2023/6/28 17:17
谷歌&HuggingFace| 零样本能力最强的语言模型结构
https://mp.weixin.qq.com/s/hTUxSctHsetjORMvm8XkSw
1/9
谷歌&HuggingFace| 零样本能力最强的语言模型结构
收录于合集
#卖萌屋@自然语言处理
97个
文 | iven
从 GP T3 到 Prompt,越来越多人发现大模型在零样本学习(zero-shot)的设定下有非常好的
表现。这都让大家对 AGI 的到来越来越期待。
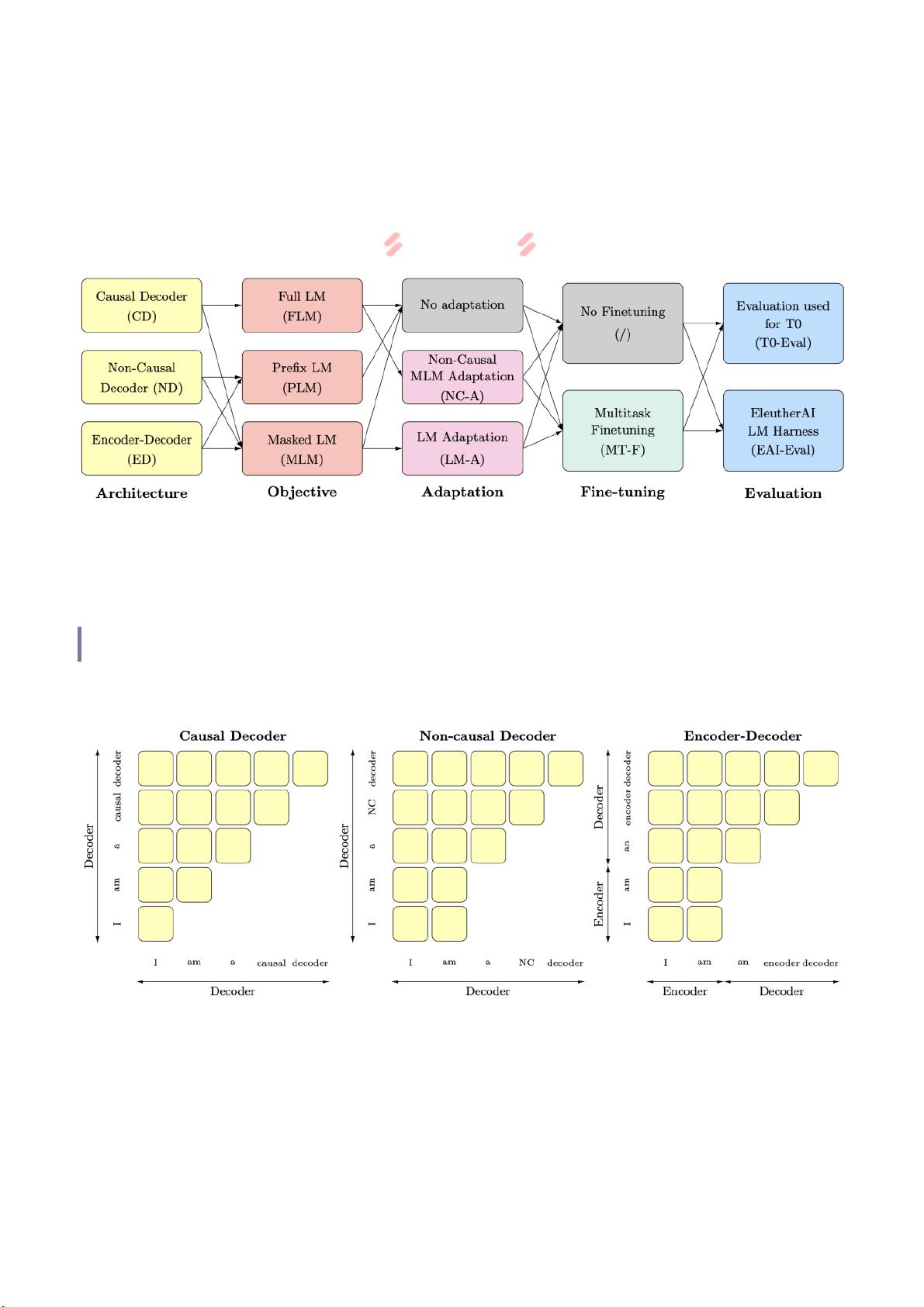
但有一件事让人非常疑惑:19 年 T5 通过“调参” 发现,设计预训练模型时,Encoder-Decoder
的模型结构 + MLM 任务,在下游任务 finetune 效果是最好的。可是在 2202 年的当下,主 流
的 大 模 型 用 的 都 是 仅 decoder 的 模 型 结 构 设 计 , 比 如 OpenAI 的 GPT 系 列 、 Google 的
PaLM [1]、Deepmind 的 Chinchilla [2] 等等。这是为什么?难道这些大模型设计都有问题?
今天带来一篇 Hugging Face 和 Google 的文章。这篇文章与 T5 在实验上的思路相似,通过大
量对比设计,得到一个重磅结论:要 是 为 了 模 型 的 zero-shot 泛 化 能 力 , decoder 结 构 +
语 言 模 型 任 务 最 好 ; 要 是 再 multitask finetuning, encoder-decoder 结 构 + MLM 任 务
最 好 。
除了找到最好的训练方式,作者通过大量的实验,还找到了最好的同时还能最节省成本的训练
方式。训练计算量只需要九分之一!
论 文 题 目 :
What Language Model Architecture and Pretraining Objective Work Best for Zero-
iven 2022-06-23 12:05 发表于四川
原创
夕小瑶科技说