

队伍编号 dsa2101008
题号 B
基于 PU-bagging 与 Gini 决策树的用户行为预测与价值判别
摘 要
如今互联网不断发展,但是对于各领域公司来说,如何识别高质量的用户和渠道,
从而进一步优化各自的营销方案一直是一个难点。本文以一家公司的用户行为数据为例,
通过数据统计分析的手段对用户购买结果与行为价值进行判别
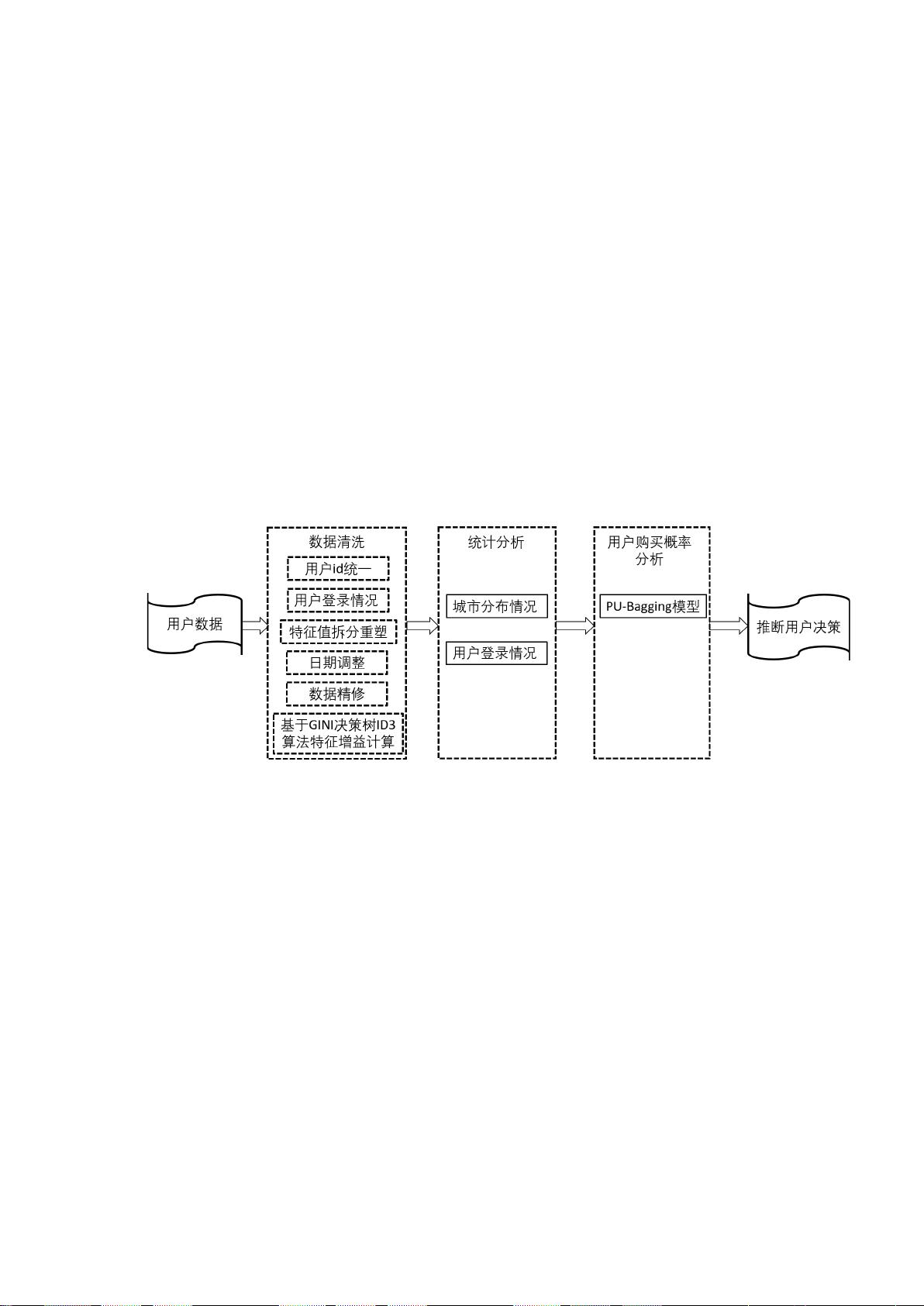
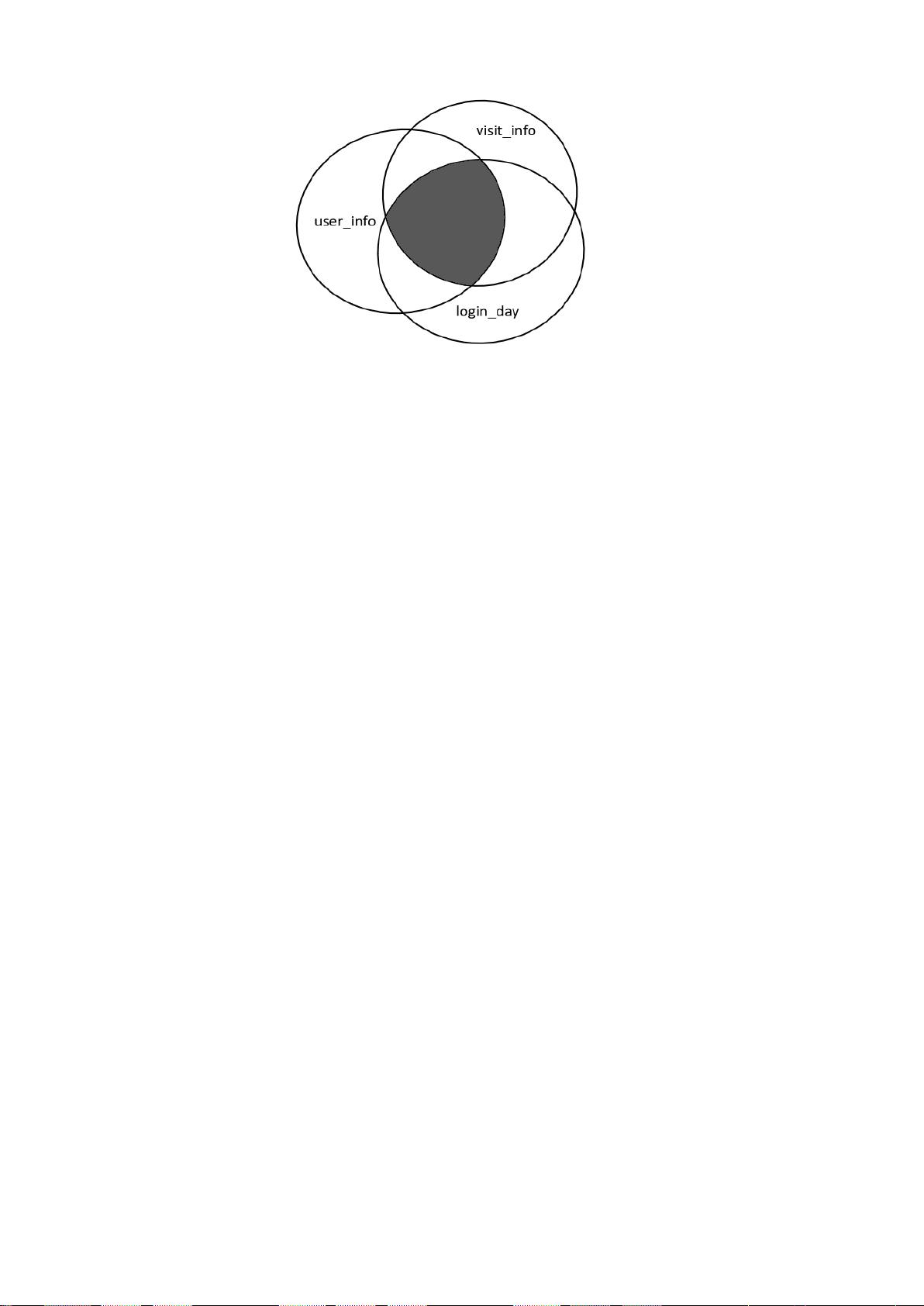
针对任务一,本文对给定的用户信息表(user_info.csv )、用户登录情况表
(login_day.csv)、用户访问统计表(visit_info.csv)的数据进行了预处理,通过采取用户
id 统一、城市及日期数据的特殊处理、部分数据精修和 GINI 决策树 ID3 算法的方法提
高了数据质量,使处理后的数据可以更好地被统计并与后续算法匹配。
针对任务二,首先对城市数据进行统计,得到各城市的用户数量情况,对数据进行
饼图与柱状图结合的可视化呈现方式,并进一步绘制地理分布图体现用户的空间分布情
况;其次,本文将用户登录情况的特征指标分为 A、B、C 三类,分别进行统计学分析、
数据统计,并以表格、饼图、柱状图的多重呈现方式表现,最后对每一类数据情况代表
的含义进行了分析。
针对任务三,本文将用户下单表(result.csv)作为正样本,剩余的其他用户作为未
标记样本,构建基于正样本、未标记样本的 Bagging 集成 PU-Learning 模型,将经过任
务一处理的数据作为特征指标进行半监督学习,对未标记样本用户为正样本的概率进行
了运算,得到用户购买课程概率的预测结果。
针对任务四,本文结合用户信息、用户访问、用户登录情况的统计,针对任务三中
预测购买概率在 80%以上的群体进行了用户行为特征的对比与总结,并在这三个方面分
别给出分析结果。基于分析结果,我们给公司的营销政策提供了一些建议。
最后,我们对模型进行了总结与评价,分析了模型的优势以及能够进一步提升与改
进的地方,并对模型未来的优化方案提出了一些设想。
关键词:GINI 决策树 ID3 算法;可视化呈现;Bagging;PU-Learning

剩余23页未读,继续阅读
资源评论


阿拉伯梳子
- 粉丝: 2710
- 资源: 5734

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 基于粒子群算法的电动汽车充电站和光伏最优选址和定容 关键词:选址定容 电动汽车 充电站位置 仿真平台:MATLAB 主要内容:代码主要做的是一个电动汽车充电站和分布式光伏的选址定容问题,提出了
- 伺服送料机,步进电机,伺服电机,程序,三菱,台达,中达一体机,送料机程序,PLC多段数据不同,可任意调节A段B段c段长度,并定长切断 程序能存储5段工件数据,使用调出非常方便 PLC程序有台达ES
- 考虑安全约束及热备用的电力系统机组组合研究 关键词:机组组合 直流潮流 优化调度 参考文档:店主自编文档,模型数据清晰明了 仿真平台:MATLAB+CPLEX gurobi平台 优势:代码具有一定
- 计及源-荷双重不确定性的电厂 微网日前随机优化调度系统 关键词:电厂 微网 随机优化 随机调度 源-荷双重不确定性 电厂调度 参考文档:Virtual power plant mid-ter
- 基于mpc模型预测轨迹跟踪控制,总共包含两套仿真,一套是不加入四轮侧偏角软约束,一套是加入四轮侧偏角的软约束控制,通过carsim与simulink联合仿真发现加入侧偏角软约束在进行轨迹跟踪时,能够通
- 采用下垂控制的孤岛逆变器仿真 名称:droop-controlled-converter-island 软件:Matlab R2016a 控制:下垂控制,闭环电流反馈控制,解耦电压电流环控制,见图1
- 直驱式波浪发电最大功率捕获matlab仿真 电机:直线电机 控制器:PID控制器 策略:基于RLC等效电路模型的最大功率输出 含:使用说明书+教学视频
- 西门子200smart标准程序,西门子程序模板参考,3轴控制程序,含西门子触摸屏程序,详细注释,IO表,电气原理图
- 基于西门子PLC200自动保暖供水系统,系统用于厂区饮用水,区域热水保暖,系统中大多数用于时间进行各个季节,各个时间的控制 供水区域时间的设定 可以实现在每一个阶段按照每一个流程进行不同的运行
- 西门子S7-1200四层电梯模拟程序 电梯WinCC动画程序 西门子参考学习程序 博图15或者以上可以打开 PLC:西门子S7-1200 触摸屏:KTP900 有人会问:为什么是四层电梯参考学习程序
- 整车电子电气正向开发网络架构 , 倘若您是产品经理或者项目经理又或者是技术leader,这个将帮助您梳理在整车电子电气正向开发过程中不同系统的内部架构设计及相互间的关联,涵盖整车控制系统、网联系统、驾
- dsp28335三相逆变程序,可以开环测试
- 含分布式电源的无功补偿(Matlab程序): 1.以无功补偿调节代价为目标函数,不同风光电源渗透率下,优化确定无功补偿装置出力情况(改进灰狼优化算法IGWO) 2.以网损和电压偏差为目标函数,才用分
- 整车控制器 基于MPC和滑模控制算法实现的车辆稳定性控制,建立了横摆角速度、侧向速度、前后质心侧偏角动力学模型作为预测模型,同时考虑车辆的稳定性可通过控制车辆的侧向速度维持在一定范围内保证车辆的稳定性
- COMSOL MATLAB 代码 二维随机裂隙 2维随机裂隙生成 功能:可以实现多组不同方向,不同分布规律的裂隙生成(任意组数都可以) 需要输入的参数有:每组裂隙的迹长范围、分布规律(正态分布o
- 全阶滑模无位置传感器控制仿真模型,有基本的开关函数,有饱和函数,sigmod函数等多种滑模 还有全阶滑模观测器仿真,相比传统滑模观测器消除了额外的低通滤波器,误差更小,效果堪称完美 不仅误差小
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


