Python机器学习项目开发实战_预测你的内容是否会广为流传_编程案例实例课程教程.pdf
版权申诉
76 浏览量
2023-04-01
17:31:25
上传
评论
收藏 3.5MB PDF 举报


预测你的内容是否会广为流传
一切都
始于一场赌注。2001 年,Jonah Peretti,那时还是麻省理工学院的研究生,拖延
了他的毕业进程。他没有写论文,而是决定接受耐克公司提供的机会,打造一双个性化的
运动鞋。根据当时推出的最新项目,任何人都可以在耐克的新网站——NIKEiD进行这样的
设计。唯一的问题是,至少从耐克的角度来看,像Peretti所请求的那样,在耐克鞋上打出“血
汗工厂”
①
但他究竟是怎么做的呢?Peretti 如何发明秘密公式,来创建像野火一般蔓延的内容?
的字眼,是不能予以考虑的。Peretti通过一系列发给耐克公司的电子邮件表示抗
议,他指出“血汗工厂”一词并不属于该公司明令禁止条款中的任何类别,因此不应该导
致他的请求被拒绝。
Peretti 发现他与耐克的客服代表之间来来回回的邮件非常有意思,而且觉得别人可能
也会感兴趣,所以将这些信转发给一些亲近的朋友。几天之内,电子邮件已经进入了全世
界的各种收件箱。主流的媒体,例如 Time、Salon、The Guardian,甚至 Today show 的节目
都谈论到了这个。Peretti 是整个病毒式传播的中心。
不久之后,开始讨论的问题变成这种事情是否可以复制。他的朋友,Cameron Marlow,
一直在准备写有关病毒式传播的博士论文,并且非常肯定这样的事情对于任何人来说都很
难刻意为之的。Marlow 和 Peretti 打赌,Peretti 不能重复耐克事件这样的成功。Peretti 迎接
了挑战。
一晃 15 年过去了,Jonah Peretti 领导着一个名为 BuzzFeed 的网站,它已经成为了病毒
式内容的同义词。2015 年该网站拥有超过 7700 万的独立访问者,在总触达率的排名中它
高于纽约时报。我认为 Peretti 赢得了这场赌注。
①译者注:耐克认为 Peretti 这样做是含沙射影地指向耐克工厂。


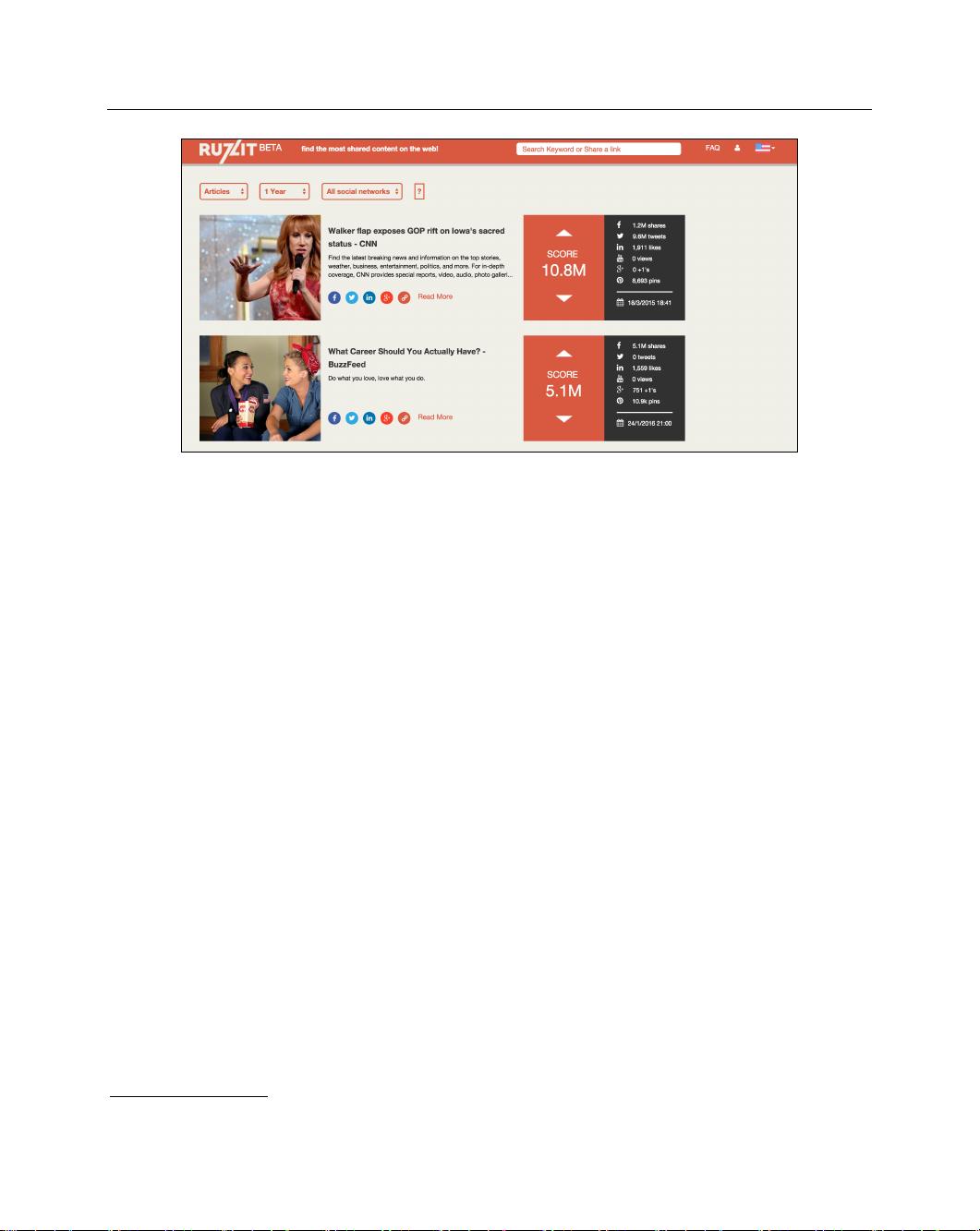
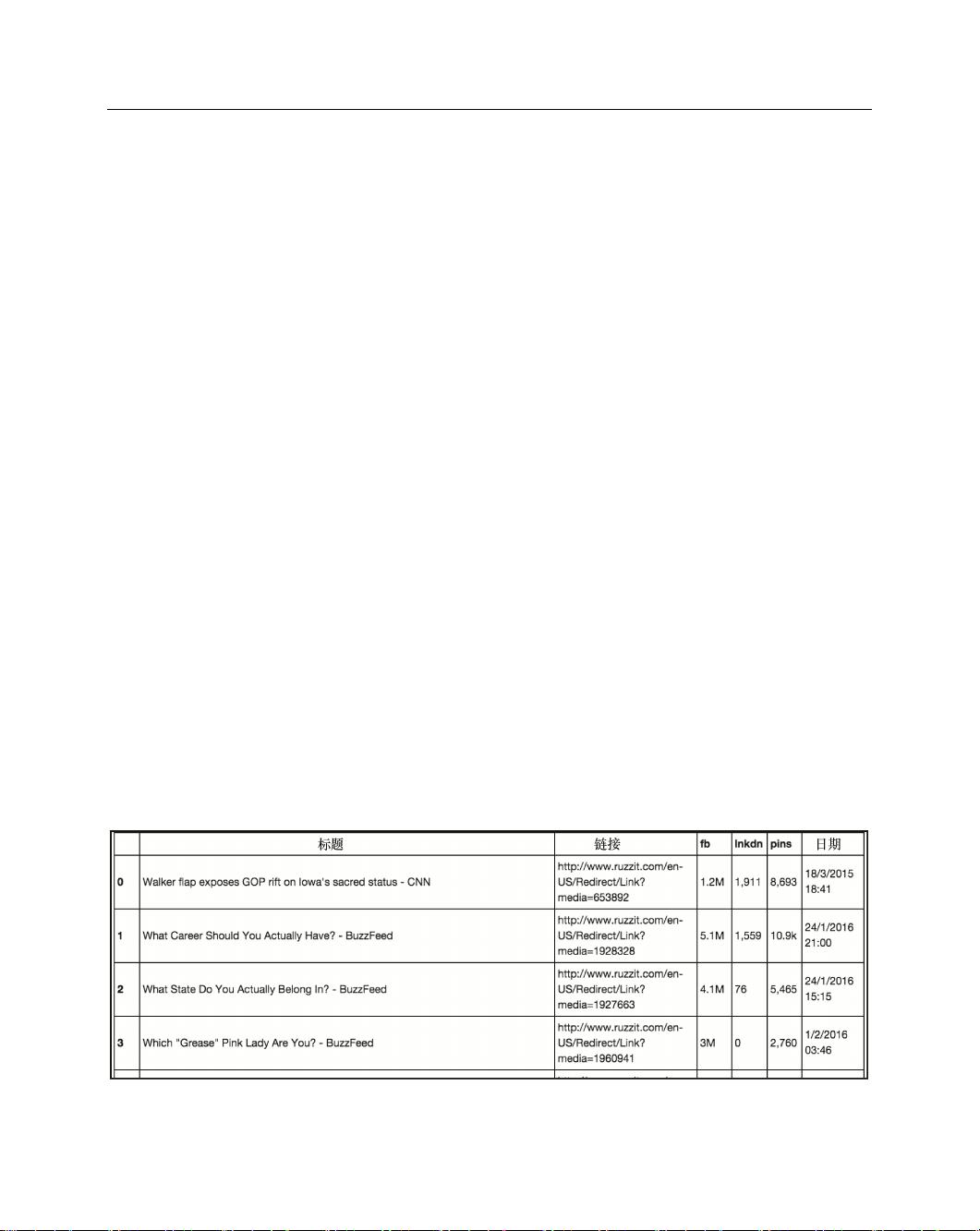
剩余24页未读,继续阅读
资源评论


好知识传播者
- 粉丝: 567
- 资源: 4204

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- ### 1、项目介绍 本项目Scrapy进行数据爬取,并使用Django框架+PyEcharts实现可视化大屏 效果如下:
- # 微信小程序-健康菜谱 基于微信小程序的一个查找检索菜谱的应用 ### 效果 !动态图(./res/gif/demo
- zabbix-get命令包资源
- 毕业设计,基于PyQt5实现的可视化界面的Python车牌自动识别系统源码
- 26-朴素贝叶斯分类.rar
- 没有安Matlab 也可以 生成FIR抽头系数工具.py
- python烟花代码.rar
- 实验目的: 1.构建基于verilog语言的组合逻辑电路和时序逻辑电路; 2.掌握verilog语言的电路设计技巧 3.完成如
- 扩展卡尔曼滤波matlab仿真
- 3_base.apk.1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


