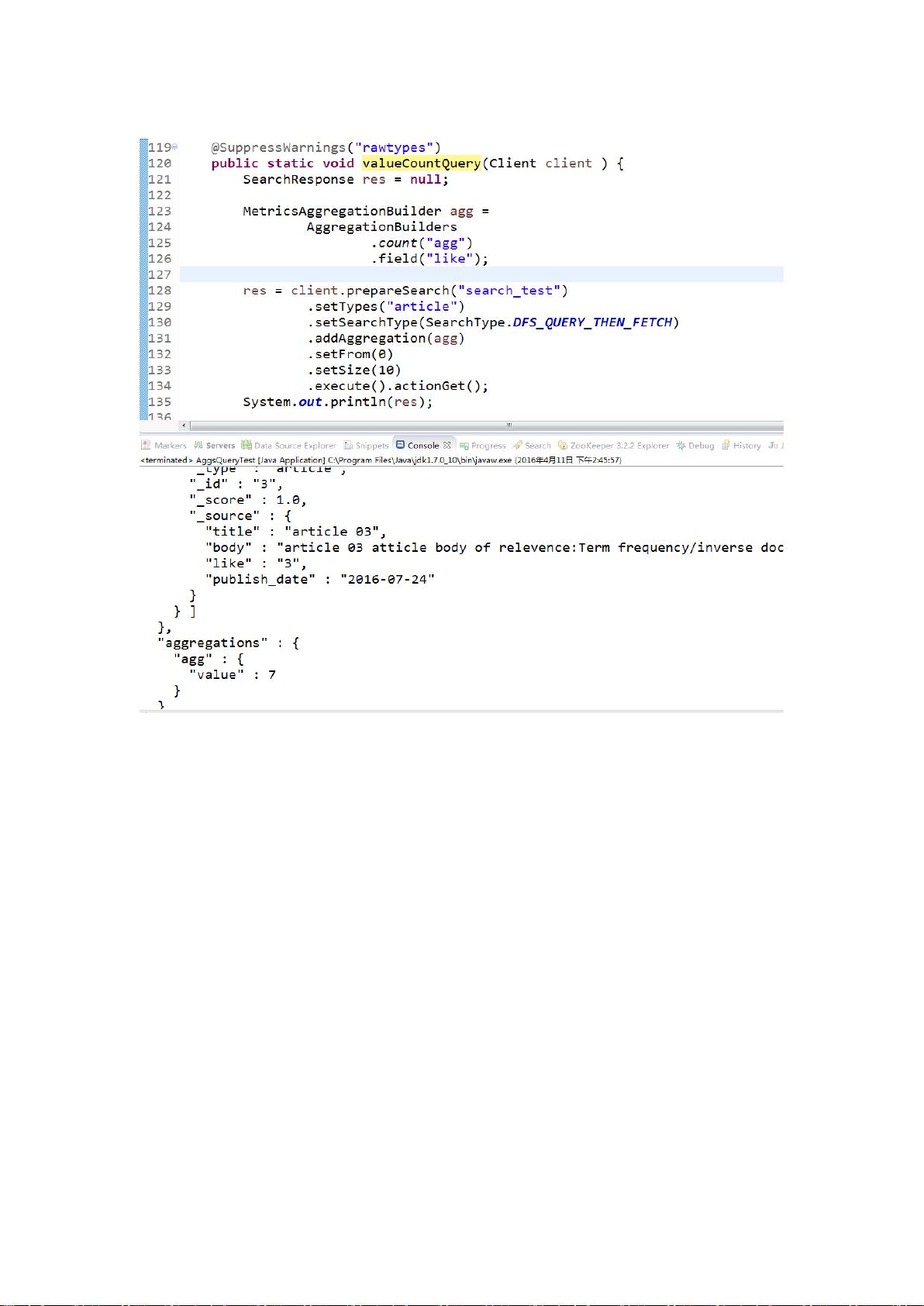
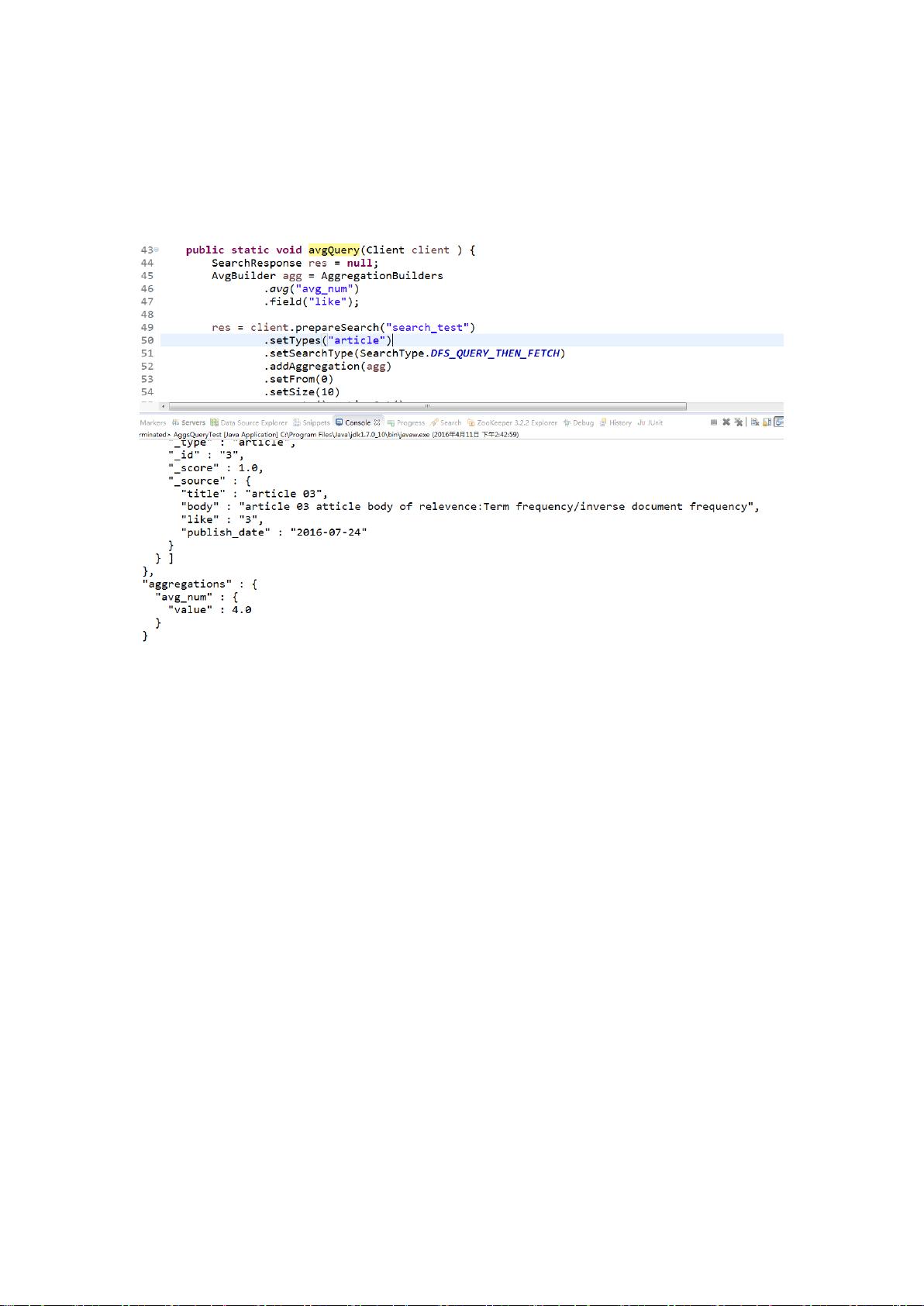
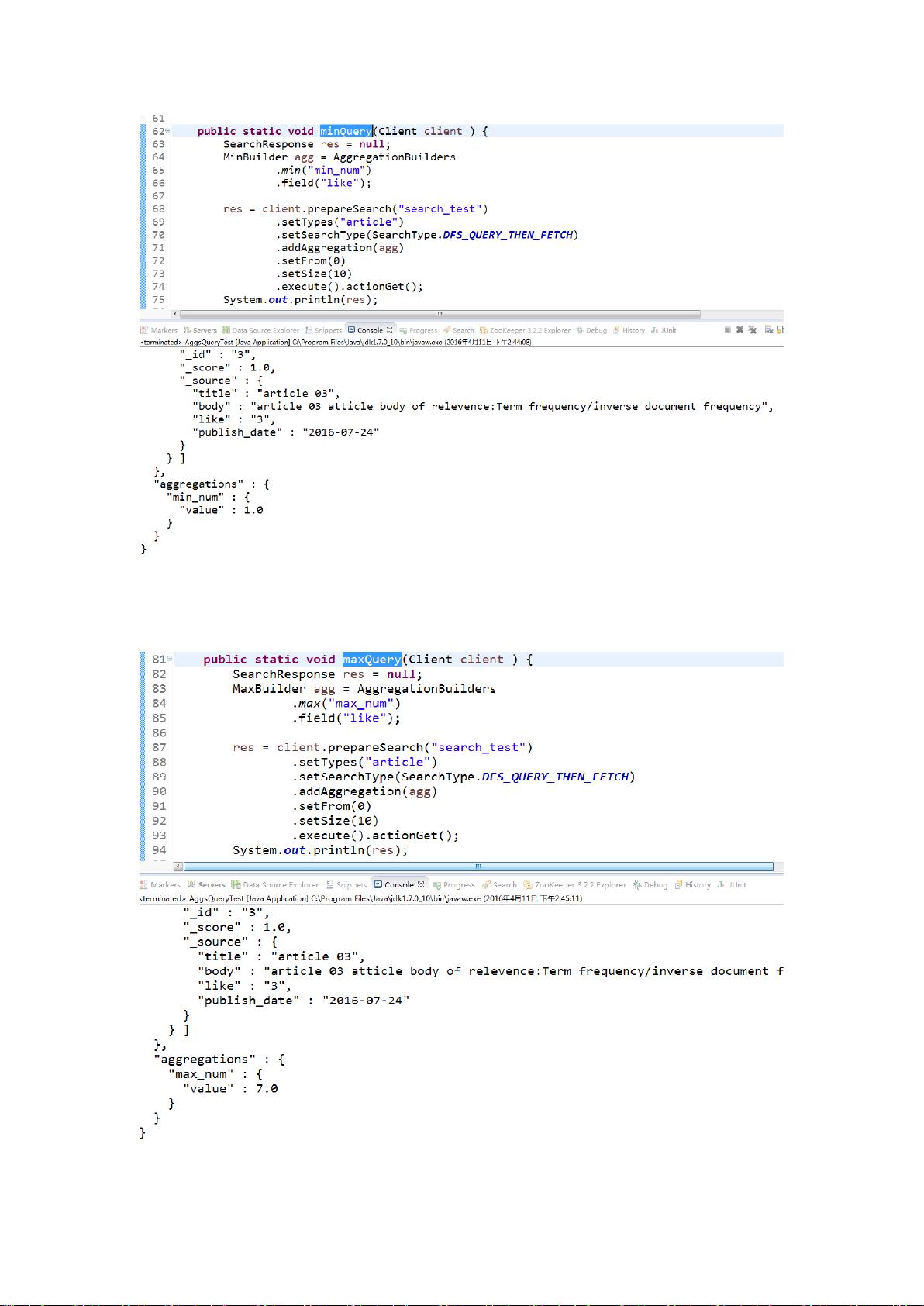
### Elasticsearch API 详细讲解 #### 一、聚合查询(AggsQuery) Elasticsearch 提供了丰富的聚合查询功能,用于对数据进行统计和分析。 1. **avgQuery**:用于计算特定字段的平均值。 2. **minQuery**:用于查询特定字段的最小值。 3. **maxQuery**:用于查询特定字段的最大值。 4. **valueCountQuery**:用于统计字段的总数。 5. **extendedStatsQuery**:此查询可以计算并返回包括数量、最小值、最大值、平均值、总和、平方和、方差和标准差等在内的统计信息。 6. **percentileQuery**:计算一个或多个百分位数的近似值,例如1%、5%、25%、75%、99%。 7. **percentileRankQuery**:计算给定数值的百分位排名。 8. **rangeQuery**:用于查询字段中位于自定义分组区间内的数值。 9. **histogramQuery**:执行固定区间递增过程,常用于按照某个数值字段来分组。 10. **dateHistogramQuery**:类似于histogram,但用于日期字段,可以指定如“1Y”这样的时间区间进行聚合分析。 #### 二、复合查询(CompoundQuery) 复合查询允许将其他查询组合起来,以实现更复杂的查询逻辑。 1. **constantScoreQuery**:此查询不计算相关性分数,仅使用索引过程中指定的分数。 2. **boolQuery**:一种重要的复合查询,能够组合其他类型查询,支持三种逻辑关系: - **must**:相当于逻辑AND,满足所有子查询条件。 - **must_not**:相当于逻辑NOT,不满足任意子查询条件。 - **should**:相当于逻辑OR,满足至少一个子查询条件。 3. **disMaxQuery**:将多个子查询的结果进行合并(union),并且选择子查询中分数最高的结果作为最终分数。 #### 三、查询(Query) Elasticsearch 提供了多种查询类型,用于不同的搜索需求。 1. **matchAllQuery**:匹配所有文档,常用于返回结果集的全部文档。 2. **matchQuery**:基本的全文搜索查询,只进行简单的分析,不经过“query parsing”过程,不支持通配符和前缀等高级特性,适合search-box使用。 3. **multiMatchQuery**:将matchQuery应用于多个字段,可指定各个字段的boost权重。 - **fields**:用于指定需要查询的字段。 - **types**:不同的值决定了查询行为的不同: - **best_fields**:_score由得分最高的match-clause决定。 - **most_fields**:考虑所有match-clause。 - **cross-fields**:将多个字段当作一个大的字段进行匹配。 - **phrase_and_phrase_prefix**:每个字段执行相应的查询,并组合分数。 4. **commonTermQuery**:考虑到停用词的低优先级,用于提高查询的精确性。 - **cutoff_frequency**:分组标准。 - **low-frequency** 和 **high-frequency**:将terms分为两类。 - **boolquery**:内部通过must和should实现查询。 5. **rangeQuery**:用于指定日期、字符串或数字等类型的区间查询。 6. **termQuery**:基于索引时的term进行查询,对大小写敏感,常用于精确值匹配。 需要注意的是,由于文档内容为OCR扫描结果,可能有字识别错误或漏识别的情况。在学习和使用这些知识点时,请根据上下文灵活理解,并将术语和概念补充完整,以保证内容的准确性和可用性。 对初学者而言,理解以上聚合查询、复合查询和基础查询的各种用法和适用场景,有助于深入掌握Elasticsearch的搜索和数据处理能力,进一步能够根据实际业务需求进行优化和定制。
剩余13页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~