ChatGPT4.0论文(中文)-开放的人工智能.pdf
需积分: 0 154 浏览量
2023-03-16
15:46:49
上传
评论
收藏 2.45MB PDF 举报


GPT-4技术报告
开放的人工智能
∗
摘要
我们报告了GPT-4的发展,这是一个大规模的多模态模型,它可以接受图像和
文本输入并产生文本输出。虽然在许多现实场景中,GPT-4的能力不如人类,
但在各种专业和学术基准上表现出了人类水平的表现,包括通过模拟律师资格
考试,成绩在前10%左右。GPT-4是一个预先训练过的基于转换器的模型,用于
预测文档中的下一个令牌。训练后的对齐过程提高了事实性测量和对期望行为
的坚持。该项目的一个核心组件是开发基础设施和优化方法,可预测的范围。
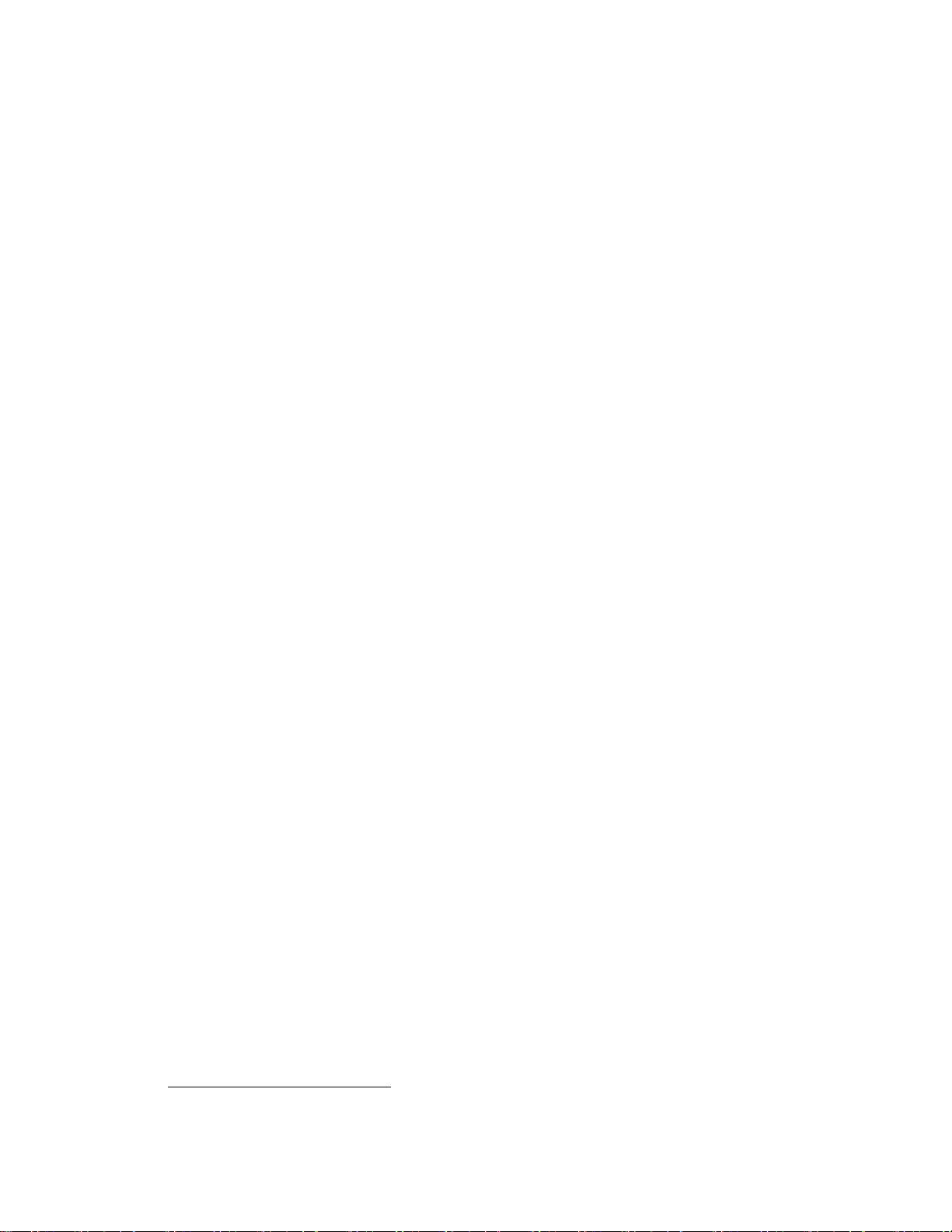
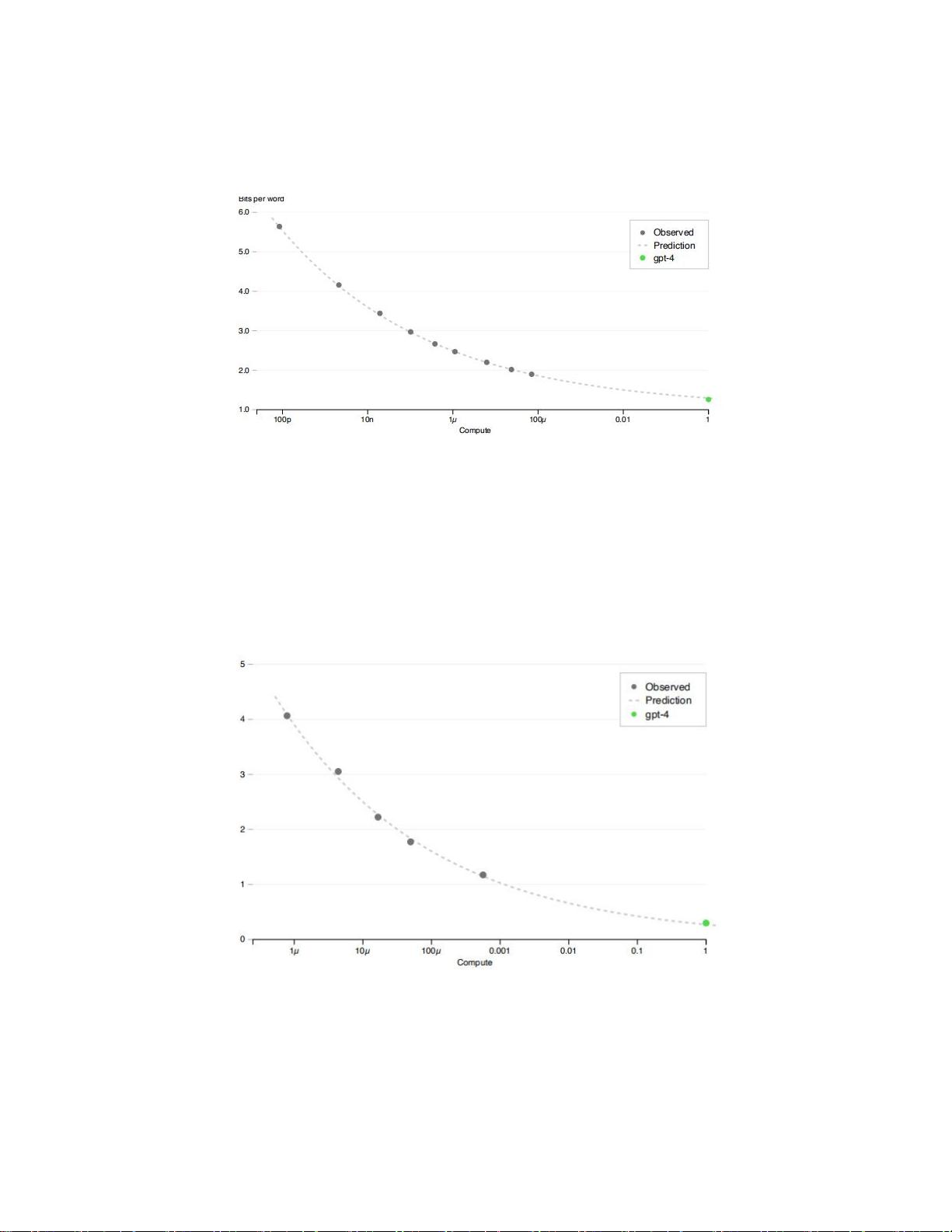
这使我们能够准确地预测GPT-4的某些方面
基于计算不超过GPT-4的1/1000的模型。
1介绍
本技术报告介绍了GPT-4,一种能够处理图像和文本输入并产生文本输出的大型多模态模型。这
些模型是一个重要的研究领域,因为它们有潜力被用于广泛的应用中,如对话系统、文本摘要
和机器翻译。因此,它们一直是近年来[1–28]的重大兴趣和进展的主题。
开发这种模型的主要目标之一是提高它们理解和生成自然语言文本的能力,特别是在更复杂和
更微妙的场景中。为了在这种情况下测试它的能力,GPT-4在最初为人类设计的各种测试中进行
了评估。在这些评估中,它的表现表现得相当好,而且得分往往超过了绝大多数的人类考生。
例如,在一个模拟的酒吧考试中,GPT-4的成绩排名前10%。这与GPT-3.5形成了鲜明对比,后者
排名倒数10%。
在一套传统的NLP基准测试中,GPT-4的性能优于以前的大型语言模型和大多数最先进的系统
(它们通常有特定于基准测试的培训或手工工程)。在MMLU基准测试[29,30]上,一套涵盖57个
科目的英语多项选择题,GPT-4不仅在英语方面远远超过了现有的模型,而且在其他语言中也表
现出了强大的性能。在MMLU的翻译变体上,GPT-4在26种语言中的24种中超过了最先进的英语语
言。我们将在后面的章节中更详细地讨论这些模型性能结果,以及模型安全性改进和结果。
本报告还讨论了该项目的一个关键挑战,开发深度学习基础设施和优化方法,在广泛的范围内
可以预测。这使得我们能够对GPT-4的预期性能(基于以类似方式训练的小运行)进行预测,并
与最终运行相比进行测试,以增加我们对训练的信心。
尽管GPT-4具有其能力,但与早期的GPT模型[1,31,32]有类似的局限性:它不完全可靠(e。g.会
遭受“幻觉”),上下文窗口有限,并且不学习
*
请引用这篇作品为“OpenAI( 2023)”。完整的作者贡献声明出现在文档的末尾。


剩余98页未读,继续阅读
资源评论













