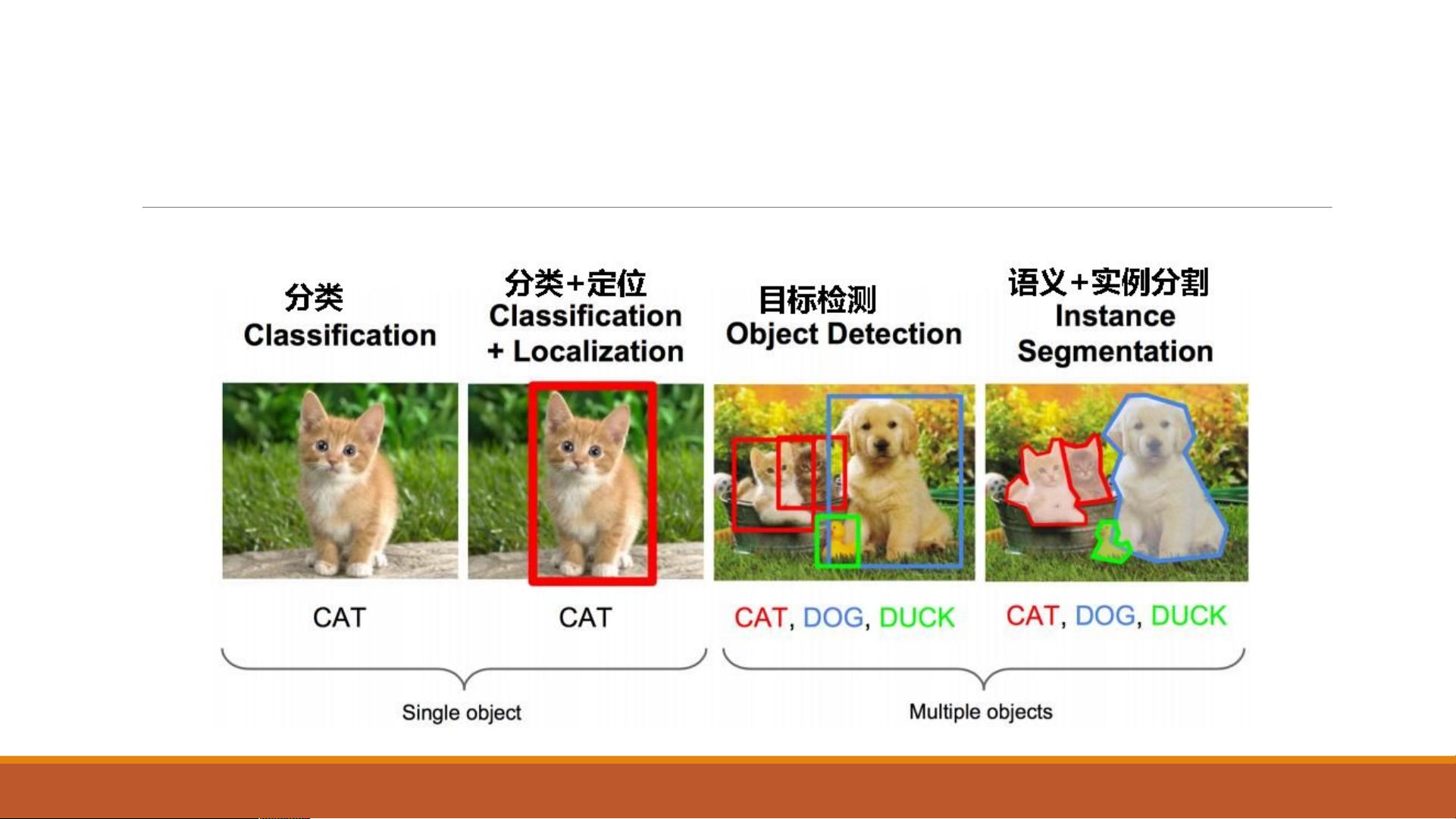
《机器视觉》郑东强的课程中,第六章主要探讨了经典的目标检测网络,特别是针对目标检测的关键技术。目标检测不仅需要识别出图像中的物体,还需要确定它们的位置、大小和长宽比,这通常涉及五个参数。传统的全连接神经网络在输入维度不高的情况下可以用于分类,但对于具有多维输出的目标检测任务,全连接网络则不再适用。
卷积神经网络(CNN)在目标检测中扮演了重要角色,因为它能够处理图像的空间信息。然而,设计目标检测的输出结构是个挑战。不同于分类任务只需要输出类别,目标检测还需要包括物体的位置信息。因此,目标检测任务通常会结合分类和回归,既要识别物体类别,也要预测物体框的坐标。
语义分割任务关注的是图像的像素级分类,而实例分割则更进一步,区分同一类别的不同实例。在目标检测中,关键在于如何将无限可能的物体转化为有限的预测输出,同时保持预测的准确性和对应性。
YOLO(You Only Look Once)v1是一种快速的目标检测框架,它的设计思路是通过网格布局来预测物体。每个网格cell负责预测B个边界框(bounding box),每个框包含位置信息以及一个confidence值,表示框内存在物体的概率。如果物体中心落在某个网格中,那么该网格就负责预测该物体,这是正样本分配的原则。每个网格cell预测的边界框还需要回归自身的精确位置,同时附带预测物体的类别概率。
YOLO v1的网络结构基于GoogLeNet,并添加了两个全连接层。尽管这种方法简化了网络,但缺乏特征金字塔,无法很好地处理不同尺度的物体,对于小物体的检测精度较低,且不解决重叠物体的问题。此外,YOLO v1的损失函数计算涉及到样本分配,对于没有物体的网格,其box的confidence会被推向0,这可能导致网络训练的不稳定。
在测试阶段,YOLO v1通过将每个网格预测的类别信息与边界框的confidence信息相乘,得到每个边界框的class-specific confidence score。通过设定阈值,过滤掉低得分的框,然后进行非极大值抑制(NMS)处理,以消除重叠的检测框,最终得到检测结果。
YOLO v1的实现细节包括每个网格cell预测2个边界框,每个框都有类别信息和坐标信息。在筛选过程中,先根据confidence score排序,然后应用NMS去除高度重叠的框,直至处理所有框。坐标信息通过offset归一化到0-1之间,而classification error和localization error同等重要可能导致网络训练不均衡。
YOLO v1是一个创新性的目标检测模型,通过网格化策略和confidence score的计算方法,实现了快速而有效的目标检测。然而,它也存在对小物体检测不准确、不解决重叠物体等问题,这些问题在后续的YOLO版本中得到了改进。理解这些细节对于深入研究和优化目标检测算法至关重要。