

Machine Learning,
20,
273-297
(1995)
©
1995 Kluwer Academic
Publishers,
Boston. Manufactured
in The
Netherlands.
Support-Vector Networks
CORINNA CORTES corinna@neural.att.com
VLADIMIR
VAPNIK
vlad@neural.att.com
AT&T
Bell Labs., Holmdel,
NJ
07733,
USA
Editor:
Lorenza
Saitta
Abstract.
The
support-vector network
is a new
learning machine
for
two-group classification problems.
The
machine conceptually implements
the
following idea: input vectors
are
non-linearly mapped
to a
very high-
dimension feature
space.
In
this feature
space
a
linear
decision
surface
is
constructed.
Special
properties
of the
decision surface
ensures
high generalization ability
of the
learning machine.
The
idea behind
the
support-vector
network
was
previously implemented
for the
restricted
case
where
the
training
data
can be
separated
without
errors.
We
here extend
this
result
to
non-separable training data.
High generalization ability
of
support-vector networks utilizing polynomial input transformations
is
demon-
strated.
We
also
compare
the
performance
of the
support-vector network
to
various
classical
learning algorithms
that
all
took part
in a
benchmark study
of
Optical Character Recognition.
Keywords: pattern recognition,
efficient
learning algorithms, neural networks, radial basis
function
classifiers,
polynomial classifiers.
1.
Introduction
More
than
60
years
ago
R.A. Fisher (Fisher, 1936) suggested
the first
algorithm
for
pattern
recognition.
He
considered
a
model
of two
normal distributed populations, N(m
1
,
EI)
and
N(m
2
,
E
2
) of n
dimensional vectors
x
with mean vectors
m
1
and m
2
and
co-variance
matrices
E1 and E2, and
showed that
the
optimal (Bayesian) solution
is a
quadratic decision
function:
In
the
case
where
E
1
= E
2
= E the
quadratic decision
function
(1)
degenerates
to a
linear
function:
To
estimate
the
quadratic decision
function
one has to
determine "("+
3
)
free
parameters.
To
estimate
the
linear
function
only
n
free
parameters have
to be
determined.
In the
case where
the
number
of
observations
is
small (say
less
than 10n
2
) estimating o(n
2
) parameters
is not
reliable. Fisher therefore recommended, even
in the
case
of EI ^ £2, to use the
linear
discriminator
function
(2)
with
£ of the
form:
where
T is
some constant
1
. Fisher also recommended
a
linear decision
function
for the
case where
the two
distributions
are not
normal. Algorithms
for
pattern recognition

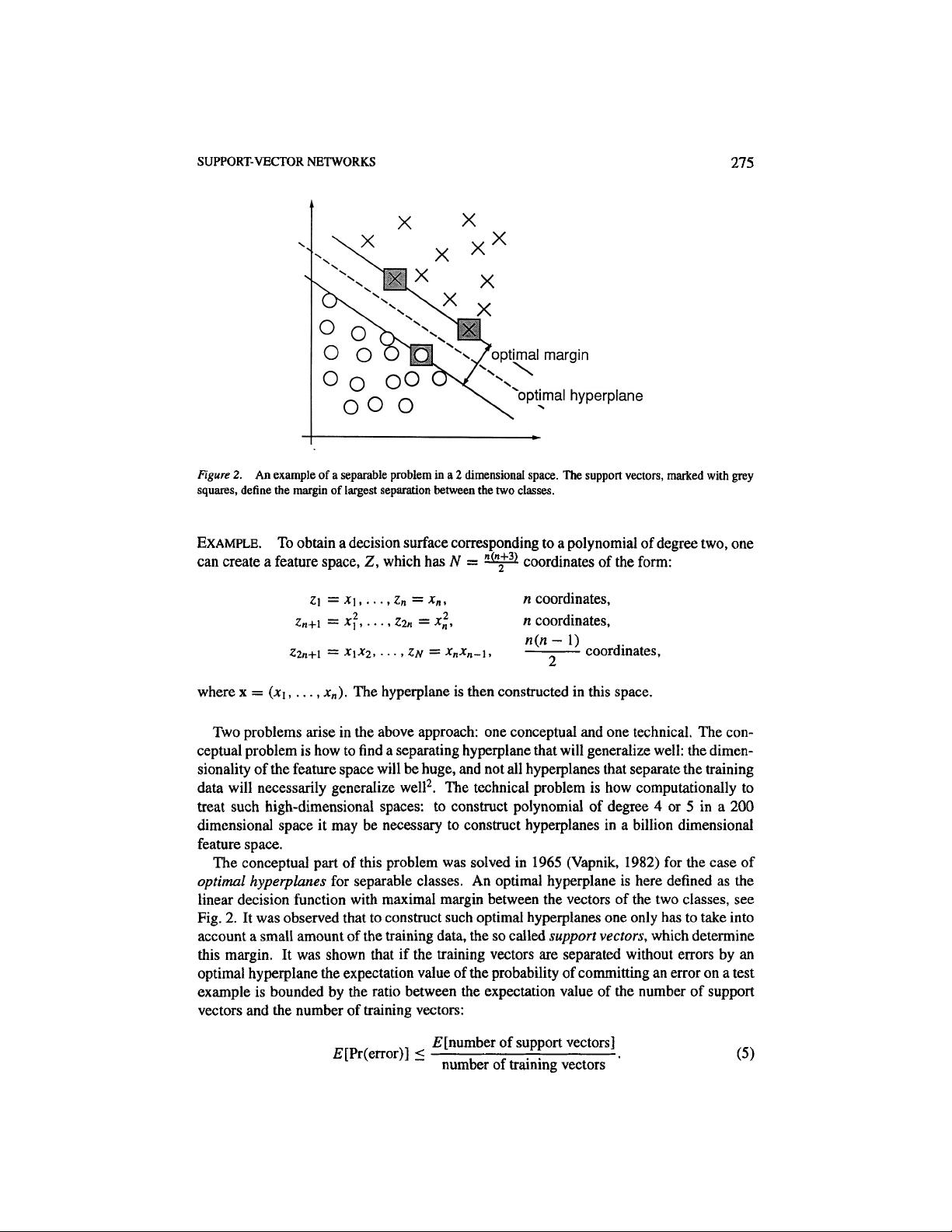

剩余24页未读,继续阅读
资源评论

 ElricYM2012-12-28挺好的,不过是英文的
ElricYM2012-12-28挺好的,不过是英文的












