
# 手把手教你用Unet做医学图像分割
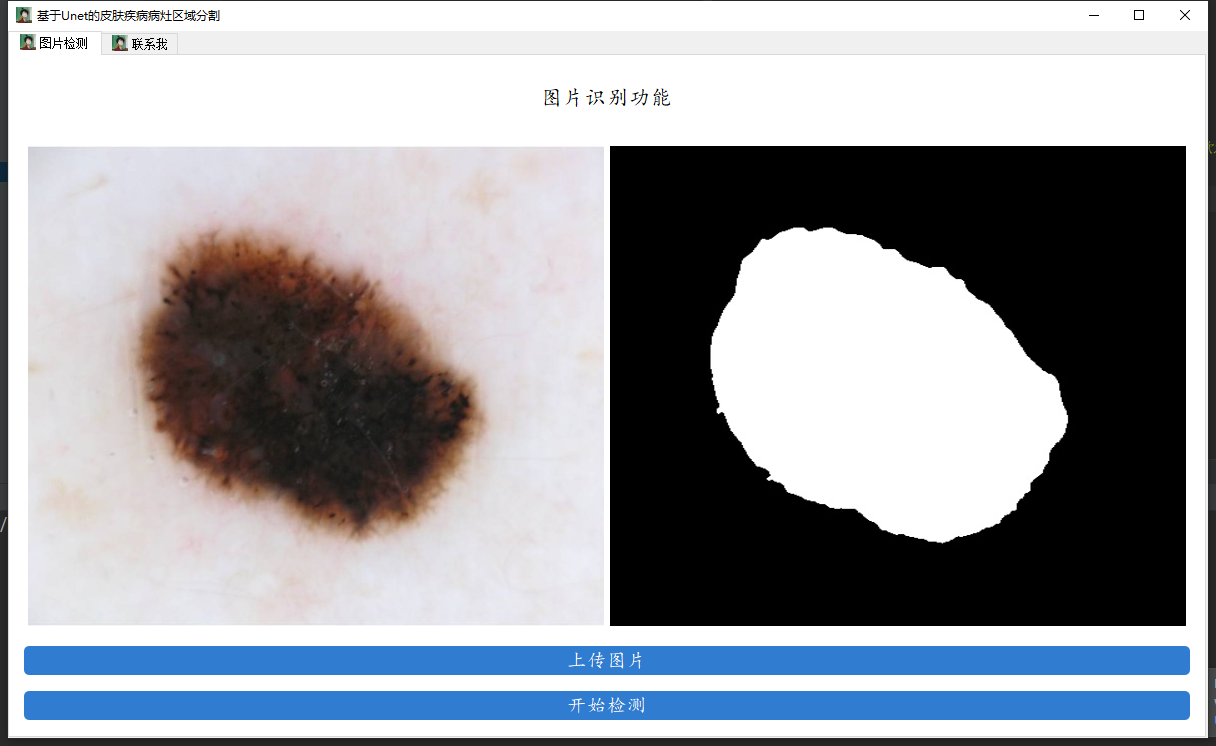
我们用Unet来做医学图像分割。我们将会以皮肤病的数据作为示范,训练一个皮肤病分割的模型出来,用户输入图像,模型可以自动分割去皮肤病的区域和正常的区域。废话不多说,先上效果,左侧展示是原始图片,右侧是分割结果。
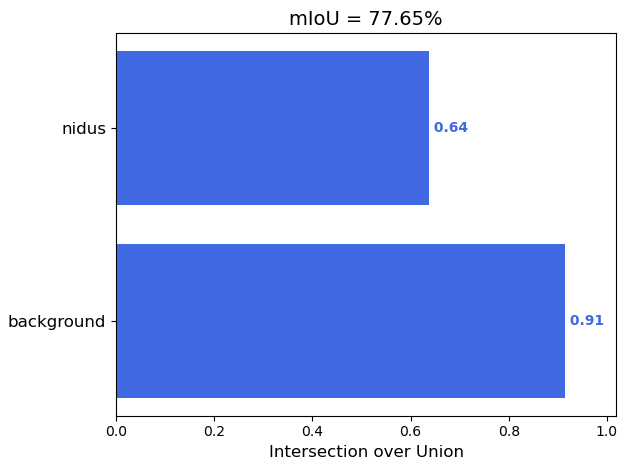
考虑到同学们的论文需要,我这里还做了一些指标图,大家可以放在文章里增加篇幅
## 算法原理介绍
> 论文地址:https://arxiv.org/pdf/1505.04597.pdf
>
> 算法解析:[U-Net原理分析与代码解读 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/150579454)
Unet 发表于 2015 年,属于 FCN 的一种变体。Unet 的初衷是为了解决生物医学图像方面的问题,由于效果确实很好后来也被广泛的应用在语义分割的各个方向,比如卫星图像分割,工业瑕疵检测等。
Unet 跟 FCN 都是 Encoder-Decoder 结构,结构简单但很有效。Encoder 负责特征提取,你可以将自己熟悉的各种特征提取网络放在这个位置。由于在医学方面,样本收集较为困难,作者为了解决这个问题,应用了图像增强的方法,在数据集有限的情况下获得了不错的精度。
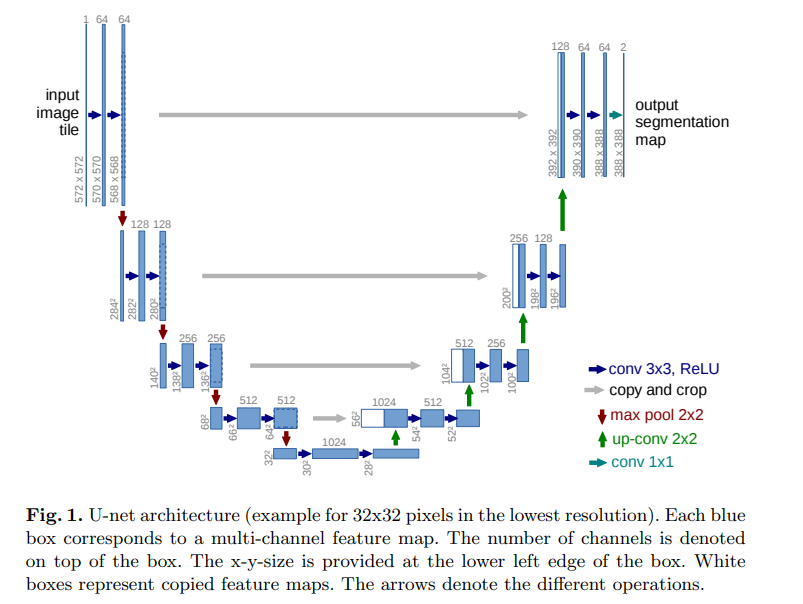
如上图,Unet 网络结构是对称的,形似英文字母 U 所以被称为 Unet,在一些类别较少的数据集上,一般使用unet来做语义分割,尤其是在一些二分类的任务上,不仅仅模型比较小,而且在精度上也比较高。
更加详细的原理介绍大家可以参考原文以及大佬们在知乎和csdn上的解答,我在这里就不多做赘述了。
## 配置环境
不熟悉pycharm的anaconda的小伙伴请先看这篇csdn博客,了解pycharm和anaconda的基本操作
[如何在pycharm中配置anaconda的虚拟环境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda](https://blog.csdn.net/ECHOSON/article/details/117220445)
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
```bash
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
```
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
```bash
conda create -n unet python==3.8.5
conda activate unet
```
### pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是unet在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。
GPU版本安装的具体步骤可以参考这篇文章:[2021年Windows下安装GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客](https://blog.csdn.net/ECHOSON/article/details/118420968)
需要注意以下几点:
* 安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
* 30系显卡只能使用cuda11的版本
* 一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
```cmd
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
```
安装完毕之后,我们来测试一下GPU是否
### 安装unet程序所需的其他包
程序其他所需要的包我写在了`requirements.txt`文件中,大家只需要在项目目录下打开cmd,然后执行下列命令安装即可,**安装之前请确保你已经激活了虚拟环境**
```bash
pip install -r requirements.txt
```
到这里我们的环境基本已经配置完成了,你已经成功了一大半了,下面只需要按照教程完成剩下的步骤即可。
## 数据处理
数据处理部分,医学影像这块我们一般使用公开的数据集,如果没有合适的数据集大家也可以选择自己进行标注,分割相对于检测而言标注起来比较麻烦,所以能找到公开的数据集最好使用公开的数据集,这里也放一些我收集和处理好的数据集,大家有需要的可以自取。
以下面的皮肤病数据集为例,其中左侧是原始图片,右侧是标注之后的标签,因为标签有两种像素值,背景为0,皮肤病区域为1,所以我们肉眼上看到的标签图片是全黑,但是实际上这些标签文件中的值是不一样的。
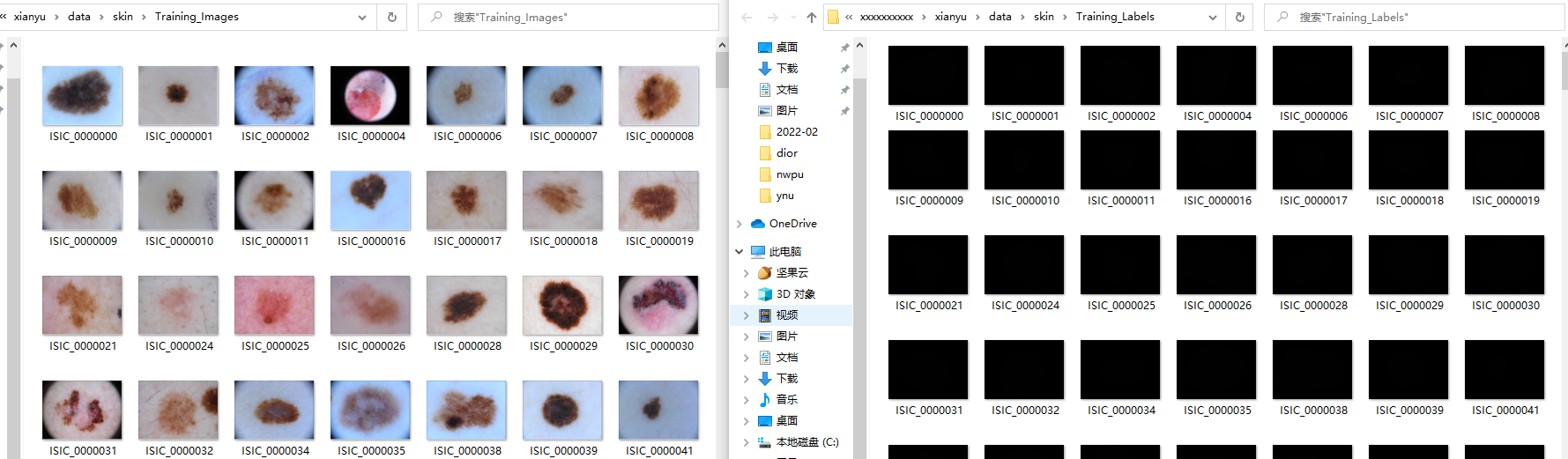
记住这里数据集的位置,后面在训练和测试的时候在代码中替换为自己本地的数据集位置。
**注:下面的内容是关于数据集的标注,如果大家已经找到合适的数据集,请自行跳过这部分的内容**
* 1.LabelMe的安装
用户在采集完用于训练、评估和预测的图片之后,需使用数据标注工具[LabelMe](https://github.com/wkentaro/labelme)完成数据标注。LabelMe支持在Windows/macOS/Linux三个系统上使用,且三个系统下的标注格式是一样。
安装的过程非常简单,大家只需要在激活虚拟环境的前提下,执行下列之类即可
```
pip install labelme
```
安装完成之后,直接在命令行中输入`labelme`即可启动
* 2.LabelMe的使用
打开终端输入`labelme`会出现LableMe的交互界面,可以先预览`LabelMe`给出的已标注好的图片,再开始标注自定义数据集。
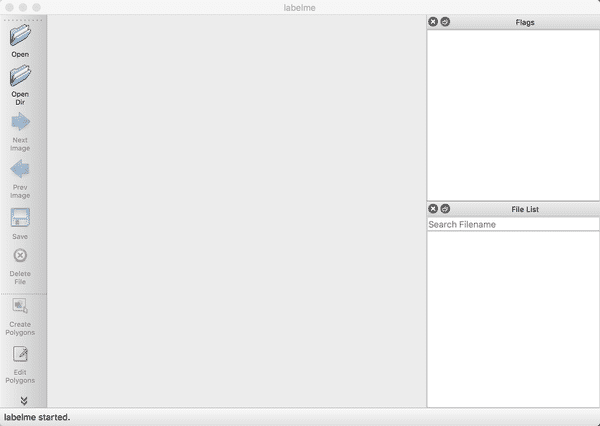
<div align="left">
<p>图1 LableMe交互界面的示意图</p>
</div>
* 预览已标注图片
终端输入`labelme`会出现LableMe的交互界面,点击`OpenDir`打开`<path/to/labelme>/examples/semantic_segmentation/data_annotated`,其中`<path/to/labelme>`为克隆下来的`labelme`的路径,打开后示意的是语义分割的真值标注。
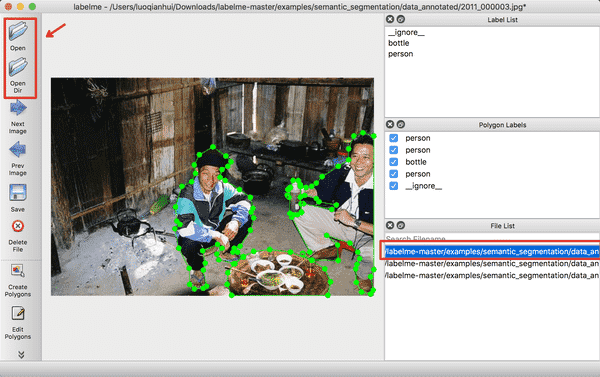
<div align="left">
<p>图2 已标注图片的示意图</p>
</div>
* 开始标注
请按照下述步骤标注数据集:
(1) 点击`OpenDir`打开待标注图片所在目录,点击`Create Polygons`,沿着目标的边缘画多边形,完成后输入目标的类别。在标注过程中,如果某个点画错了,可以按撤销快捷键可撤销该点。Mac下的撤销快捷键为`command+Z`。
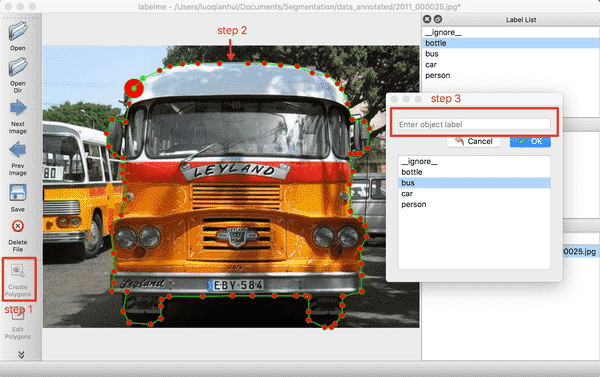
<div align="left">
<p>图3 标注单个目标的示意图</p>
</div>
(2) 右击选择`Edit Polygons`可以整体移动多边形的位置,也可以移动某个点的位置;右击选择`Edit Label`可以修改每个目标的类别。请根据自己的需要执行这一步骤,若不需要修改,可跳过。
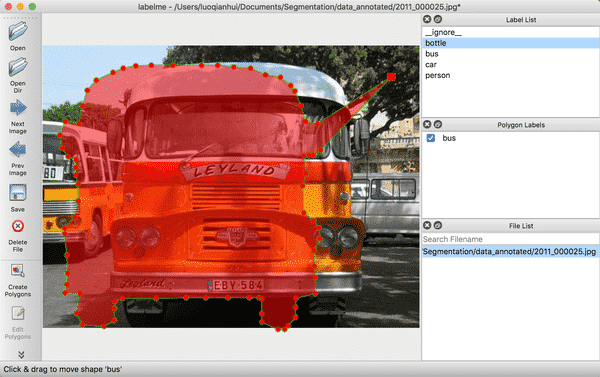
<div align="left">
<p>图4 修改标注的示意图</p>
</div>
(3) 图片中所有目标的标注都完成后,点击`Save`保存json文件,**请将json文件和图片放在
 unet_master.zip (77个子文件)
unet_master.zip (77个子文件)  新建文本文档 (2).txt 0B
新建文本文档 (2).txt 0B unet_master
unet_master  labelme2seg.py 1KB predict.py 2KB utils dataset.py 2KB utils_metrics.py 9KB gen_split.py 2KB label2png.py 1KB __pycache__ dataset.cpython-37.pyc 2KB utils_metrics.cpython-37.pyc 6KB utils_metrics.cpython-38.pyc 6KB dataset.cpython-38.pyc 2KB data_remove_seg.py 730B .idea unet_42-new.iml 483B misc.xml 194B inspectionProfiles Project_Default.xml 510B profiles_settings.xml 174B modules.xml 274B .gitignore 176B uinnnnnnnn 9KB model __init__.py 0B unet_parts.py 2KB unet_model.py 1KB __pycache__ unet_parts.cpython-37.pyc 3KB unet_model.cpython-38.pyc 1KB unet_parts.cpython-38.pyc 3KB unet_model.cpython-37.pyc 1KB __init__.cpython-37.pyc 141B __init__.cpython-38.pyc 161B requirements.txt 143B images tmp
labelme2seg.py 1KB predict.py 2KB utils dataset.py 2KB utils_metrics.py 9KB gen_split.py 2KB label2png.py 1KB __pycache__ dataset.cpython-37.pyc 2KB utils_metrics.cpython-37.pyc 6KB utils_metrics.cpython-38.pyc 6KB dataset.cpython-38.pyc 2KB data_remove_seg.py 730B .idea unet_42-new.iml 483B misc.xml 194B inspectionProfiles Project_Default.xml 510B profiles_settings.xml 174B modules.xml 274B .gitignore 176B uinnnnnnnn 9KB model __init__.py 0B unet_parts.py 2KB unet_model.py 1KB __pycache__ unet_parts.cpython-37.pyc 3KB unet_model.cpython-38.pyc 1KB unet_parts.cpython-38.pyc 3KB unet_model.cpython-37.pyc 1KB __init__.cpython-37.pyc 141B __init__.cpython-38.pyc 161B requirements.txt 143B images tmp  tmp_upload.png 1.63MB
tmp_upload.png 1.63MB tmp_upload.jpg 49KB single_result_vid.jpg 54KB tmp_upload.jpeg 21KB single_result.jpg 15KB upload_show_result.jpg 66KB up.jpeg 21KB ISIC_0000000.jpg 49KB right.jpeg 27KB 111 ISIC_0000000.jpg 49KB ISIC_0000000_res.png 5KB ISIC_0000000_res.png 5KB UI lufei.png 216KB logo.jpeg 33KB up.jpeg 28KB qq.png 151KB right.jpeg 25KB testdata jsons Case-5-U-10-0.json 79KB Case-2-U-2-3.json 90KB Case-4-U-8-1.json 85KB Case-3-U-5-0.json 84KB Case-5-U-10-1.json 83KB Case-4-U-8-0.json 84KB Case-3-U-5-2.json 83KB Case-3-U-5-3.json 81KB Case-1-U-1-1.json 65KB Case-2-U-2-2.json 78KB labels Case-3-U-5-0.png 4KB Case-2-U-2-3.png 3KB Case-4-U-8-0.png 3KB Case-4-U-8-1.png 2KB Case-3-U-5-3.png 3KB Case-1-U-1-1.png 3KB Case-3-U-5-2.png 4KB Case-2-U-2-2.png 3KB Case-5-U-10-0.png 3KB Case-5-U-10-1.png 3KB train.py 2KB ui.py 8KB test.py 4KB results Precision.png 15KB mPA.png 14KB Recall.png 14KB confusion_matrix.csv 74B mIoU.png 15KB README.md 13KB
tmp_upload.jpg 49KB single_result_vid.jpg 54KB tmp_upload.jpeg 21KB single_result.jpg 15KB upload_show_result.jpg 66KB up.jpeg 21KB ISIC_0000000.jpg 49KB right.jpeg 27KB 111 ISIC_0000000.jpg 49KB ISIC_0000000_res.png 5KB ISIC_0000000_res.png 5KB UI lufei.png 216KB logo.jpeg 33KB up.jpeg 28KB qq.png 151KB right.jpeg 25KB testdata jsons Case-5-U-10-0.json 79KB Case-2-U-2-3.json 90KB Case-4-U-8-1.json 85KB Case-3-U-5-0.json 84KB Case-5-U-10-1.json 83KB Case-4-U-8-0.json 84KB Case-3-U-5-2.json 83KB Case-3-U-5-3.json 81KB Case-1-U-1-1.json 65KB Case-2-U-2-2.json 78KB labels Case-3-U-5-0.png 4KB Case-2-U-2-3.png 3KB Case-4-U-8-0.png 3KB Case-4-U-8-1.png 2KB Case-3-U-5-3.png 3KB Case-1-U-1-1.png 3KB Case-3-U-5-2.png 4KB Case-2-U-2-2.png 3KB Case-5-U-10-0.png 3KB Case-5-U-10-1.png 3KB train.py 2KB ui.py 8KB test.py 4KB results Precision.png 15KB mPA.png 14KB Recall.png 14KB confusion_matrix.csv 74B mIoU.png 15KB README.md 13KB unet原文.pdf 1.57MB 切换镜像.txt 348B
unet原文.pdf 1.57MB 切换镜像.txt 348B资源评论



手把手教你学AI
- 粉丝: 9468
- 资源: 4815









最新资源
- Matlab实现GWO-TCN-Multihead-Attention灰狼算法优化时间卷积网络结合多头注意力机制多变量时间序列预测(含完整的程序,GUI设计和代码详解)
- C# 压缩辅助类实例源码
- Arduino IDE esp32开发板 3.1.0 离线安装包 再也不怕网络慢
- Matlab实现GRO-CNN-BiLSTM-Attention淘金算法优化卷积神经网络-双向长短期记忆网络结合注意力机制多变量时间序列预测(含完整的程序,GUI设计和代码详解)
- Matlab实现KPCA-EBWO-SVM核主成分分析和改进的白鲸优化算法优化支持向量机分类预测(含完整的程序,GUI设计和代码详解)
- Matlab实现RIME-HKELM霜冰算法优化混合核极限学习机多变量回归预测(含完整的程序,GUI设计和代码详解)
- Matlab实现CPO-LSSVM冠豪猪算法优化最小二乘支持向量机多变量回归预测(含完整的程序,GUI设计和代码详解)
- Matlab实现ZOA-CNN-LSTM-Attention斑马优化卷积长短期记忆神经网络注意力机制的数据分类预测(含完整的程序,GUI设计和代码详解)
- Matlab实现基于RIME-DBSCAN的数据聚类可视化(含完整的程序,GUI设计和代码详解)
- C# 链接数据库ODBC
- Matlab实现改进黑猩猩优化算法SLWCHOA与多个基准函数对比与秩和检验(含完整的程序,GUI设计和代码详解)
- 冒泡排序模版(c++)
- ArcGIS教程008:三维地形+雨水淹没分析教程数据
- C# 操作Access数据库
- 大一C语言项目实践-小游戏集成开发系统
- 选择排序模版(c++)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


