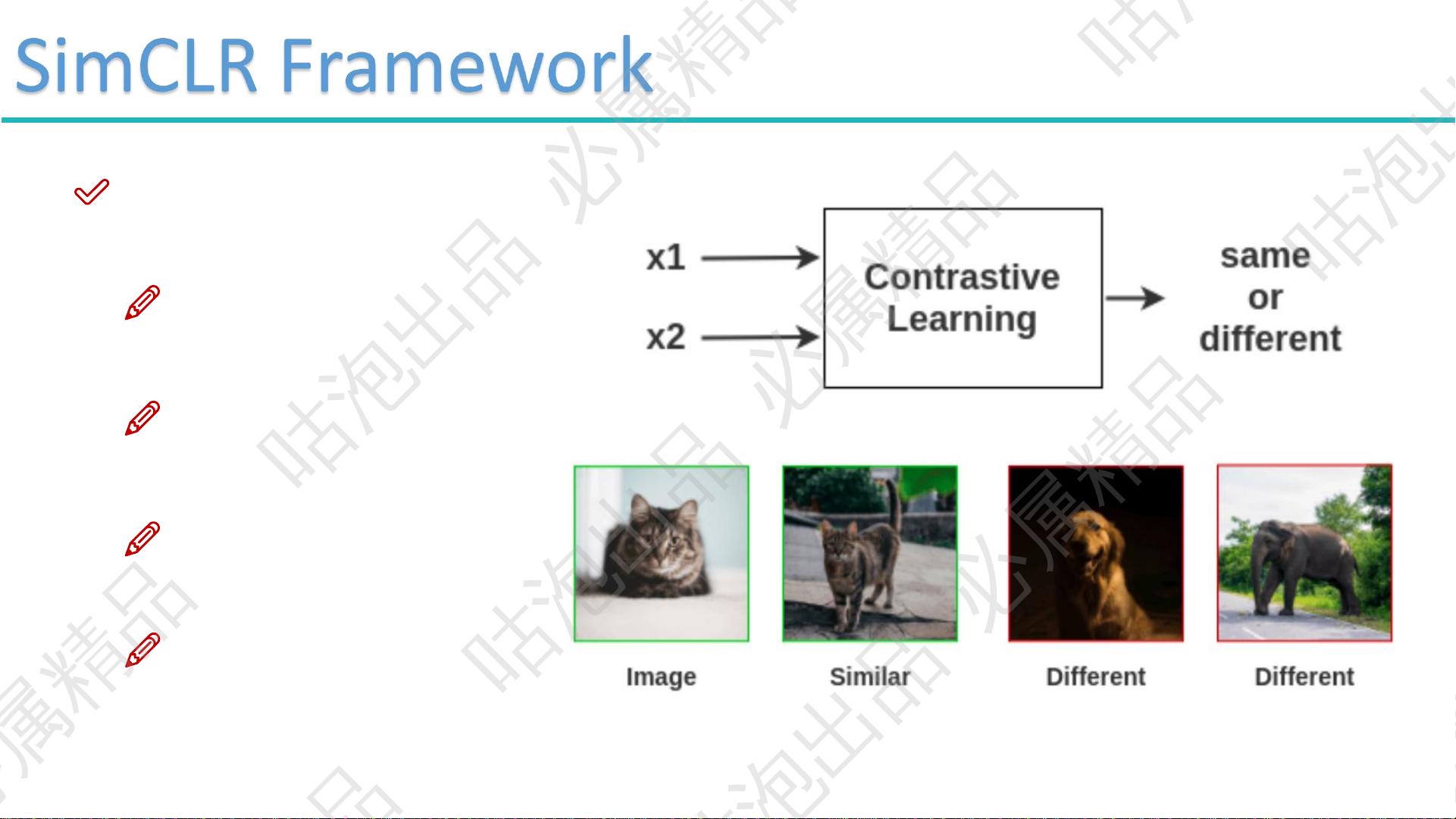
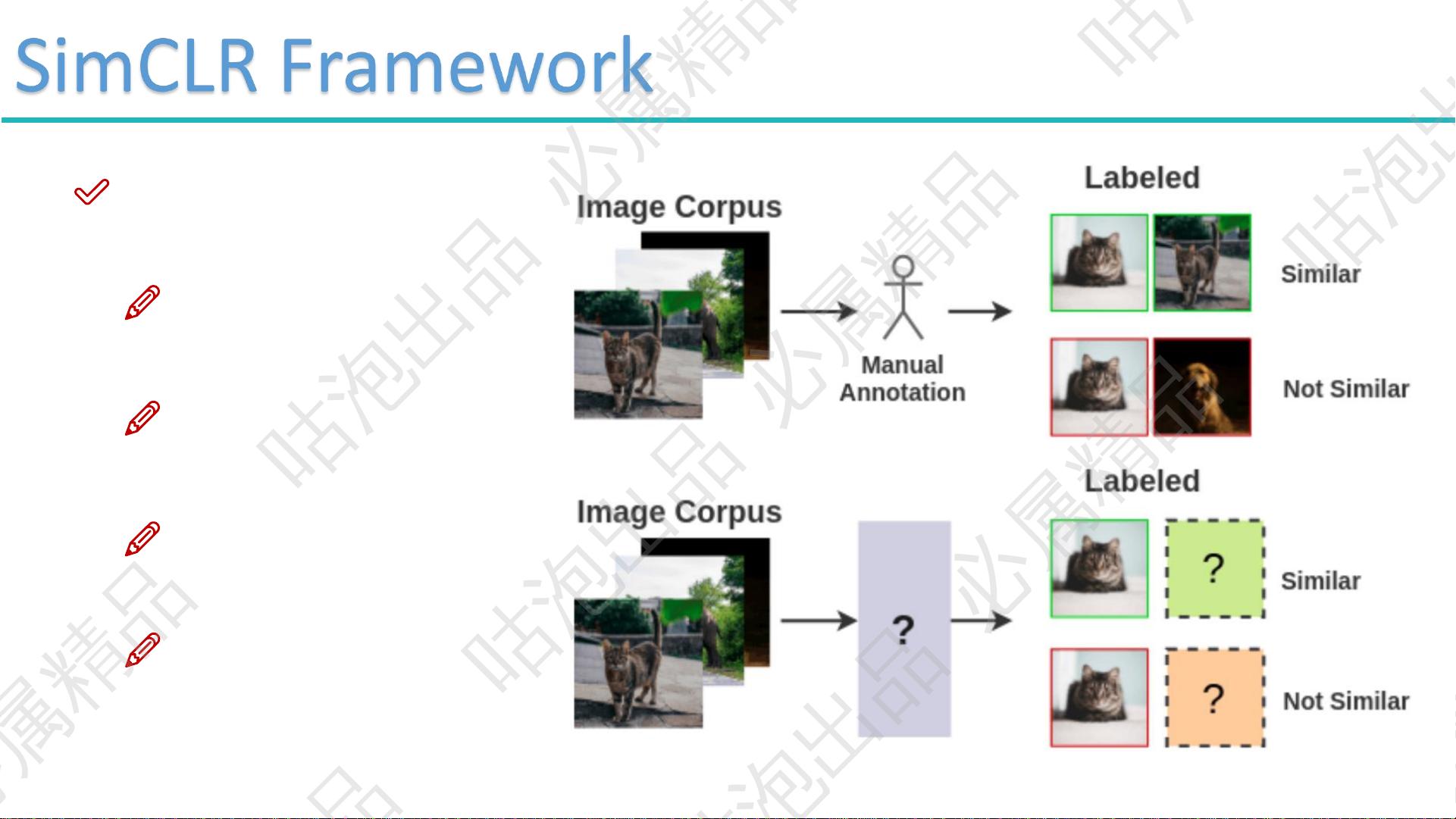
想想这一年来你最常听到过哪些词
自监督学习,对比学习等,这些事好像都不需要我们准备标签
Openai开创了GPT系列,CLIP,Dalle等,都在告诉我们一件事
模型在训练的时候,不要被标签所束缚,模型的潜力应该由他自己挖掘
我们给定了标签,限制了模型就干啥,就比如我就被限制要好好学习从而没能。。
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品
咕泡出品 必属精品

 E.zip (2个子文件)
E.zip (2个子文件)  unet++.zip 409.6MB
unet++.zip 409.6MB 对比学习.pdf 1.96MB
对比学习.pdf 1.96MB