

译者注:本文智能单元首发,译自斯坦福CS231n课程笔记image classification notes,由课程
教师Andrej Karpathy授权进行翻译。本篇教程由杜客翻译完成。ShiqingFan对译文进行了仔细
校对,提出了大量修改建议,态度严谨,帮助甚多。巩子嘉对几处术语使用和翻译优化也提出了
很好的建议。张欣等亦有帮助。
原文如下
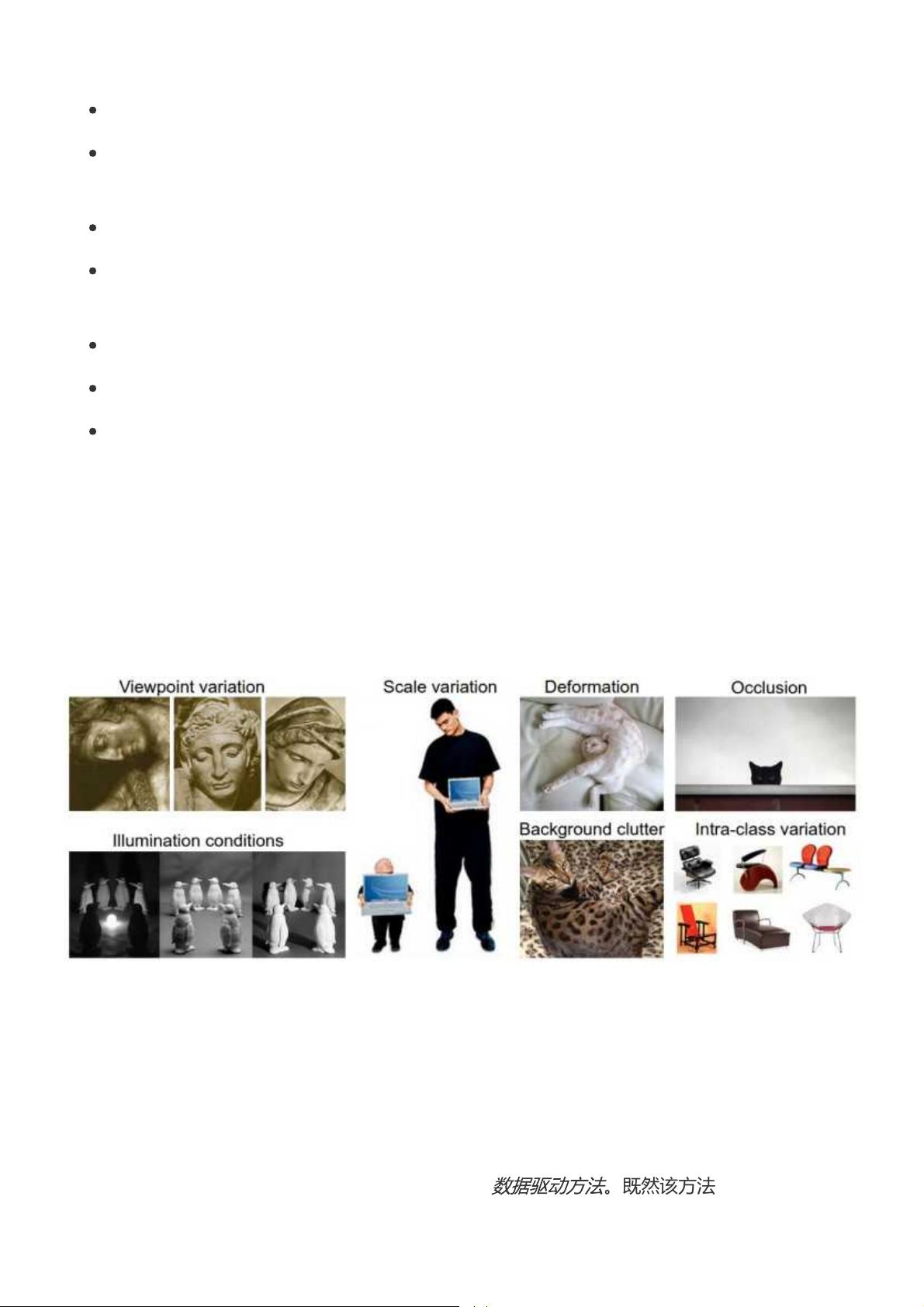
这是一篇介绍性教程,面向非计算机视觉领域的同学。教程将向同学们介绍图像分类问题和数据
驱动方法。下面是内容列表:
图像分类、数据驱动方法和流程
Nearest Neighbor分类器
k-Nearest Neighbor
译
者
注
:
上
篇翻
译
截
止
处
验证集、交叉验证集和超参数调参
Nearest Neighbor的优劣
小结
小结:应用kNN实践
拓展阅读
图像分类
CS231n课程笔记翻译:图像分类笔记(上)
杜客
· 2 年前
首发于
智能单元
写文章
登录



剩余127页未读,继续阅读
资源评论

 kongjibo2018-04-23不是特别全,但是资源质量还是不错的
kongjibo2018-04-23不是特别全,但是资源质量还是不错的












