Learning Transferable Visual Models From Natural Language Supervision
Alec Radford
* 1
Jong Wook Kim
* 1
Chris Hallacy
1
Aditya Ramesh
1
Gabriel Goh
1
Sandhini Agarwal
1
Girish Sastry
1
Amanda Askell
1
Pamela Mishkin
1
Jack Clark
1
Gretchen Krueger
1
Ilya Sutskever
1
Abstract
State-of-the-art computer vision systems are
trained to predict a fixed set of predetermined
object categories. This restricted form of super-
vision limits their generality and usability since
additional labeled data is needed to specify any
other visual concept. Learning directly from raw
text about images is a promising alternative which
leverages a much broader source of supervision.
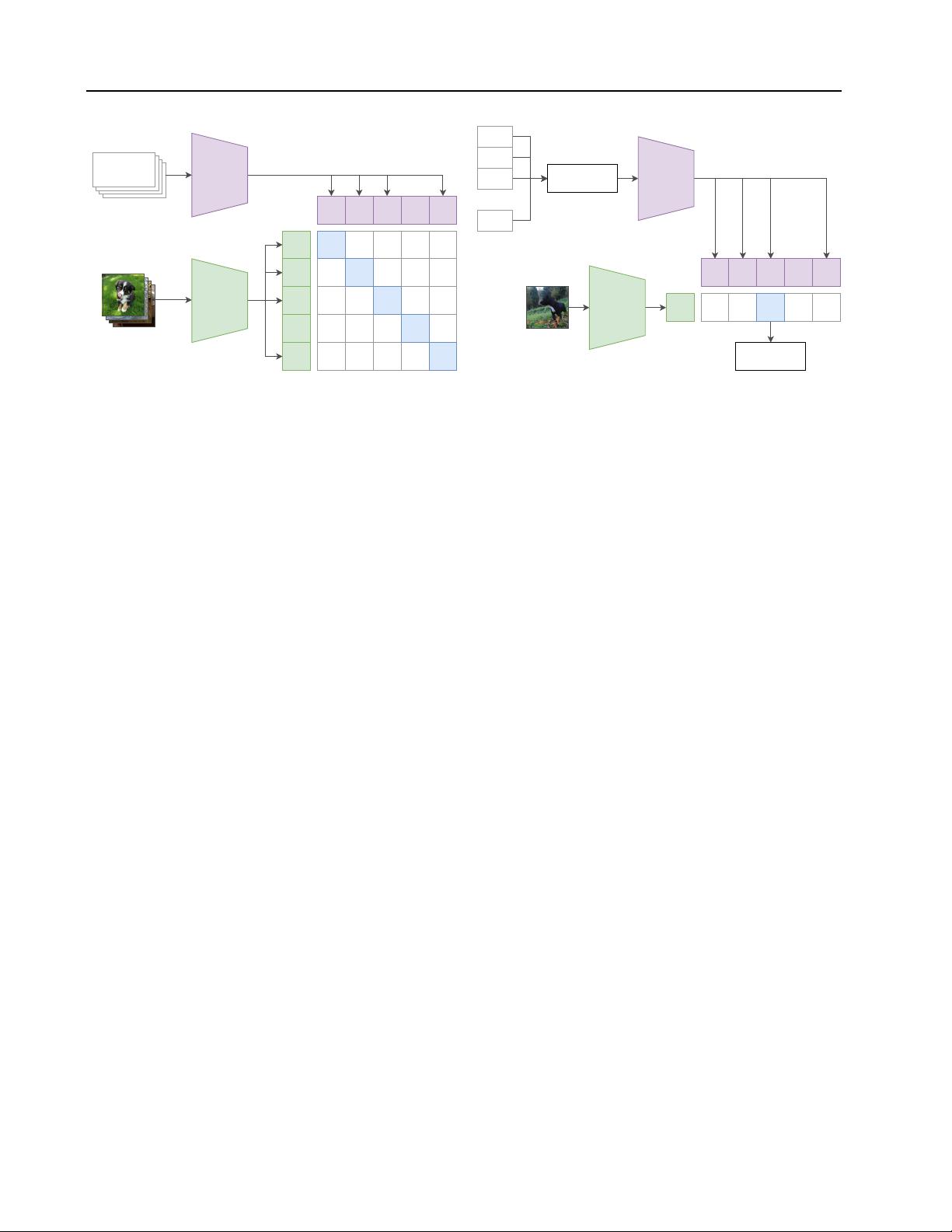
We demonstrate that the simple pre-training task
of predicting which caption goes with which im-
age is an efficient and scalable way to learn SOTA
image representations from scratch on a dataset
of 400 million (image, text) pairs collected from
the internet. After pre-training, natural language
is used to reference learned visual concepts (or
describe new ones) enabling zero-shot transfer
of the model to downstream tasks. We study
the performance of this approach by benchmark-
ing on over 30 different existing computer vi-
sion datasets, spanning tasks such as OCR, ac-
tion recognition in videos, geo-localization, and
many types of fine-grained object classification.
The model transfers non-trivially to most tasks
and is often competitive with a fully supervised
baseline without the need for any dataset spe-
cific training. For instance, we match the ac-
curacy of the original ResNet-50 on ImageNet
zero-shot without needing to use any of the 1.28
million training examples it was trained on. We
release our code and pre-trained model weights at
https://github.com/OpenAI/CLIP.
1. Introduction and Motivating Work
Pre-training methods which learn directly from raw text
have revolutionized NLP over the last few years (Dai &
Le, 2015; Peters et al., 2018; Howard & Ruder, 2018; Rad-
ford et al., 2018; Devlin et al., 2018; Raffel et al., 2019).
*
Equal contribution
1
OpenAI, San Francisco, CA 94110, USA.
Correspondence to: <{alec, jongwook}@openai.com>.
Task-agnostic objectives such as autoregressive and masked
language modeling have scaled across many orders of mag-
nitude in compute, model capacity, and data, steadily im-
proving capabilities. The development of “text-to-text” as
a standardized input-output interface (McCann et al., 2018;
Radford et al., 2019; Raffel et al., 2019) has enabled task-
agnostic architectures to zero-shot transfer to downstream
datasets removing the need for specialized output heads or
dataset specific customization. Flagship systems like GPT-3
(Brown et al., 2020) are now competitive across many tasks
with bespoke models while requiring little to no dataset
specific training data.
These results suggest that the aggregate supervision acces-
sible to modern pre-training methods within web-scale col-
lections of text surpasses that of high-quality crowd-labeled
NLP datasets. However, in other fields such as computer
vision it is still standard practice to pre-train models on
crowd-labeled datasets such as ImageNet (Deng et al., 2009).
Could scalable pre-training methods which learn directly
from web text result in a similar breakthrough in computer
vision? Prior work is encouraging.
Over 20 years ago Mori et al. (1999) explored improving
content based image retrieval by training a model to pre-
dict the nouns and adjectives in text documents paired with
images. Quattoni et al. (2007) demonstrated it was possi-
ble to learn more data efficient image representations via
manifold learning in the weight space of classifiers trained
to predict words in captions associated with images. Sri-
vastava & Salakhutdinov (2012) explored deep represen-
tation learning by training multimodal Deep Boltzmann
Machines on top of low-level image and text tag features.
Joulin et al. (2016) modernized this line of work and demon-
strated that CNNs trained to predict words in image cap-
tions learn useful image representations. They converted
the title, description, and hashtag metadata of images in the
YFCC100M dataset (Thomee et al., 2016) into a bag-of-
words multi-label classification task and showed that pre-
training AlexNet (Krizhevsky et al., 2012) to predict these
labels learned representations which preformed similarly
to ImageNet-based pre-training on transfer tasks. Li et al.
(2017) then extended this approach to predicting phrase n-
grams in addition to individual words and demonstrated the
ability of their system to zero-shot transfer to other image
arXiv:2103.00020v1 [cs.CV] 26 Feb 2021