

STIV: Scalable Text and Image Conditioned Video Generation
Zongyu Lin
1⋆
*
Wei Liu
1⋆
Chen Chen
2⋆
Jiasen Lu
2⋆
Wenze Hu
2⋆
Tsu-Jui Fu
2⋆
Jesse Allardice
2⋆
Zhengfeng Lai
2⋆
Liangchen Song
2⋆
Bowen Zhang
2⋆
Cha Chen
2⋆
Yiran Fei
⋆
Yifan Jiang
⋆
Lezhi Li
⋆
Yizhou Sun
⋄†
Kai-Wei Chang
⋄†
Yinfei Yang
⋄⋆
⋆
Apple
†
University of California, Los Angeles
Abstract
The field of video generation has made remarkable advancements, yet there remains a pressing need for a clear,
systematic recipe that can guide the development of robust and scalable models. In this work, we present a
comprehensive study that systematically explores the interplay of model architectures, training recipes, and
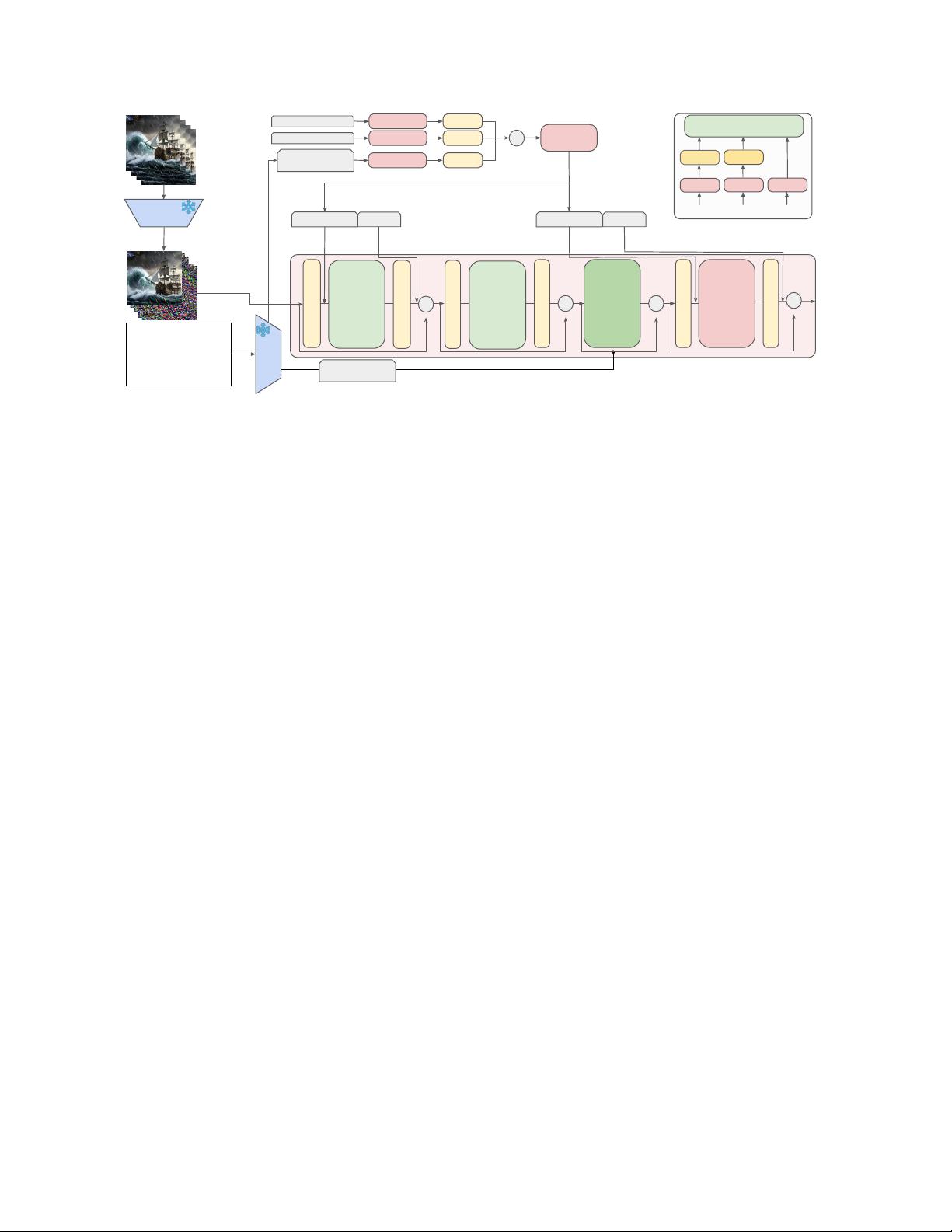
data curation strategies, culminating in a simple and scalable text-image-conditioned video generation method,
named STIV. Our framework integrates image condition into a Diffusion Transformer (DiT) through frame
replacement, while incorporating text conditioning via a joint image-text conditional classifier-free guidance. This
design enables STIV to perform both text-to-video (T2V) and text-image-to-video (TI2V) tasks simultaneously.
Additionally, STIV can be easily extended to various applications, such as video prediction, frame interpolation,
multi-view generation, and long video generation, etc. With comprehensive ablation studies on T2I, T2V, and TI2V,
STIV demonstrate strong performance, despite its simple design. An 8.7B model with
512
2
resolution achieves
83.1 on VBench T2V, surpassing both leading open and closed-source models like CogVideoX-5B, Pika, Kling, and
Gen-3. The same-sized model also achieves a state-of-the-art result of 90.1 on VBench I2V task at
512
2
resolution.
By providing a transparent and extensible recipe for building cutting-edge video generation models, we aim to
empower future research and accelerate progress toward more versatile and reliable video generation solutions.
1. Introduction
The field of video generation has witnessed a significant progress with the introduction of Sora [
42
], a video
generation model based on Diffusion Transformer (DiT) [
43
] architecture. Researchers have been actively
exploring optimal methods to incorporate text and other conditions into the DiT architecture. For example,
PixArt-
α
[
8
] leverages cross attention, while SD3 [
19
] concatenates text with the noised patches and applies
self-attention using the MMDiT block. Several video generation models [
21
,
46
,
65
] adopt similar approaches
and have made substantial progress in the text-to-video (T2V) task. Pure T2V approaches often struggle with
producing coherent and realistic videos, as their outputs are not grounded in external references or contextual
constraints [
13
]. To address this limitation, text-image-to-video (TI2V) introduce an initial image frame along
with the textual prompt, providing a more concrete grounding for the generated video.
*
This work was done during an internship at Apple.
1
First authors
2
Core authors
⋄
Senior authors
1
arXiv:2412.07730v1 [cs.CV] 10 Dec 2024



剩余45页未读,继续阅读
资源评论













