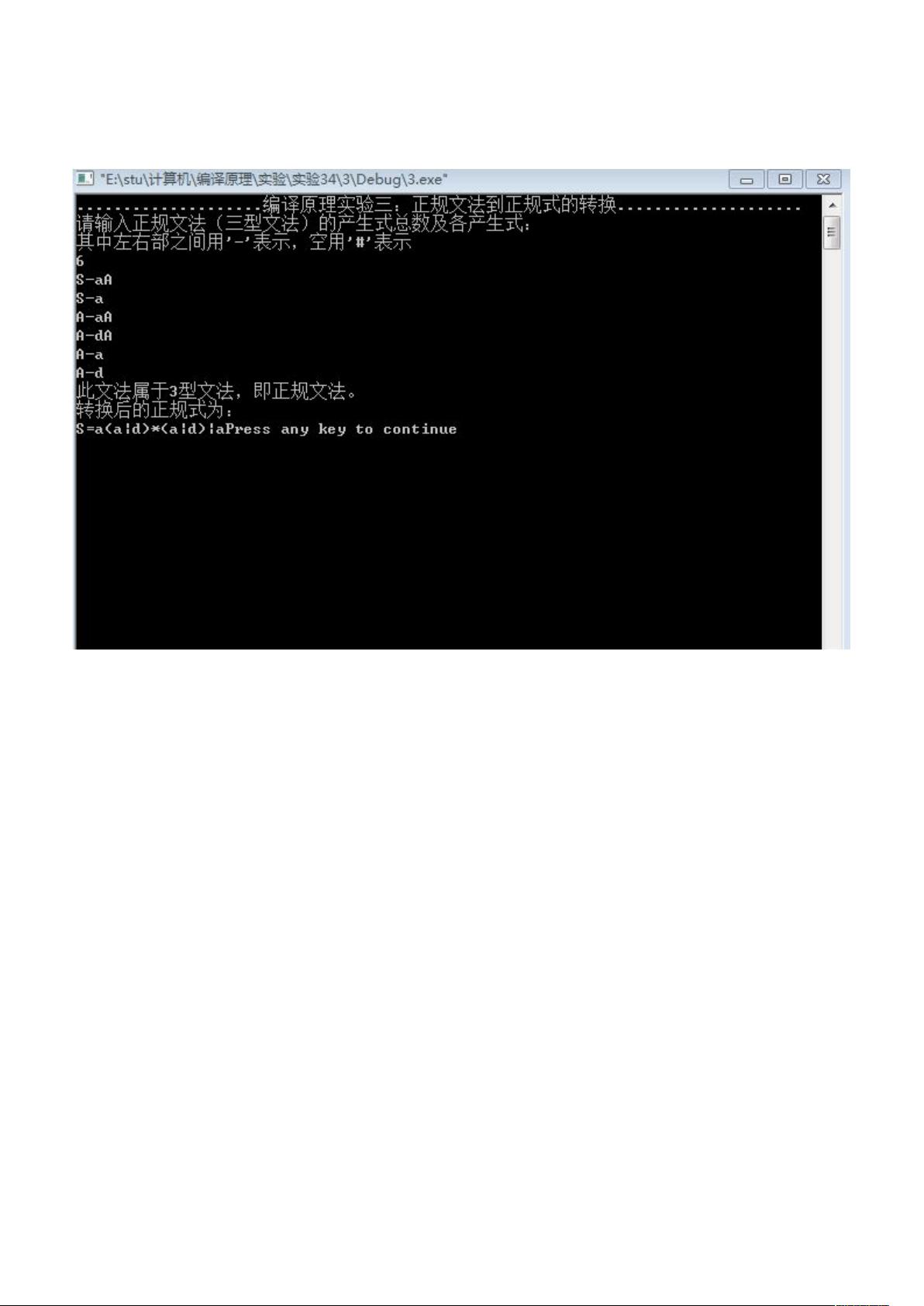
实验三:正规文法到正规式的转换
一:要求
输入任意的正规文法,输出相应的正规式
二:实验目的
1. 熟练掌握正规文法到正规式的转换规则
2. 理解正规文法和正规式的等价性
三:实验原理
1.一个正规语言可以由正规文法定义,也可以由正规式定义,对任
意一个正规文法,存在一个定义同一个语言的正规式,反之,对每
个正规式,存在生成同一个语言的正规文法
2 正规文法与正规式的转换规则:
1. A-〉xB,B->y 则:A=xy
2.A-〉xA,A->y 则:A-〉x*y
3.A-〉x,A-〉y 则:A=x|y
四:数据结构与算法