-简化的RISC CPU设计简介-
需积分: 10 161 浏览量
2014-10-31
08:37:59
上传
评论
收藏 700KB DOC 举报


可综合的VerilogHDL设计实例
---简化的RISC CPU设计简介---
前言:
在前面七章里我们已经学习了VerilogHDL的基本语法、简单组合逻辑和简单时序逻辑模块的编
写、Top-Down设计方法、还学习了可综合风格的有限状态机的设计,其中EEPROM读写器的设计
实质上是一个较复杂的嵌套的有限状态机的设计,它是根据我们完成的实际工程项目设计为教学目
的改写而来的,可以说已是真实的设计。
在这一章里, 我们将通过一个经过简化的用于教学目的的 RISC_CPU 的设计过程,来说明这种新设
计方法的潜力。这个模型实质上是第四章的RISC_CPU模型的改进。第四章中的RISC_CPU模型是
一个仿真模型,它关心的只是总体设计的合理性,它的模块中有许多是不可综合的,只可以进行仿
真。而本章中构成RISC_CPU的每一个模块不仅是可仿真的也都是可综合的,因为他们符合可综合
风格的要求。为了能在这个虚拟的CPU上运行较为复杂的程序并进行仿真, 因而把寻址空间扩大到
8K(即15位地址线)。下面让我们一步一步地来设计这样一个CPU,并进行仿真和综合,从中我
们可以体会到这种设计方法的魅力。本章中的VerilogHDL程序都是我们自己为教学目的而编写
的,全部程序在CADENCE公司的LWB (Logic Work Bench)环境下和 Mentor 公司的
ModelSim 环境下用Verilog语言进行了仿真, 通过了运行测试,并分别用Synergy和Synplify综
合器针对不同的FPGA进行了综合。分别用Xilinx和Altera公司的的布局布线工具在Xilinx3098上
和Altera Flex10K10实现了布线。 顺利通过综合前仿真、门级结构仿真以及布线后的门级仿真。
这个 CPU 模型只是一个教学模型, 设计也不一定合理, 只是从原理上说明了一个简单的RISC _CPU
的构成。我们在这里介绍它的目的是想说明:Verilog HDL仿真和综合工具的潜力和本文介绍的设
计方法对软硬件联合设计是有重要意义的。我们也希望这一章能引起对 CPU 原理和复杂数字逻辑
系统设计有兴趣的同学的注意,加入我们的设计队伍。由于我们的经验与学识有限,不足之处敬请读
者指正。
8.1.什么是CPU?
CPU 即中央处理单元的英文缩写,它是计算机的核心部件。计算机进行信息处理可分为两个步骤:
1) 将数据和程序(即指令序列)输入到计算机的存储器中。
2) 从第一条指令的地址起开始执行该程序,得到所需结果,结束运行。CPU的作用是协
调并控制计算机的各个部件执行程序的指令序列,使其有条不紊地进行。因此它必须
具有以下基本功能:
a) 取指令:当程序已在存储器中时,首先根据程序入口地址取出一条程序,为此要发
出指令地址及控制信号。
b) 分析指令:即指令译码。是对当前取得的指令进行分析,指出它要求什么操作,并
产生相应的操作控制命令。
c) 执行指令:根据分析指令时产生的“操作命令”形成相应的操作控制信号序列,通过
运算器,存储器及输入/输出设备的执行,实现每条指令的功能,其中包括对运算
结果的处理以及下条指令地址的形成。
将其功能进一步细化,可概括如下:
1) 能对指令进行译码并执行规定的动作;
2) 可以进行算术和逻辑运算;
3) 能与存储器,外设交换数据;
4) 提供整个系统所需要的控制;
171

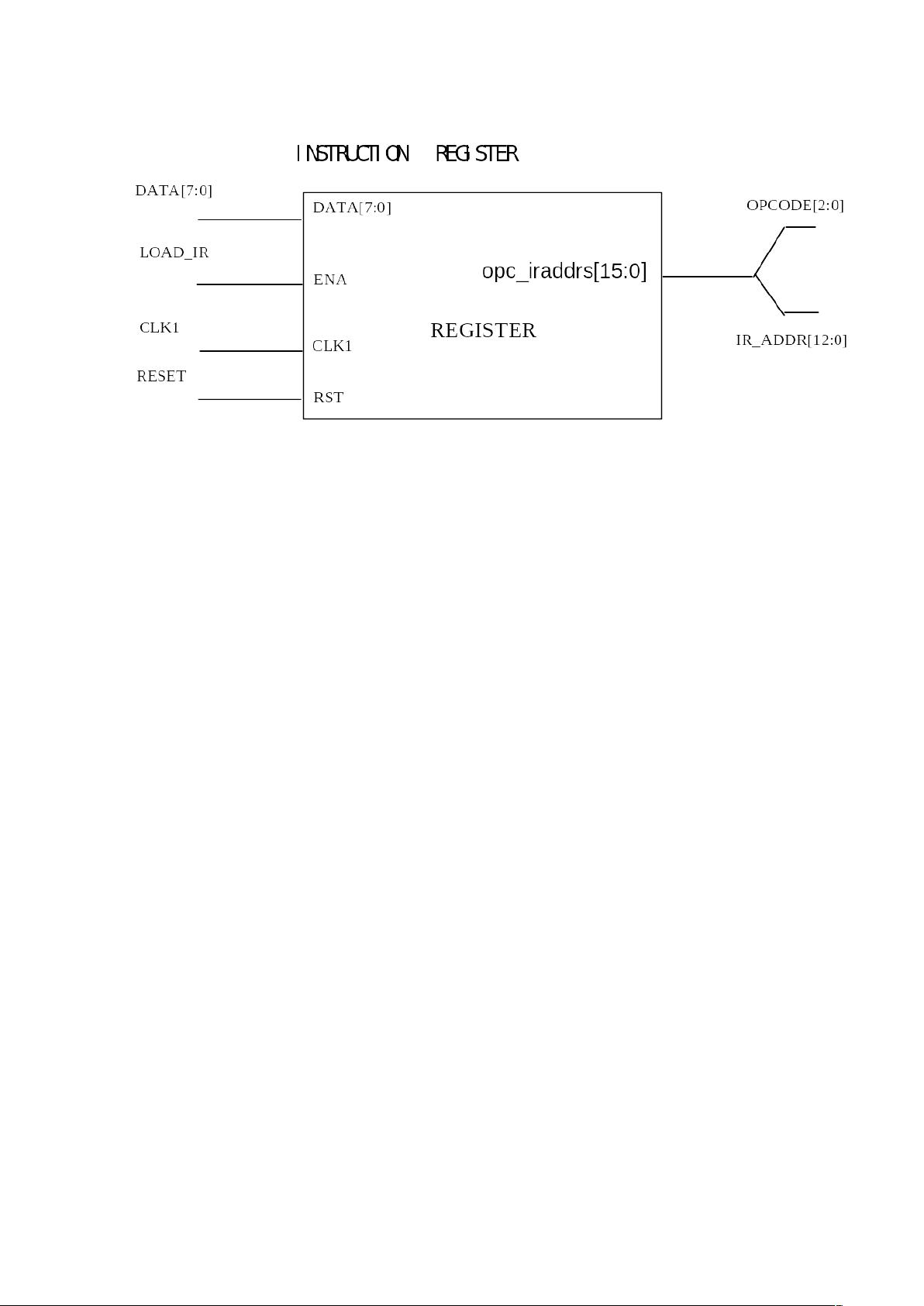
剩余41页未读,继续阅读
资源评论













