Deep Speech: Scaling up end-to-end
speech recognition
Awni Hannun
∗
, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen,
Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, Andrew Y. Ng
Baidu Research – Silicon Valley AI Lab
Abstract
We present a state-of-the-art speech recognition system developed using end-to-
end deep learning. Our architecture is significantly simpler than traditional speech
systems, which rely on laboriously engineered processing pipelines; these tradi-
tional systems also tend to perform poorly when used in noisy environments. In
contrast, our system does not need hand-designed components to model back-
ground noise, reverberation, or speaker variation, but instead directly learns a
function that is robust to such effects. We do not need a phoneme dictionary,
nor even the concept of a “phoneme.” Key to our approach is a well-optimized
RNN training system that uses multiple GPUs, as well as a set of novel data syn-
thesis techniques that allow us to efficiently obtain a large amount of varied data
for training. Our system, called Deep Speech, outperforms previously published
results on the widely studied Switchboard Hub5’00, achieving 16.0% error on the
full test set. Deep Speech also handles challenging noisy environments better than
widely used, state-of-the-art commercial speech systems.
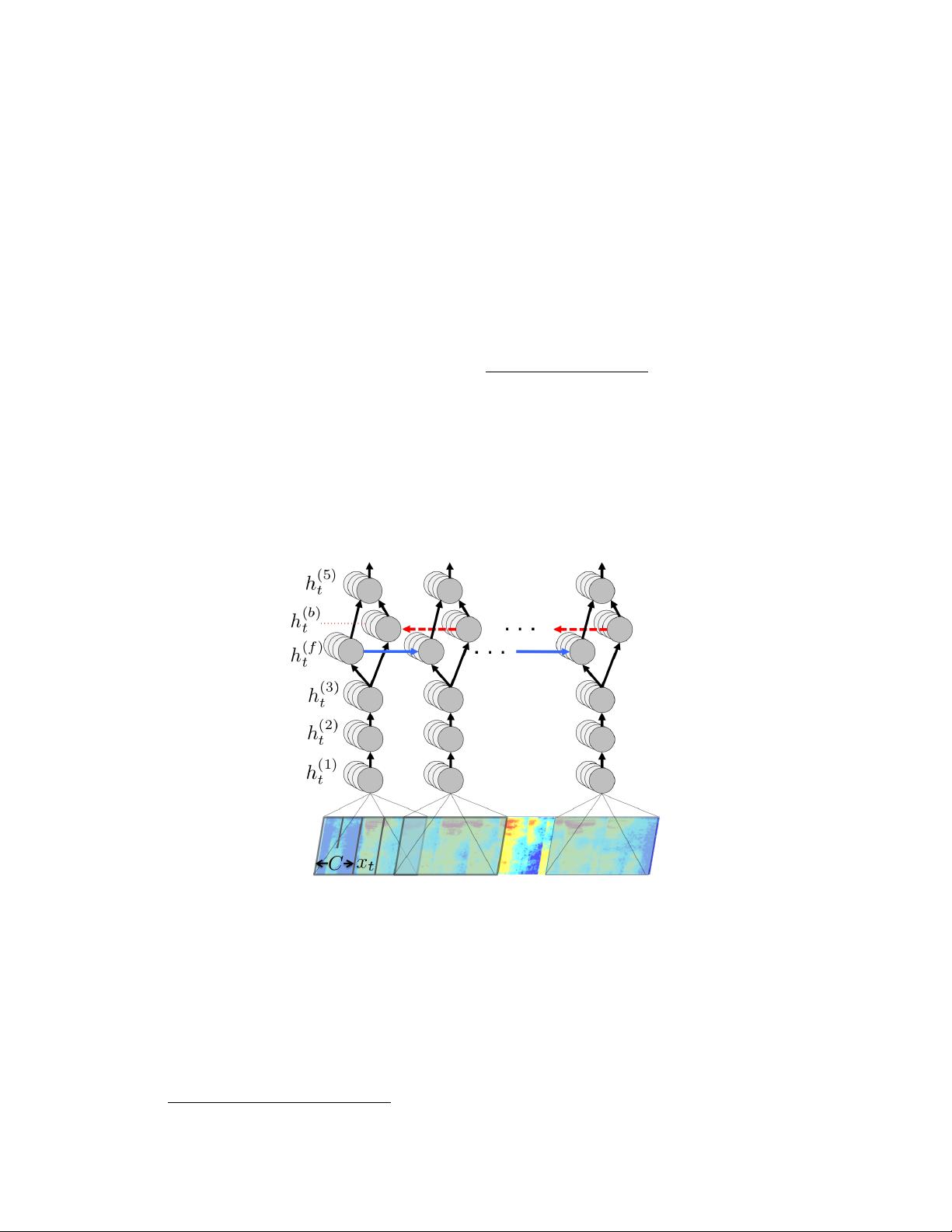
1 Introduction
Top speech recognition systems rely on sophisticated pipelines composed of multiple algorithms
and hand-engineered processing stages. In this paper, we describe an end-to-end speech system,
called “Deep Speech”, where deep learning supersedes these processing stages. Combined with a
language model, this approach achieves higher performance than traditional methods on hard speech
recognition tasks while also being much simpler. These results are made possible by training a large
recurrent neural network (RNN) using multiple GPUs and thousands of hours of data. Because this
system learns directly from data, we do not require specialized components for speaker adaptation
or noise filtering. In fact, in settings where robustness to speaker variation and noise are critical,
our system excels: Deep Speech outperforms previously published methods on the Switchboard
Hub5’00 corpus, achieving 16.0% error, and performs better than commercial systems in noisy
speech recognition tests.
Traditional speech systems use many heavily engineered processing stages, including specialized
input features, acoustic models, and Hidden Markov Models (HMMs). To improve these pipelines,
domain experts must invest a great deal of effort tuning their features and models. The introduction
of deep learning algorithms [27, 30, 15, 18, 9] has improved speech system performance, usually
by improving acoustic models. While this improvement has been significant, deep learning still
plays only a limited role in traditional speech pipelines. As a result, to improve performance on a
task such as recognizing speech in a noisy environment, one must laboriously engineer the rest of
the system for robustness. In contrast, our system applies deep learning end-to-end using recurrent
neural networks. We take advantage of the capacity provided by deep learning systems to learn
from large datasets to improve our overall performance. Our model is trained end-to-end to produce
∗
Contact author: awnihannun@baidu.com
1
arXiv:1412.5567v2 [cs.CL] 19 Dec 2014