实验三:K 均值算法和模糊 C 均值算法
1 问题描述
编程实现 K‐means 算法和 FCM 算法,并对比两者的性能,要求:
1. 查阅无监督聚类的评价标准有哪些,选择其中一个标准作为后续试验的验证指标。
2. 在 sonar 和 Iris 数据上分别验证两种聚类算法。
2 数据集说明
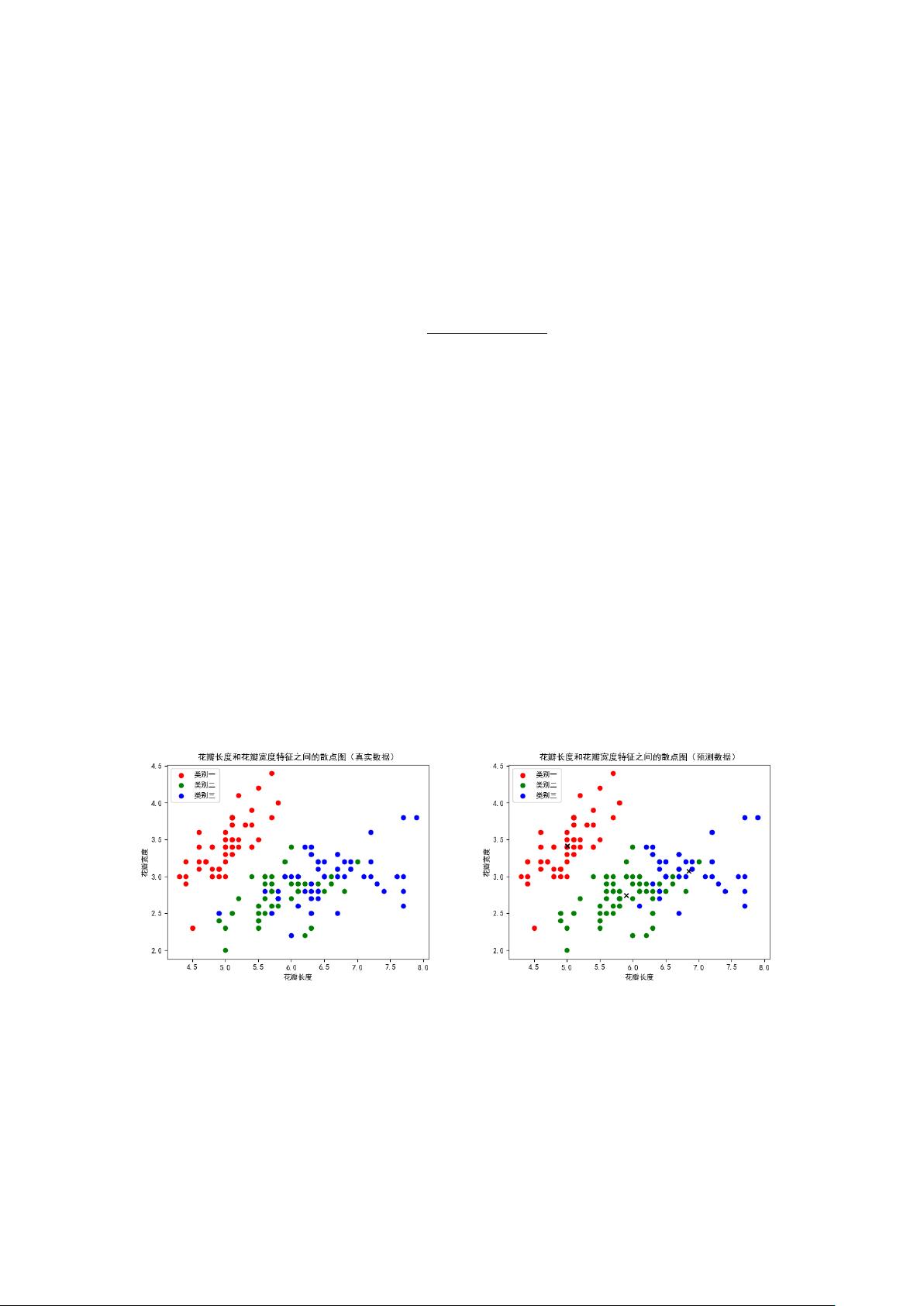
2.1 Iris 数据集
Iris 数据集中包含了 3 类鸢尾花特征数据。每一类分别有 50 个样本,每条样本有 4 个维度的特征数
据(花萼长度,花萼宽度,花瓣长度,花瓣宽度)。
2.2 Sonar 数据集
Sonar 数据集,通过声纳从不同角度返回的强度来预测目标是岩石还是矿井,其中 R 类代表岩石,M
类代表矿井。共有 208 个样本,60 个维度,2 个类别。
3 K 均值算法
3.1 算法原理
K 均值聚类算法是应用最广泛的基于划分的聚类算法之一,适用于处理大样本数据。它是一种典型的
基于相似性度量的方法, 目标是根据输入参数 K 将数据集划分为 K 簇。由于初始值、相似度、聚类均值
计算策略的不同,因而有很多种 K 均值算法的变种。在数据分布接近球体的情况下,K 均值算法具有较
好的聚类效果。
算法目标:使得各个数据与其对应聚类中心点的误差平方和最小。
J =
k
X
i
=1
J
i
=
k
X
i
=1
X
x∈C
i
∥x − m
i
∥
2
式中,J
i
为第 i 类聚类的目标函数,k 为聚类个数,x 是划分到类 C
i
的样本。
m
1
, …, m
k
是类 C
1
, …, C
k
的质心。
m
i
=
1
N
i
X
x∈C
i
x
3.2 算法流程
Step 1:
初始化:随机选择
k
个样本点,并将其视为各聚类的初始中心
m
1
,
…
, m
k
;
Step 2: 按照最小距离法则逐个将样本 x 划分到以聚类中心 m
1
, …, m
k
为代表的 k 个类 C
1
, …, C
k
中;
Step 3: 计算聚类准则函数 J,重新计算 k 个类的聚类中心 m
1
, …, m
k
;
Step 4: 重复 Step2 和 Step3 直到聚类中心 m
1
, …, m
k
无改变或目标函数 J 不减小。
4 模糊 C 均值算法
4.1 算法原理
K 均值算法属于硬聚类算法,它把数据点划分到确切的某一聚类中。而在模糊聚类亦称软聚类中,数
据点则可能归属于不止一个聚类中,并且这些聚类与数据点通过一个成员水平 (实际上类似于模糊集合中
1