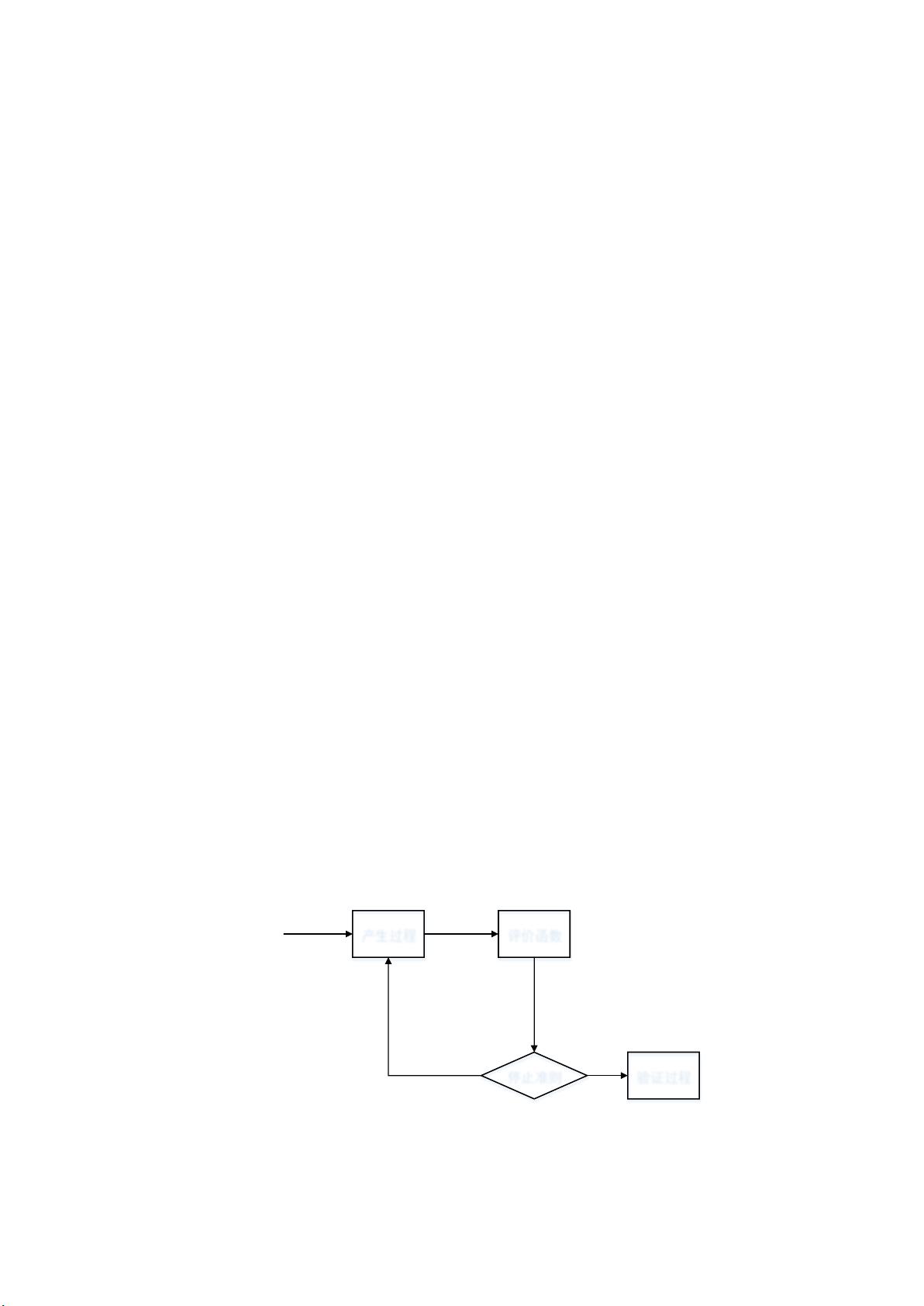
(一) 选择候选特征集:
得到候选特征集的步骤如下:
1. 用 mRMR 增量选择法,从输入中选择个特征,得到一系列的特征集:
。
2. 比较个特征集,选择一个的范围,使得
对应的误差
相对一致,且较小。
3. 在中,选择最小的分类误差
,
即为最终得到的候选特征集。
综上所述,得到的候选特征集大小
。
(二) 选择紧凑(Compact)的特征集:
许多复杂的算法都可以用来从一个候选集
中搜索得到紧凑的特征集。在这个特
征选择的算法中,使用封装器(Wrapper)来实现这一过程。
封装器实质上是一个分类器(如朴素贝叶斯分类器),它用选取的特征子集对样本
集进行分类,分类的精度作为衡量特征子集好坏的标准。在第一个阶段中,我们已经使
用 mRMR 算法找到了一个较小的候选特征集,所以在第二步中,大大的降低了分装器
的运算复杂度。本文中,考虑封装器的两种选择方案——前向选择和后向选择:
1. 前向选择算法:特征子集 S 从空集开始,每次选择一个特征
加入特征子集,
使得特征函数最优。简单说就是,每次都选择一个使得评价函数的取值达
到最优的特征加入,其实就是一种简单的贪心算法
2. 后向选择算法:从特征全集
开始,每次从特征集 S 中剔除一个特征
,使得
剔除特征
后评价函数值达到最优。
2.3 主成分分析(PCA)算法
主成分分析是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要
影响因素,揭示事物的本质,简化复杂的问题。计算主成分的目的是将高维数据投影到较低
维空间。PCA 是一种用原有变量的线性组合来表示事物主要方面的分析方法。
PCA 主要用于数据降维,对于一系列例子的特征组成的多维向量,多维向量里的某些元
素本身没有区分性,比如某个元素在所有例子中都为 1,或者与 1 差距不大,那么这个元素
本身就没有区分性,用它做特征来区分,贡献会非常小。所以我们的目的是找那些变化大的
元素,即方差大的那些维,而去除掉那些变化不大的维,从而使特征留下的都是主要的成分,
同时使得计算量也大大降低。
在 MATLAB 中有 PCA 的函数 princomp(X),对 n 行 n 列的数据集 X 做完主成分分析以后
会返回主成分系数,X 的每行表示一个样本的观测值,每一列表示特征变量。
返回的第一个参数 COEFF 是一个 p 行 p 列的矩阵,每一列包含一个主成分函数,列是
按主成分变量递减顺序排列,也就是说,COEFF 是 X 矩阵所对应的协方差矩阵 V 的所有特征
向量组成的矩阵,即变换矩阵或投影矩阵,COEFF 每列对应一个特征值的特征向量,列的排
列顺序是按特征值的大小递减排序的。
返回的 SCORE 是对主成分的打分,也就是说原来 X 矩阵在主成分空间的表示。SCORE 每
行对应样本观测值,每列对应一个主成分(变量),它的行和列的数目和 X 的行列数目相同。
返回的 latent 是一个向量,它是 X 所对应的协方差矩阵的特征值向量。
三、 实验设计:
我们首先编写了 mRMR 算法的 C++代码,从特征集中选择候选子集,并保存对应特征的