李飞飞 CS231n 中文笔记
需积分: 22 140 浏览量
2018-08-21
22:55:56
上传
评论
收藏 1.19MB PDF 举报


CS231n
课
程
笔
记
翻
译
:
线
性
分
类
笔
记
原
文
如
下
内容列表:
线性分类器简介
线性评分函数
阐明线性分类器
损失函数
多类SVM
Softmax分类器
SVM和Softmax的比较
基于Web的可交互线性分类器原型
小结
线
性
分
类
上一篇笔记介绍了图像分类问题。图像分类的任务,就是从已有的固定分类标签集合中选择一个并分配给一张图
像。我们还介绍了k-Nearest Neighbor (k-NN)分类器,该分类器的基本思想是通过将测试图像与训练集带标签
的图像进行比较,来给测试图像打上分类标签。k-Nearest Neighbor分类器存在以下不足:
分类器必须
记
住
所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数
据集的大小很容易就以GB计。
对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
概
述
:我们将要实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络
上。这种方法主要有两部分组成:一个是
评
分函
数
(
score function
)
,它是原始图像数据到类别分值的映射。另
一个是
损
失
函
数
(
loss function
)
,它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为
一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
从
图
像
到
标
签
分
值
的
参
数
化
映
射
该方法的第一部分就是定义一个评分函数,这个函数将图像的像素值映射为各个分类类别的得分,得分高低代
表图像属于该类别的可能性高低。下面会利用一个具体例子来展示该方法。现在假设有一个包含很多图像的训练集
,每个图像都有一个对应的分类标签 。这里 并且 。这就是说,我们有N个图像
样例,每个图像的维度是D,共有K种不同的分类。
举例来说,在CIFAR-10中,我们有一个N=50000的训练集,每个图像有D=32x32x3=3072个像素,而K=10,这是
因为图片被分为10个不同的类别(狗,猫,汽车等)。我们现在定义评分函数为: ,该函数是原始
图像像素到分类分值的映射。
线
性
分
类
器
:在本模型中,我们从最简单的概率函数开始,一个线性映射:

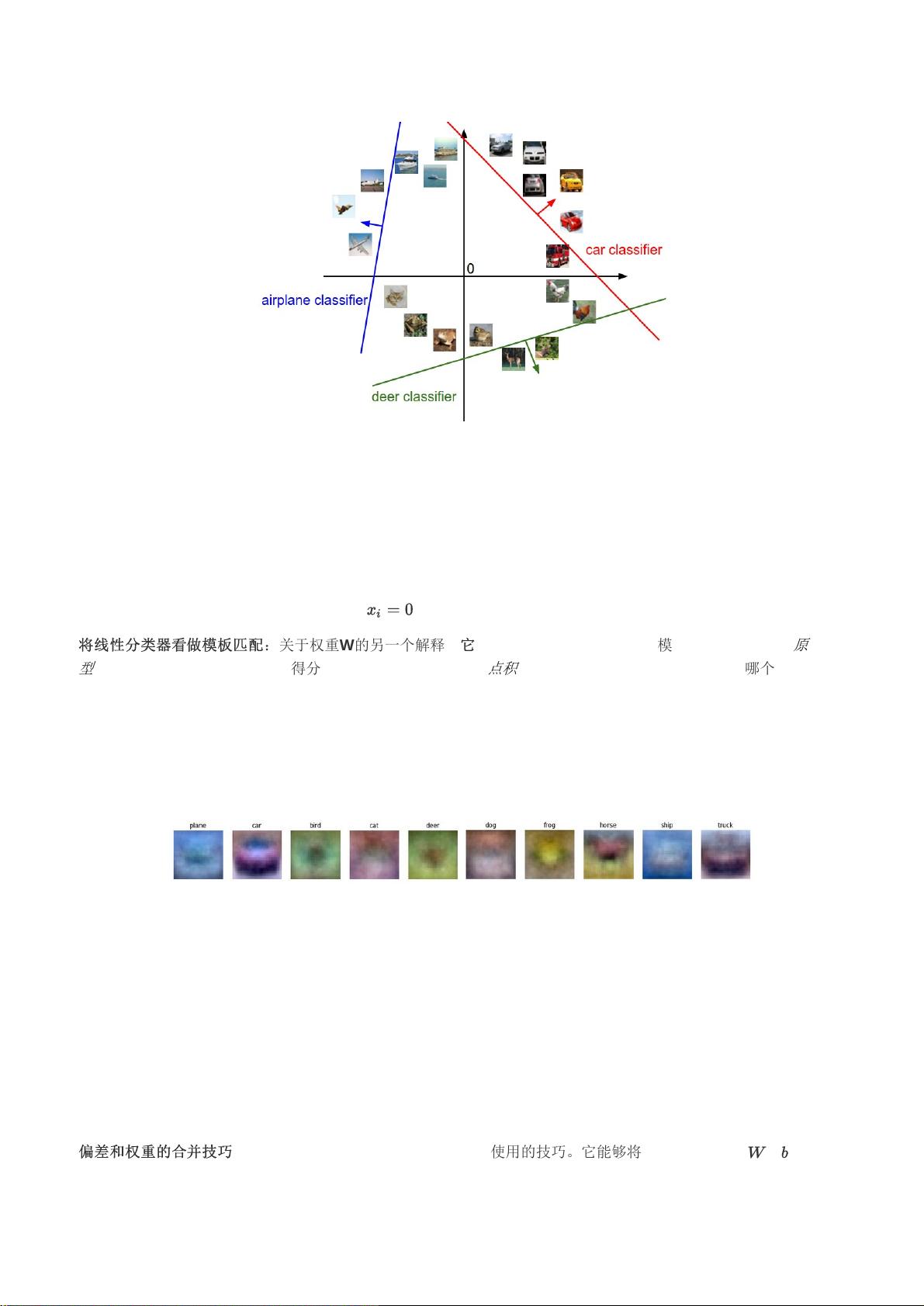
剩余10页未读,继续阅读
资源评论













