
Hidden Markov Map Matching
Through Noise and Sparseness
Paul Newson and John Krumm
Microsoft Research
Microsoft Corporation
One Microsoft Way
Redmond, WA 98052 USA
+1 425 705 4507, +1 425 703 8283
{pnewson, jckrumm}@microsoft.com
ABSTRACT
The problem of matching measured latitude/longitude points to
roads is becoming increasingly important. This paper describes a
novel, principled map matching algorithm that uses a Hidden
Markov Model (HMM) to find the most likely road route
represented by a time-stamped sequence of latitude/longitude
pairs. The HMM elegantly accounts for measurement noise and
the layout of the road network. We test our algorithm on ground
truth data collected from a GPS receiver in a vehicle. Our test
shows how the algorithm breaks down as the sampling rate of the
GPS is reduced. We also test the effect of increasing amounts of
additional measurement noise in order to assess how well our
algorithm could deal with the inaccuracies of other location
measurement systems, such as those based on WiFi and cell tower
multilateration. We provide our GPS data and road network
representation as a standard test set for other researchers to use in
their map matching work.
Categories and Subject Descriptors
I.5.1 [Computing Methodologies]: Pattern Recognition, --
Models (Statistical)
General Terms
Algorithms, Measurement.
Keywords
Map matching, road map, location, driving routes.
1. INTRODUCTION
Map matching is the procedure for determining which road a
vehicle is on using data from sensors. The sensors almost always
include GPS because of its nearly ubiquitous availability. Map
matching has been important for many years on in-vehicle
navigation systems which must determine which road a vehicle is
traversing in real time. More recently, map matching is becoming
important as vehicles are used as traffic probes for measuring road
speeds and building statistical models of traffic delays. These
models, in turn, can be used to find time-optimal driving routes
that avoid traffic jams. Data from such traffic probes has been
used in the commercial routing engines of Microsoft [6], Dash [7],
and Inrix [8]. Map matching is also growing in importance for
research in route prediction [11], interpreting GPS traces [1], and
activity recognition [14].
This paper makes three contributions to the research in map
matching. First, it presents a new map matching algorithm based
on the Hidden Markov Model (HMM). While the HMM has been
used before in map matching, e.g. by Hummel [9], our
formulation is novel in some important respects, detailed
subsequently. We place particular emphasis on maintaining a
principled approach to the problem while simultaneously making
the algorithm robust to location data that is both geometrically
noisy and temporally sparse. Our second contribution is a test of
our map matching algorithm where we vary the levels of noise
and sparseness of the sensed location data over a 50 mile urban
drive. Varying the amount of noise lets us intelligently speculate
about how map matching would work with less accurate location
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage, and that
copies bear this notice and the full citation on the first page. To copy
otherwise, to republish, to post on servers or to redistribute to lists,
requires prior specific permission and/or a fee. ACM GIS '09 , November
4-6, 2009. Seattle, WA, USA (c) 2009 ACM ISBN 978-1-60558-649-
6/09/11...$10.00.
1
2
3
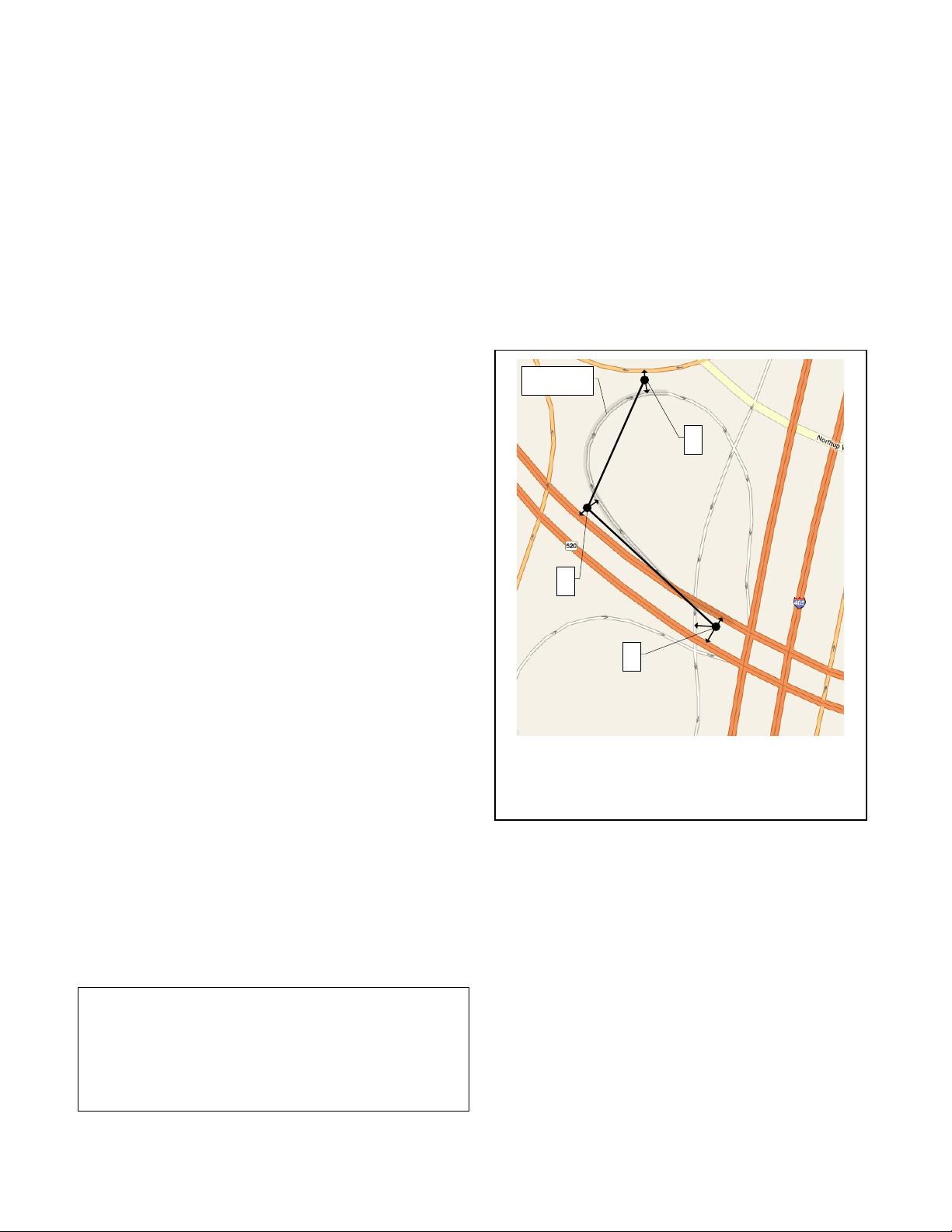
actual path
Figure 1: Map matching consists of matching measured
locations (black dots) to the road network in order to
infer the vehicle’s actual path (light gray curve). Merely
matching to the nearest road is prone to mistakes.
剩余7页未读,继续阅读
资源评论

 z11983068332016-11-07讲HMM在MM中应用的文章 正在学习
z11983068332016-11-07讲HMM在MM中应用的文章 正在学习

河柚
- 粉丝: 2
- 资源: 14









最新资源
- ORACLE数据库管理系统体系结构中文WORD版最新版本
- Sybase数据库安装以及新建数据库中文WORD版最新版本
- tomcat6.0配置oracle数据库连接池中文WORD版最新版本
- hibernate连接oracle数据库中文WORD版最新版本
- MyEclipse连接MySQL的方法中文WORD版最新版本
- MyEclipse中配置Hibernate连接Oracle中文WORD版最新版本
- MyEclipseTomcatMySQL的环境搭建中文WORD版3.37MB最新版本
- hggm - 国密算法 SM2 SM3 SM4 SM9 ZUC Python实现完整代码-算法实现资源
- SQLITE操作入门中文WORD版最新版本
- Sqlite操作实例中文WORD版最新版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


