大数据Hadoop、MapReduce、Hive项目实践
需积分: 5 141 浏览量
2023-11-09
10:24:20
上传
评论 1
收藏 18.63MB DOCX 举报


大数据 Hadoop、MapReduce、Hive 项目实
践
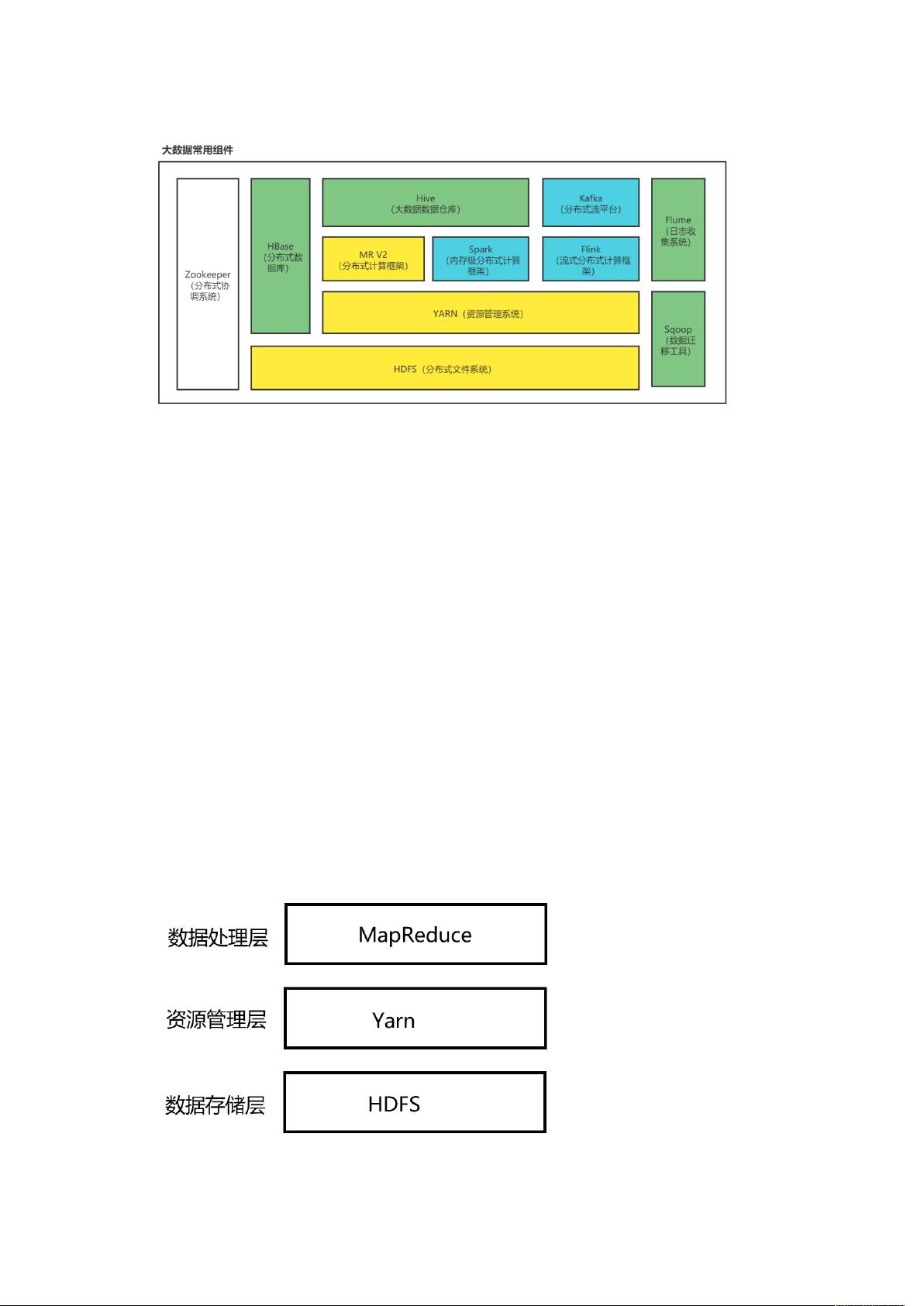
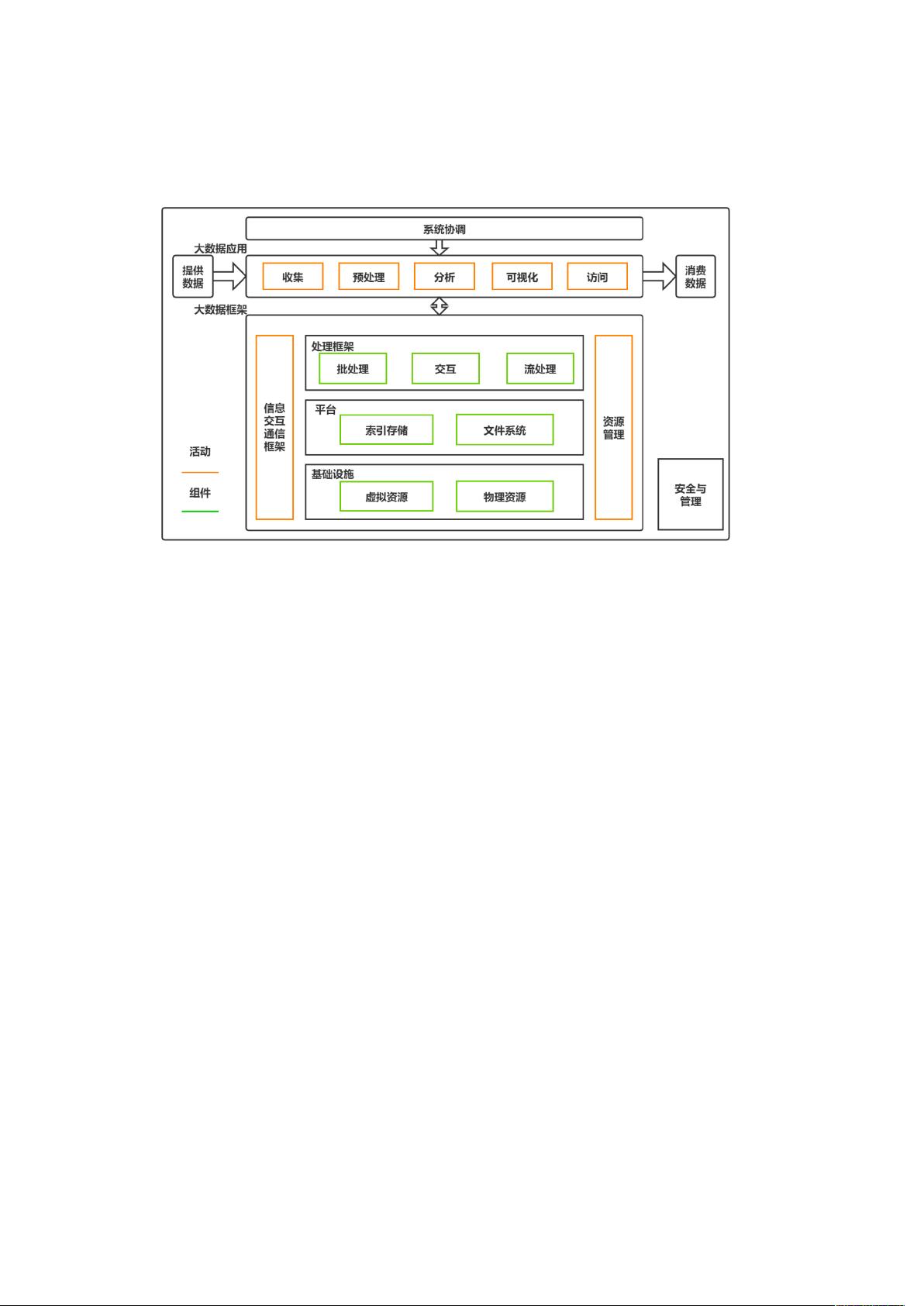
一.大数据概述
1.1. 大数据概念
而所谓的大数据,就是指大量(Volume),多样(Variety),快速(Velocity),价值
密度低(Value)的数据,这四个特性也被称为大数据的 4V 特性,传统数据库面对此类数据
遇到全面挑战,才使得大数据技术飞速发展。
1.2. 大数据的意义
1.2.1.企业之所以要使用大数据,归根结底还是因为需求,业
务需求;
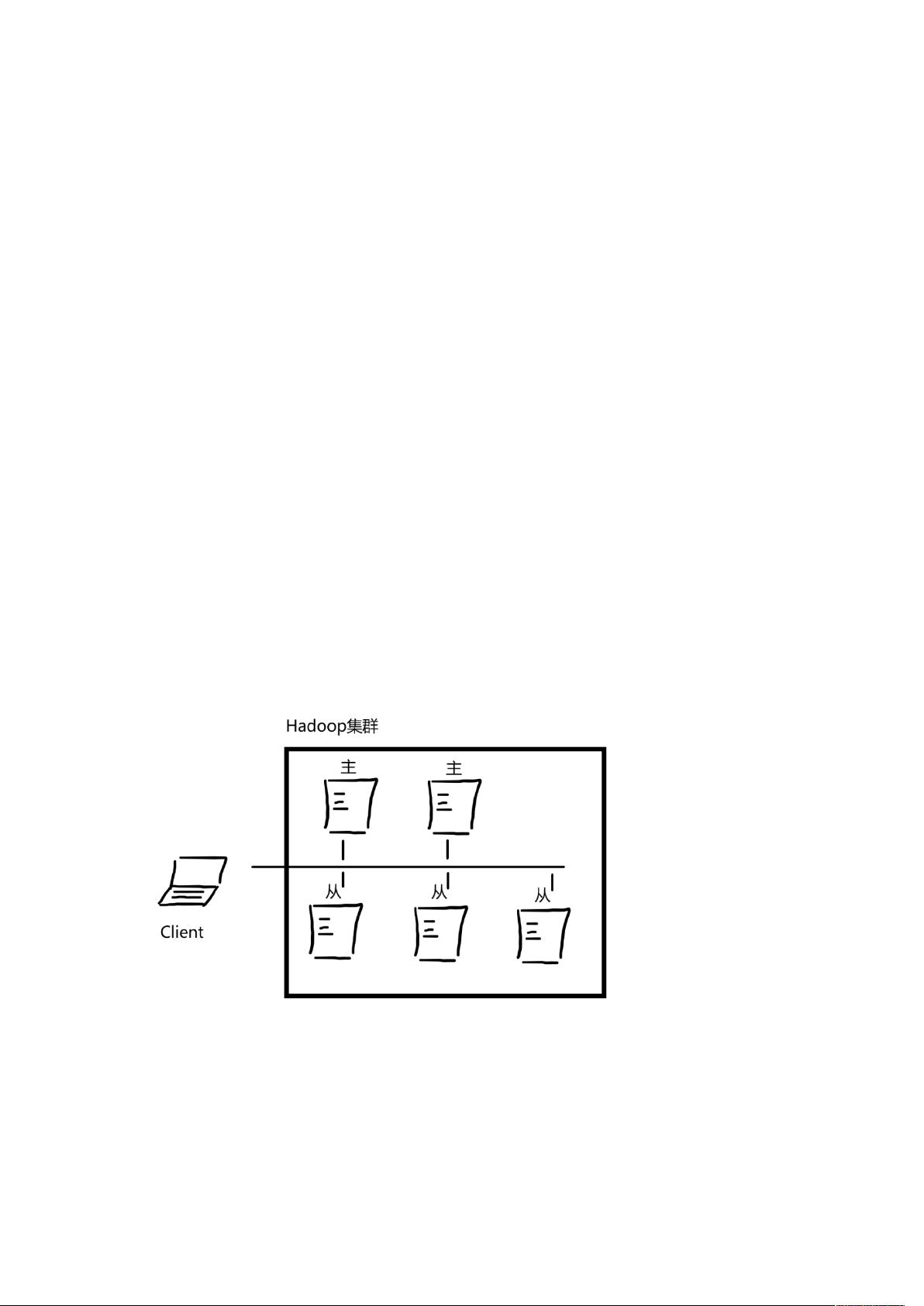
企业切换至大数据平台,一种可能是为了解决现有的 RDBMS(关系型数据库管理系统)的
瓶颈,无论是存储量瓶颈还是效率瓶颈;另一种可能是为了支持新的业务需求,很多新需求
无论从数据量级、数据种类还是处理方式上都不是旧有数据环境能够满足的,所以才需要新
的数据环境。
e.g.

剩余395页未读,继续阅读
资源评论













