Next
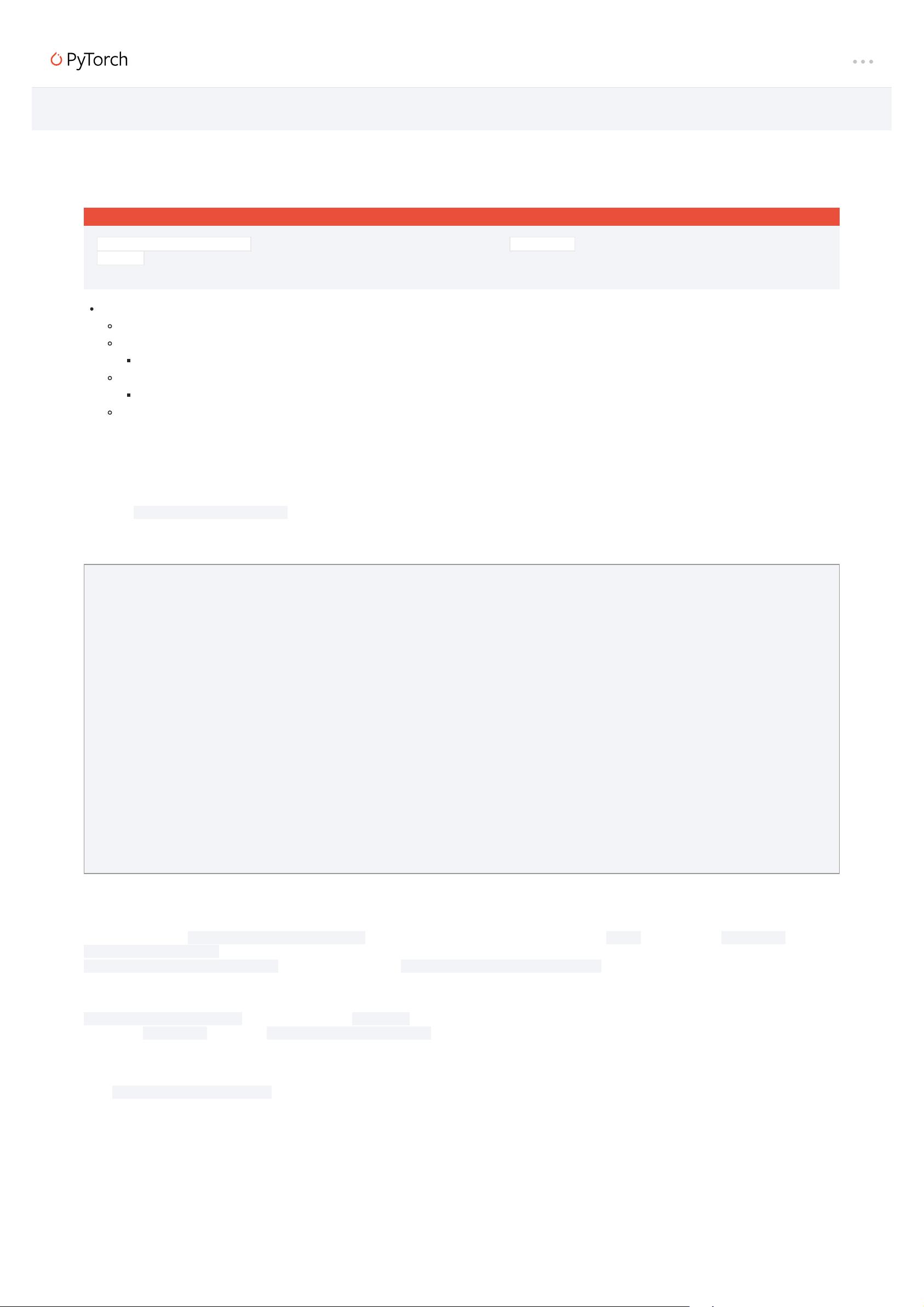
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
# Scales the loss for the out-of-place backward pass, resulting in scaled grad_params
scaled_grad_params = torch.autograd.grad(scaler.scale(loss), model.parameters(), create_graph=True)
# Unscales grad_params before computing the penalty. grad_params are not owned
# by any optimizer, so ordinary division is used instead of scaler.unscale_:
inv_scale = 1./scaler.get_scale()
grad_params = [p*inv_scale for p in scaled_grad_params]
# Computes the penalty term and adds it to the loss
grad_norm = 0
for grad in grad_params:
grad_norm += grad.pow(2).sum()
grad_norm = grad_norm.sqrt()
loss = loss + grad_norm
# Applies scaling to the backward call as usual. Accumulates leaf gradients that are correctly scaled.
scaler.scale(loss).backward()
# step() and update() proceed as usual.
scaler.step(optimizer)
scaler.update()
Working with Multiple Losses and Optimizers
If your network has multiple losses, you must call scaler.scale on each of them individually. If your network has multiple optimizers, you may call scaler.unscale_ on any of
them individually, and you must call scaler.step on each of them individually.
However, scaler.update() should only be called once, after all optimizers used this iteration have been stepped:
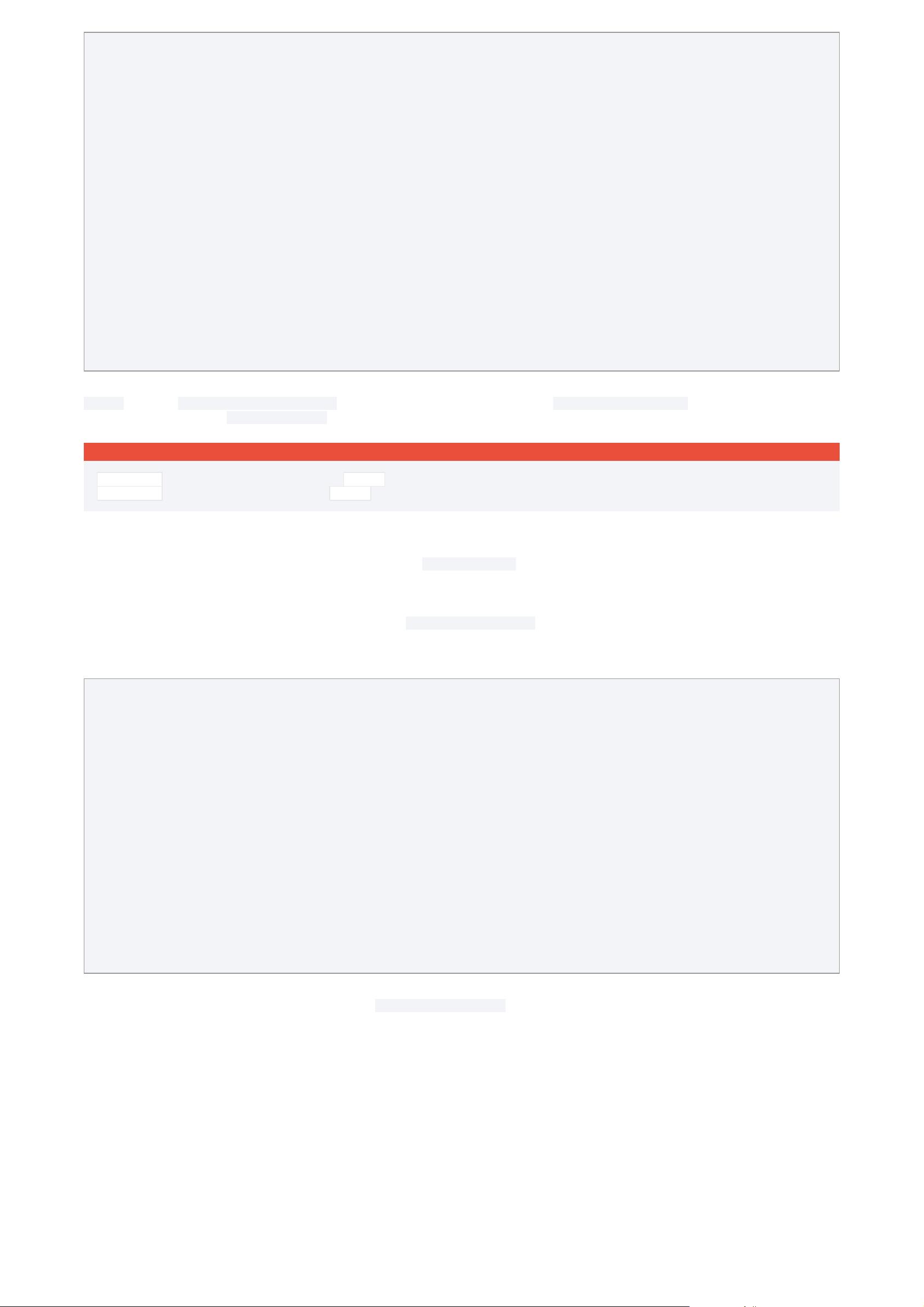
scaler = torch.cuda.amp.GradScaler()
for epoch in epochs:
for input, target in data:
optimizer0.zero_grad()
optimizer1.zero_grad()
output0 = model0(input)
output1 = model1(input)
loss0 = loss_fn(2 * output0 + 3 * output1, target)
loss1 = loss_fn(3 * output0 - 5 * output1, target)
scaler.scale(loss0).backward(retain_graph=True)
scaler.scale(loss1).backward()
# You can choose which optimizers receive explicit unscaling, if you
# want to inspect or modify the gradients of the params they own.
scaler.unscale_(optimizer0)
scaler.step(optimizer0)
scaler.step(optimizer1)
scaler.update()
Each optimizer independently checks its gradients for infs/NaNs, and therefore makes an independent decision whether or not to skip the step. This may result in one optimizer skipping the
step while the other one does not. Since step skipping occurs rarely (every several hundred iterations) this should not impede convergence. If you observe poor convergence after adding
gradient scaling to a multiple-optimizer model, please file an issue.
Previous
© Copyright 2019, Torch Contributors.
Built with Sphinx using a theme provided by Read the Docs.
Docs
Access comprehensive developer documentation for
PyTorch
View Docs
Tutorials
Get in-depth tutorials for beginners and advanced
developers
View Tutorials
Resources
Find development resources and get your questions
answered
View Resources



 shuiqing_cjn2023-05-05内容丰富,制作精美。
shuiqing_cjn2023-05-05内容丰富,制作精美。











