

4/23/23, 2:11 PM
Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song
https://yang-song.net/blog/2021/score/
1/22
AUTHORS AFFILIATIONS
Yang Song Stanford University
PUBLISHED
May 5, 2021
Generative Modeling by Estimating Gradients of the
Data Distribution
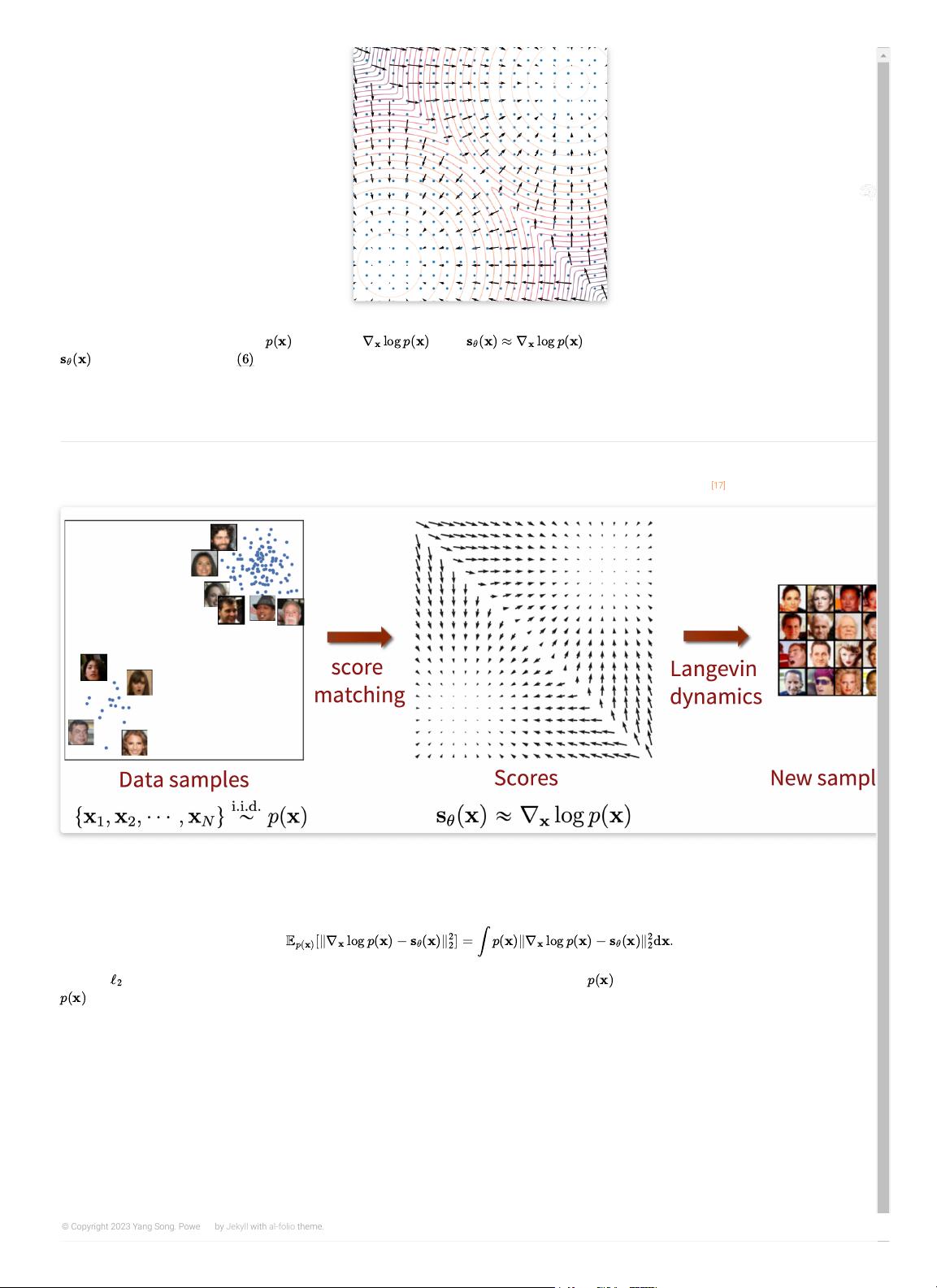
This blog post focuses on a promising new direction for generative modeling. We can learn score functions (gradients of log
probability density functions) on a large number of noise-perturbed data distributions, then generate samples with Langevin-type
sampling. The resulting generative models, often called
score-based generative models
, has several important advantages over
existing model families: GAN-level sample quality without adversarial training, exible model architectures, exact log-likelihood
computation, and inverse problem solving without re-training models. In this blog post, we will show you in more detail the intuition,
basic concepts, and potential applications of score-based generative models.
Contents
Introduction
The score function, score-based models, and score matching
Langevin dynamics
Naive score-based generative modeling and its pitfalls
Score-based generative modeling with multiple noise perturbations
Score-based generative modeling with stochastic differential equations (SDEs)
Perturbing data with an SDE
Reversing the SDE for sample generation
Estimating the reverse SDE with score-based models and score matching
How to solve the reverse SDE
Probability ow ODE
Controllable generation for inverse problem solving
Connection to diffusion models and others
Concluding remarks
Introduction
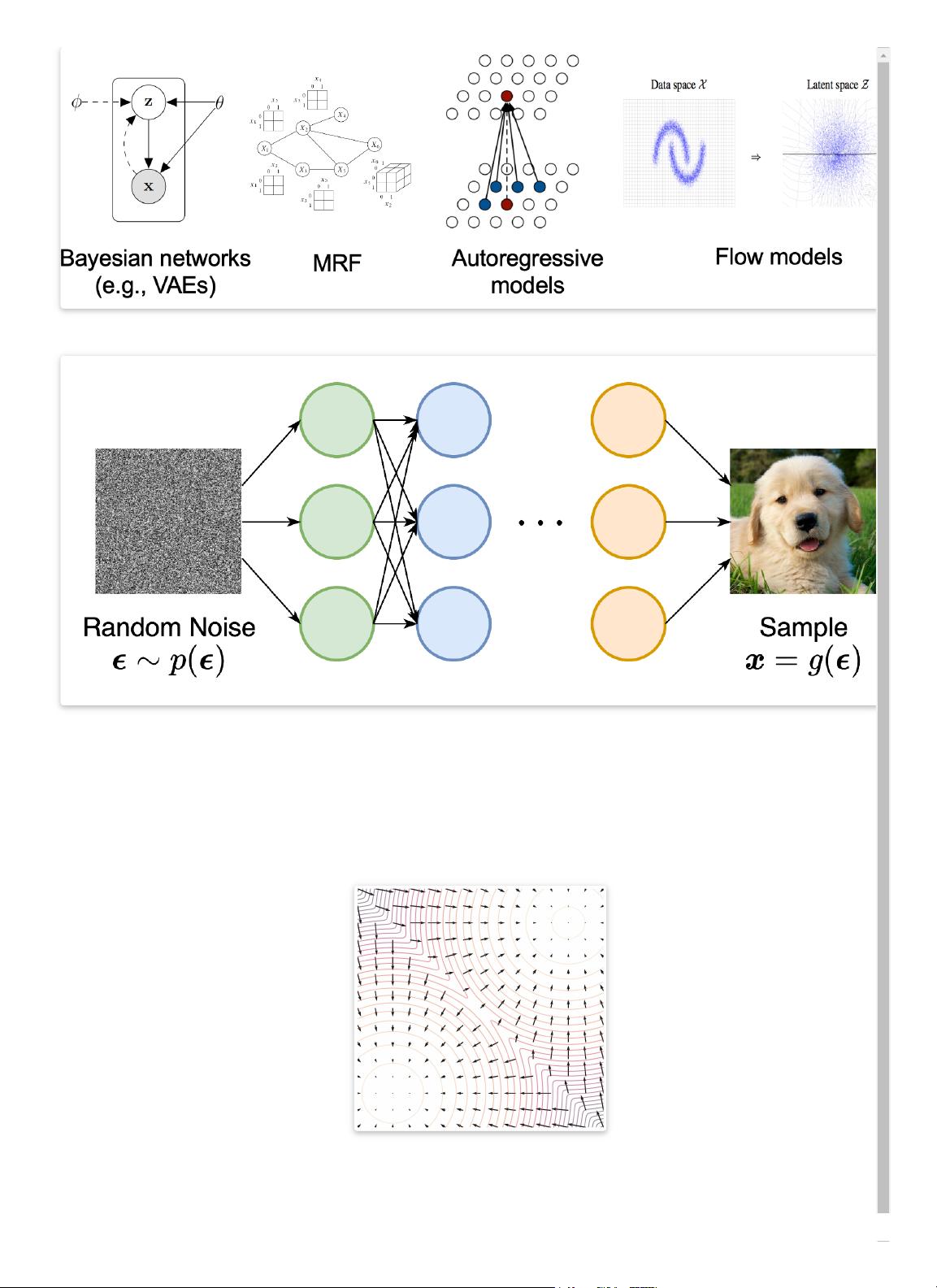
Existing generative modeling techniques can largely be grouped into two categories based on how they represent probability distributions.
1. likelihood-based models, which directly learn the distribution’s probability density (or mass) function via (approximate) maximum likelihood. Typical likeliho
based models include autoregressive models , normalizing ow models , energy-based models (EBMs) , and variational auto-encoders (VAEs)
.
2. implicit generative models , where the probability distribution is implicitly represented by a model of its sampling process. The most prominent example
generative adversarial networks (GANs) , where new samples from the data distribution are synthesized by transforming a random Gaussian vector with
neural network.
[1, 2, 3] [4, 5] [6, 7]
[8, 9]
[10]
[11]
© Copyright 2023 Yang Song. Powered by Jekyll with al-folio theme.


剩余21页未读,继续阅读
资源评论


IT徐师兄
- 粉丝: 2323
- 资源: 2862











