








代码下载地址:
https://github.com/eastmountyxz/Wuhan-data-analysis
CSDN下载地址:
https://download.csdn.net/download/Eastmount/12239638
文章目录
一.人民网数据抓取
二.文本关键词提取
三.共现矩阵
四.主题关键词共现分析
五.Gephi绘制主题知识图谱
1.数据准备
2.导入数据
3.调整参数绘制图谱
4.图谱优化
六.总结
同时推荐前面作者另外五个Python系列文章。从2014年开始,作者主要写了三个Python系列文章,分别是基础知识、网络爬虫和数据分
析。2018年陆续增加了Python图像识别和Python人工智能专栏。
Python基础知识系列:
Python基础知识学习与提升
Python网络爬虫系列:
Python爬虫之Selenium+BeautifulSoup+Requests
Python数据分析系列:
知识图谱、web数据挖掘及NLP
Python图像识别系列:
Python图像处理及图像识别
Python人工智能系列:
Python人工智能及知识图谱实战
第2页 共26页
前文阅读:
[Pyhon疫情大数据分析] 一.腾讯实时数据爬取、Matplotlib和Seaborn可视化分析全国各地区、某省各城市、新增趋势
[Pyhon疫情大数据分析] 二.PyEcharts绘制全国各地区、某省各城市疫情地图及可视化分析
[Pyhon疫情大数据分析] 三.新闻信息抓取及词云可视化、文本聚类和LDA主题模型文本挖掘
[Pyhon疫情大数据分析] 四.微博话题抓取及新冠肺炎疫情文本挖掘和情感分析
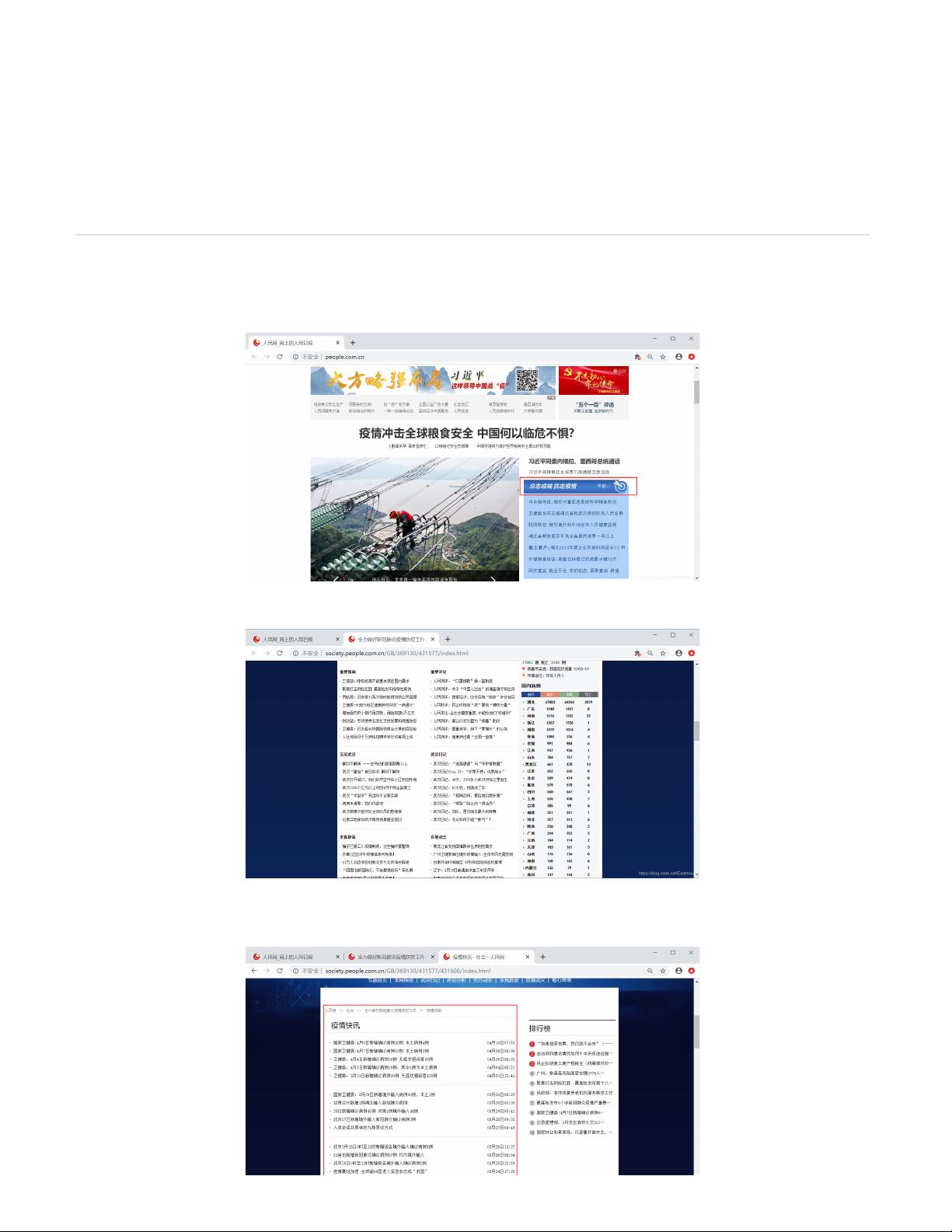
一.人民网数据抓取
本文抓取数据为人民网“众志成城,抗击疫情”专栏的新闻数据。
数据包括重要新闻、人民评论、实况武汉、各地动态、八方支援等专栏,通过抓取新闻数据进行主题关键词分析和知识图谱构建。
下面以疫情快速为例,先进行网页分析,再抓取相关的新闻数据。
http://society.people.com.cn/GB/369130/431577/431608/index.html
第3页 共26页

本文采用Selenium和BeautifulSoup进行抓取,定位网页节点关键代码如下:
标题:titles = driver.find_elements_by_xpath(’//div[@class=" p2j_list_lt fl"]/ul/li’)
链接:links = driver.find_elements_by_xpath(’//div[@class=" p2j_list_lt fl"]/ul/li/a’)
获取标题、时间、链接之后,我们通过访问链接获取正文信息,核心代码如下:
zw = soup.find(attrs={“class”:“box_con”})
完整代码:
# -*- coding: utf-8 -*-
import
os
import
re
import
csv
import
time
import
json
import
random
import
urllib
.
request
from
lxml
import
etree
from
bs4
import
BeautifulSoup
from
selenium
import
webdriver
from
selenium
.
webdriver
.
chrome
.
options
import
Options
#-------------------------------------------------
写入文件
-------------------------------------------------
path
=
os
.
getcwd
(
)
+
"/yqkx_data.csv"
csvfile
=
open
(
path
,
'a'
,
newline
=
''
,
encoding
=
'utf-8-sig'
)
第4页 共26页

writer
=
csv
.
writer
(
csvfile
)
writer
.
writerow
(
(
'序号'
,
'文章标题'
,
'发布时间'
,
'文章链接'
,
'文章内容'
)
)
#--------------------------------------------
疫情快讯
-
数据抓取
---------------------------------------------
url
=
"http://society.people.com.cn/GB/369130/431577/431608/index.html"
driver
=
webdriver
.
Chrome
(
)
#chromedriver.exe
置于
python37
根目录
driver
.
implicitly_wait
(
5
)
chrome_option
=
webdriver
.
ChromeOptions
(
)
driver
.
get
(
url
)
#
打开网页网页
driver
.
implicitly_wait
(
6
)
#
等待加载六秒
#-------------------------------------------------
获取标题
-------------------------------------------------
titles
=
driver
.
find_elements_by_xpath
(
'//div[@class=" p2j_list_lt fl"]/ul/li'
)
for
t
in
titles
:
print
(
t
.
text
)
links
=
driver
.
find_elements_by_xpath
(
'//div[@class=" p2j_list_lt fl"]/ul/li/a'
)
for
link
in
links
:
print
(
link
.
get_attribute
(
'href'
)
)
print
(
"\n\n=========================================================="
)
#-------------------------------------------------
获取正文
-------------------------------------------------
def
get_content
(
url
)
:
print
(
url
)
try
:
content
=
urllib
.
request
.
urlopen
(
url
)
.
read
(
)
soup
=
BeautifulSoup
(
content
,
"html.parser"
)
#
来源
ly
=
soup
.
find
(
attrs
=
{
"class"
:
"fl"
}
)
.
get_text
(
)
#print(ly)
#
正文
zw
=
soup
.
find
(
attrs
=
{
"class"
:
"box_con"
}
)
#
防止某些文章仅图片
if
zw
is
not
None
:
zw
=
zw
.
get_text
(
)
zw
=
zw
.
replace
(
"\n"
,
""
)
else
:
zw
=
""
print
(
zw
)
print
(
"succeed"
)
return
ly
,
zw
except
Exception
as
e
:
zw
=
e
.
partial
ly
=
""
print
(
"except"
)
print
(
zw
)
return
ly
,
page
#-------------------------------------------------
写入文件
-------------------------------------------------
k
=
0
while
k
<
len
(
titles
)
:
#
序号
num
=
str
(
k
+
1
)
#
文章标题和发布时间
value
=
titles
[
k
]
.
text
.
split
(
'\n'
)
con_title
=
value
[
0
]
con_time
=
value
[
1
]
第5页 共26页

数据抓取如下图所示:
存储至CSV文件如下图所示:
二.文本关键词提取
作者抓取了多个专栏,汇总相关数据如下图所示(可从github下载)。由于论文原因,作者仅公开每个专栏的50篇新闻,包括:八方支
援、各地动态、抗疫英雄、权威解读、人民网评、实况武汉、一线守护、疫情快讯。
#
文件链接
url
=
links
[
k
]
.
get_attribute
(
'href'
)
#
获取来源和正文
ly
,
zw
=
get_content
(
url
)
content
=
(
num
,
con_title
,
con_time
,
url
,
zw
)
#
文件写入操作
writer
.
writerow
(
(
content
)
)
k
=
k
+
1
#
文件关闭
csvfile
.
close
(
)
第6页 共26页














