聚类算法实验 (2).docx
版权申诉
70 浏览量
2022-10-29
09:47:09
上传
评论
收藏 723KB DOCX 举报

聚类算法实验
1、数据集 Iris Data Set
Iris Data Set 是一个用于区分分析(discriminant analysis)的多变量数据集。该数据集中
的数据是由鸢尾属植物的三种花——Setosa、Versicolor与 Virginica——的测量结果所组成,
数据集中共包含 150 组数据信息,每一类别植物有 50 组数据。每种花的特征用 5 种属性描
述:
① 萼片长度 sepal length(厘米)
② 萼片宽度 sepal width(厘米)
③ 花瓣长度 petal length(厘米)
④ 花瓣宽度 petal width(厘米)
⑤ 类——Setosa、Versicolor、Virginica
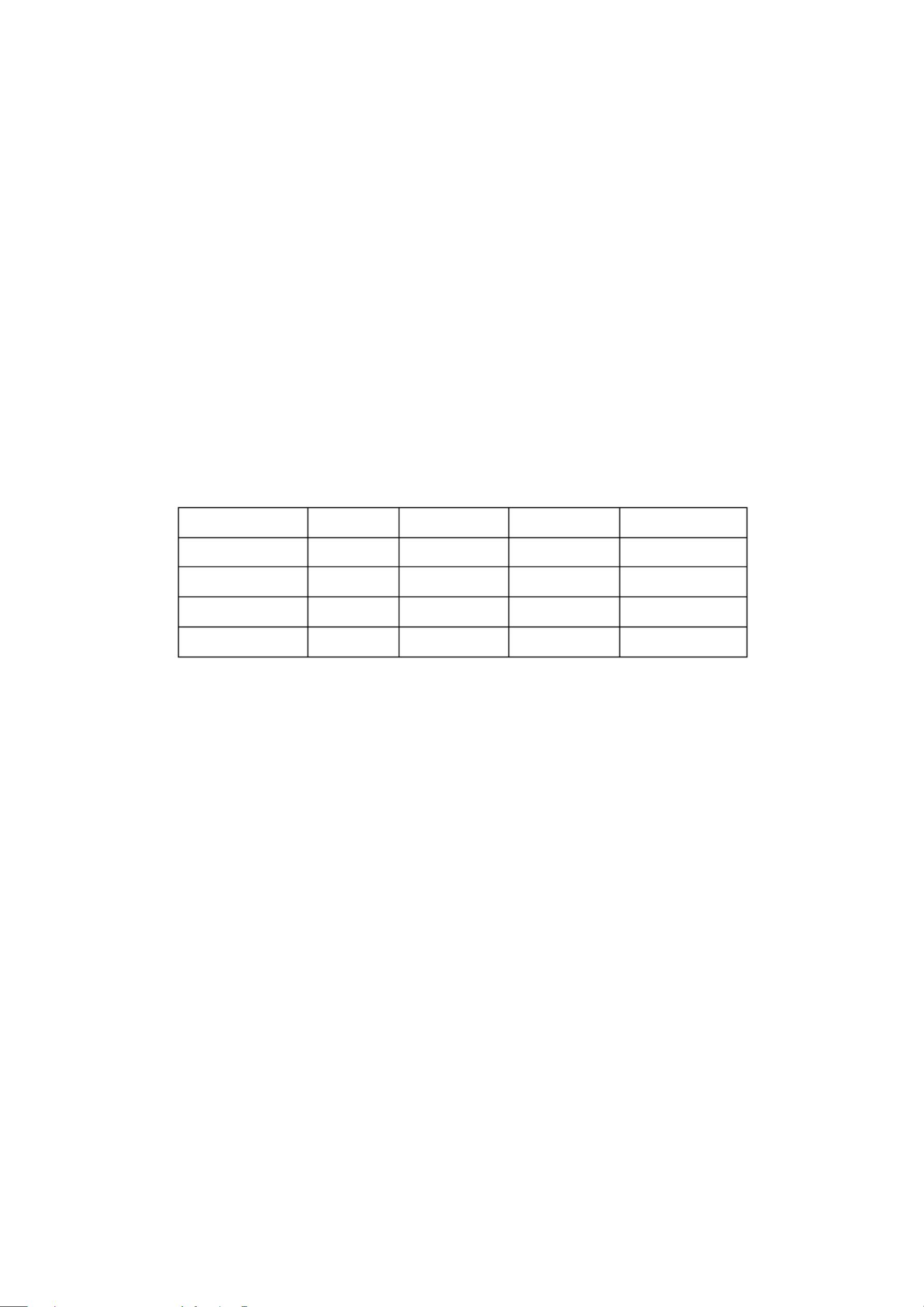
在数据集的分析文件中给出了该数据集的一些统计摘要,简要内容如下:
最小
4.3
最大
7.9
平均
5.84
3.05
3.76
1.20
类相关度
0.7826
萼片长度
萼片宽度
花瓣长度
花瓣宽度
0.1
2.5
0.9565
2、数据挖掘——数据预处理
现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘
结果差强人意。为了提前数据挖掘的质量产生了数据预处理技术。
数据预处理有多种方法:数据清理,数据集成,数据变换,数据归约等。这些数据处理
技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量,降低实际挖掘所需要的时间。
(1)数据清理
首先是处理空缺值,比如:Iris Data Set 中某一项数据的花瓣长度 petal length 项没有记
录,就要对该项进行处理。然后是处理噪声数据,通过考察周围的值来平滑存储数据的值。
最后是处理不一致数据。对以上三种流程的主要方法是纸上记录、人工的加以更正等。
(2)数据集成
即由多个数据存储合并数据。
(3)数据变换
将数据转换成适用于数据挖掘的形式。
(4)数据归约
数据挖掘时往往数据量非常大,在少量数据上进行挖掘分析需要很长的时间,数据归约
技术可以用来得到数据集的归约表示,它小得多,但仍然接近于保持原数据的完整性,并结
果与归约前结果相同或几乎相同。
资源评论













