



数据可视化⽅向的毕业设计——基于Python爬⾍的招聘信息及租房数据可视化
分析系统
距离我本科答辩顺利通过已经过去⼗⼏天了,我决定把本科阶段最后的⼩成果做个总结分享给想做此⽅向项⽬的⼩伙伴们,希望能让你们想
在动⼿实操时有项⽬可供参考,有实现思路可供学习,先呈现给⼤家。
⼀、研究⽬的及意义
(⼀)现状
1. 应届毕业⽣关注重点难点:找⼯作+租房⼦
2. 招聘⽹站繁杂:拉勾⽹、BOSS直聘、前程⽆忧等
3. 各个⼤学的就业信息⽹站成熟
4. 租房⽹站众多:链家⽹、我爱我家等
(⼆)缺点
1. 仅提供信息,功能单⼀
2. 信息分散,⽆法了解整体情况
3. ⽂字、数字形式不直观
4. 招聘与租房⽆关联
(三)改进
1. 整合信息、统计数据
2. 分区域数据可视化
3. 丰富的图表呈现
4. 集招聘租房于⼀体
因此,当下迫切需要⼀个能够把尽可能多的信息整合到⼀起的平台,且该平台需要具备强⼤的统计数据及数据可视化的功能,这样,⽤户就
可以通过该平台来检索招聘信息及房源信息,并且可以通过图表可视化了解整体情况。对于每年⽇益增多的就业⼤军⽽⾔,可以从该系统中
清楚了解到⽬前在⼀线城市、新⼀线城市、⼆线城市的互联⽹各⾏业及租房现状,有助于做出适合⾃⾝情况的选择。
⼆、实现思路与相关技术
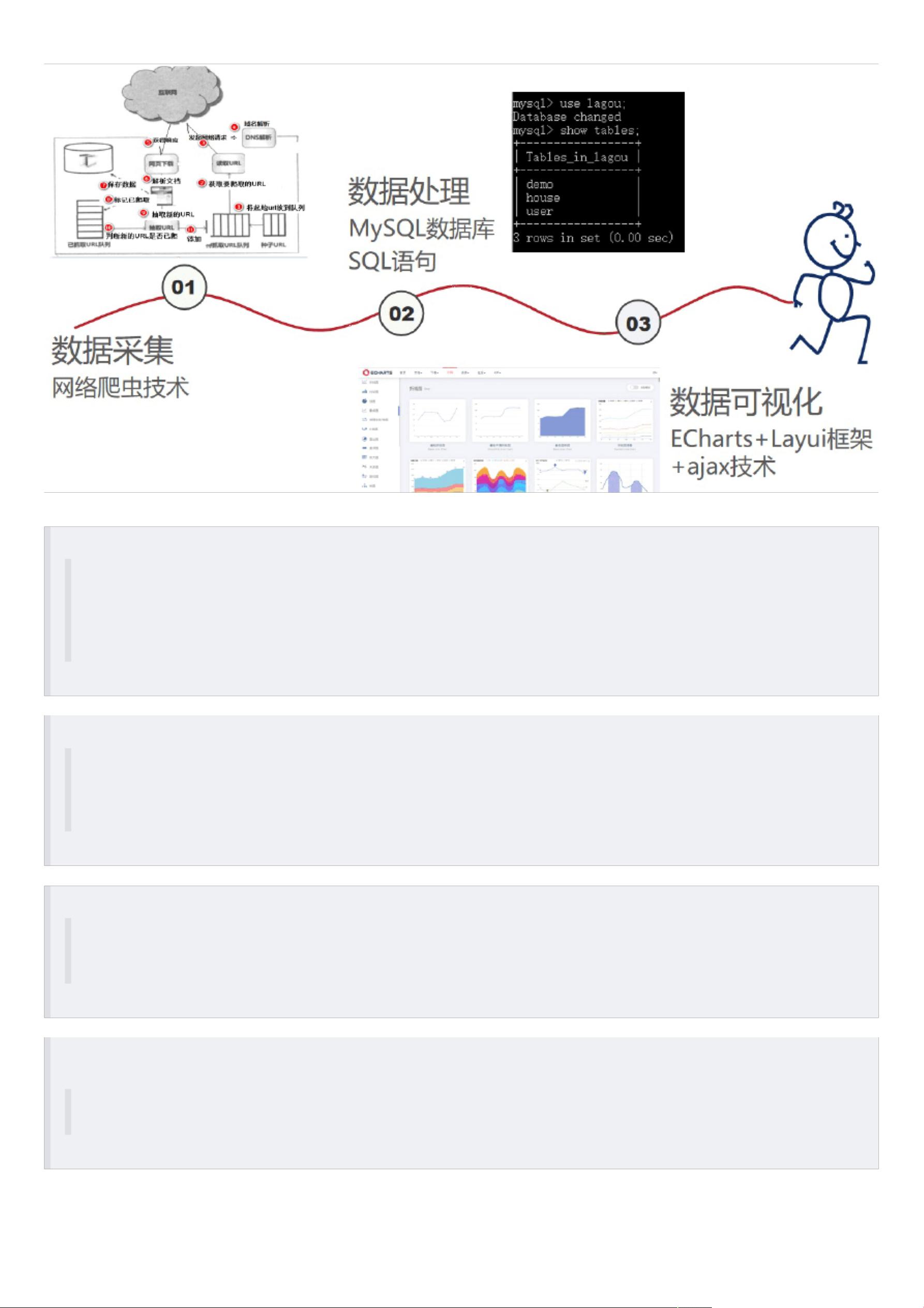
前后端数据交互的实现——ajax技术
通过ajax传递参数,它是⽤户和服务器之间的⼀个中间层,使得⽤户操作和服务器响应异步化,前端将需要传递的参数转化为
JSON字符串(json.stringify)再通过get/post⽅式向服务器发送⼀个请求并将参数直接传递给后台,后台对前端请求作出反
应,接收数据,将数据作为条件进⾏查询,返回json字符串格式的查询结果集给前端,前端接收到后台返回的数据进⾏条件判断
并做出相应的页⾯展⽰。
get/post请求⽅式的区别
都是向服务器提交数据,都能从服务器获取数据。Get⽅式的请求,浏览器会把响应头和数据体⼀并发送出去,服务器响应200
表⽰请求已成功,返回数据。Post⽅式的请求,浏览器会先发送响应头,服务器响应100后,浏览器再发送数据体,服务器响
应200,请求成功,返回数据。Post⽅式安全性更好。
什么时候⽤get,什么时候⽤post请求⽅式?
登录注册、修改信息部分都使⽤post⽅式,数据概况展⽰、可视化展⽰部分都使⽤get⽅式。也就是数据查询⽤get⽅式,数据
增加、删除、修改⽤post⽅式更加安全。
数据可视化图表展⽰——ECharts图表库(包含所有想要的图表⽣成代码,可⽀持在线调试代码,图表⼤⽓美观,此⽹站真的绝绝
⼦,分享给⼤家)
⽹站:
三、系统整体功能框架

四、详细实现
(⼀)数据获取
1、获取招聘信息
因为拉勾⽹具有较强的反爬机制,使⽤user-agent和cookies封装头部信息,将爬⾍程序伪装成浏览器访问⽹页,通过requests包的
post⽅法进⾏url请求,请求成功返回json格式字符串,并使⽤字典⽅法直接读取数据,即可拿到我们想要的python职位相关的信
息,可以通过读取总职位数,通过总的职位数和每页能显⽰的职位数.我们可以计算出总共有多少页,然后使⽤循环按页爬取, 最后将职
位信息汇总, 写⼊到CSV格式的⽂件以及本地mysql数据库中。
import requests
import math
import time
import pandas as pd
import pymysql
from sqlalchemy import create_engine
def get_json(url, num):

从指定的url中通过requests请求携带请求头和请求体获取⽹页中的信息,
:return: :return:
url1 = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
'Cookie':'user_trace_token=20210218203227-35e936a1-f40f-410d-8400-b87f9fb4be0f; _ga=GA1.2.331665492.1613651550; LGUID=202102182032
30-39948353-de3f-4545-aa01-43d147708c69; LG_HAS_LOGIN=1; hasDeliver=0; privacyPolicyPopup=false; showExpriedIndex=1; showExpriedCompany
Home=1; showExpriedMyPublish=1; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf75
6e6=1613651550,1613652253,1613806244,1614497914; _putrc=52ABCFBE36E5D0BD123F89F2B170EADC; gate_login_token=ea312e017beac7fe7254
7a32956420b07d6d5b1816bc766035dd0f325ba92b91; JSESSIONID=ABAAAECAAEBABII8D8278DB16CB050FD656DD1816247B43; login=true; unick=%
E7%94%A8%E6%88%B72933; WEBTJ-ID=20210228%E4%B8%8B%E5%8D%883:38:37153837-177e7932b7f618-05a12d1b3d5e8c-53e356a-1296000-17
7e7932b8071; sensorsdata2015session=%7B%7D; _gid=GA1.2.1359196614.1614497918; __lg_stoken__=bb184dd5d959320e9e61d943e802ac98a8538
d44699751621e807e93fe0ffea4c1a57e923c71c93a13c90e5abda7a51873c2e488a4b9d76e67e0533fe9e14020734016c0dcf2; X_MIDDLE_TOKEN=90b85
c3630b92280c3ad7a96c881482e; LGSID=20210228161834-659d6267-94a3-4a5c-9857-aaea0d5ae2ed; TG-TRACK-CODE=index_navigation; SEARCH_I
D=092c1fd19be24d7cafb501684c482047; X_HTTP_TOKEN=fdb10b04b25b767756070541617f658231fd72d78b; sensorsdata2015jssdkcross=%7B%22dis
tinct_id%22%3A%2220600756%22%2C%22first_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1296000-177b521c02b467%22%2C%22pro
ps%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_key
word%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_
referrer%22%3A%22%22%2C%22%24os%22%3A%22Linux%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2
288.0.4324.190%22%2C%22lagou_company_id%22%3A%22%22%7D%2C%22%24device_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1
296000-177b521c02b467%22%7D; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1614507066; LGRID=20210228181106-f2d71d85-74fe-4b43
-b87e-d78a33c872ad'
}
data = {
'first': 'true',
'pn': num,
'kd': 'BI⼯程师'}
#
得到
Cookies
信息
s = requests.Session()
print('建⽴session:', s, '')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '')
#
添加请求参数以及
headers
、
Cookies
等信息进⾏
url
请求
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '')
return page_data
def get_page_num(count):
计算要抓取的页数,通过在拉勾⽹输⼊关键字信息,可以发现最多显⽰30页信息,每页最多显⽰15个职位信息
:return: :return:
page_num = math.ceil(count / 15)
if page_num > 29:
return 29
else:
return page_num
def get_page_info(jobs_list):
获取职位
:param jobs_list:
:return: :return:
page_info_list = []
for i in jobs_list: #
循环每⼀页所有职位信息
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(( .join(i['companyLabelList']))
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def unique(old_list):
newList = []
for x in old_list:
if x not in newList :
newList.append(x)
return newList
def main():
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(( , , , ,
)
engine = create_engine(connect_info)
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
for num in range(1, num + 1):
#
获取每⼀页的职位相关的信息
page_data = get_json(url, num) #
获取响应
json
jobs_list = page_data['content']['positionResult']['result'] #
获取每页的所有
python
相关的职位信息
page_info = get_page_info(jobs_list)
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
#
将总数据转化为
data frame
再输出
,
然后在写⼊到
csv
格式的⽂件中以及本地数据库中
df = pd.DataFrame(data=unique(total_info),
columns=['companyFullName', 'companyShortName', 'companySize', 'financeStage',
'district', 'positionName', 'workYear', 'education',
'salary', 'positionAdvantage', 'industryField',
'firstType', 'companyLabelList', 'secondType', 'city'])
df.to_csv('bi.csv', index=True)
print('职位信息已保存本地')
df.to_sql(name='demo', con=engine, if_exists='append', index=False)
print('职位信息已保存数据库')
if __name__ == '__main__':
main()
2、获取租房房源信息
使⽤user-agent和cookies封装头部信息将爬⾍程序伪装成浏览器访问⽹页,通过requests包的get⽅法进⾏url请求获取⽹页数据,
将经过pyquery包解析后⽹页数据按字段添加到dataframe中,再将dataframe存⼊csv⽂件及本地数据库中。
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time













- 1
- 2
- 3
前往页