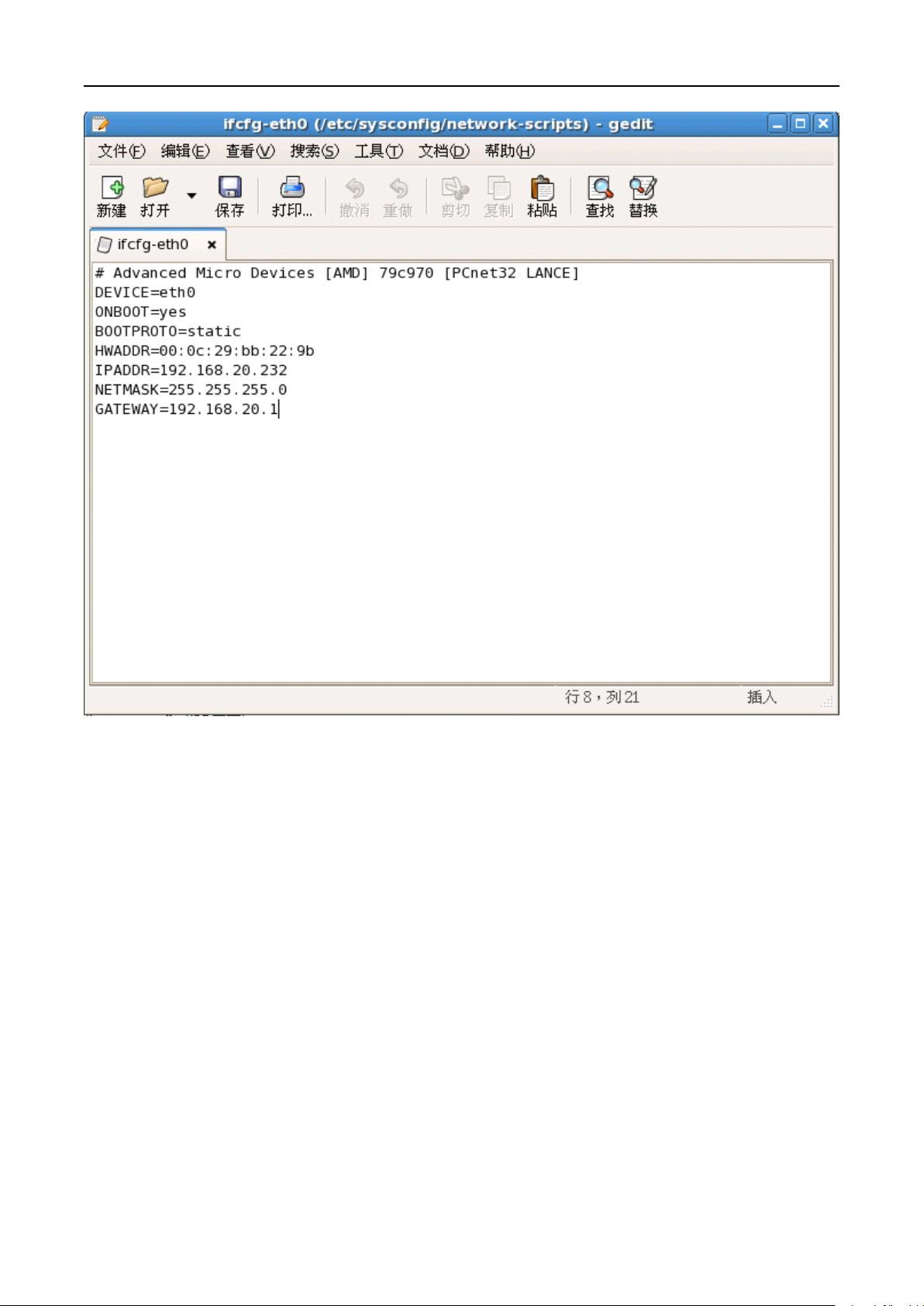
剩余13页未读,继续阅读

feihu_guest
- 粉丝: 9
- 资源: 51









最新资源
- order system final.c
- 2024注册测绘师考试讲义-大地测量与海洋测绘
- SAP ECC到SAP S4 HANA系统的对比分析(PP模块).xlsx
- Java small game (Java桌面版小游戏)
- 工程经济学自考必备软件下载
- (176647222)基于遗传算法(GA)优化门控循环单元(GA-GRU)的数据分类预测 优化参数为学习率,隐藏层节点个数,正则化参数,matla
- (176685204)基于遗传算法优化BP神经网络(GA-BP)的时间序列预测,matlab代码 模型评价指标包括:R2、MAE、MSE、RMSE
- (176724010)遗传算法(GA)优化随机森林(RF)的分类预测,GA-RF分类预测模型,多输入单输出模型 多特征输入单输出的二分类及多分类模
- 基于vc2010+easyx的贪吃蛇源码
- ieee-p1687-internal-jtag-taps-embedded-instrumentation-white-paper.pdf
- IHI0024D_amba_apb4_protocol_spec.pdf
- 2024注册测绘师《综合能力》讲义-大地测量(2)
- amba_axi4.pdf
- 2024注册测绘师《综合能力》讲义:大地测量中水准网与重力网的布设及技术规范
- 2024注册测绘师《综合能力》讲义-第2章海洋测绘(1)
- 从Python开发到打包成EXE可执行文件的辅助工具分享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
- 3
- 4
- 5
- 6
前往页