

《数据结构与算法》实验报告
一、 需求分析
问题描述:
在教科书中,各种内部排序算法的时间复杂度分析结果只给出了算法执行时间的阶,或大概
执行时间。试通过随机数据比较各算法的关键字比较次数和关键字移动次数,以取得直观感受。
基本要求:
(l)对以下 6 种常用的内部排序算法进行比较:起泡排序、直接插入排序、简单选择排序、快速排序、希
尔排序、堆排序。
(2)待排序表的表长不小于 100000;其中的数据要用伪随机数程序产生;至少要用 5 组不同的输入数据作
比较;比较的指标为有关键字参加的比较次数和关键字的移动次数(关键字交换计为 3 次移动)。
(3)最后要对结果作简单分析,包括对各组数据得出结果波动大小的解释。
数据测试:
二.概要设计
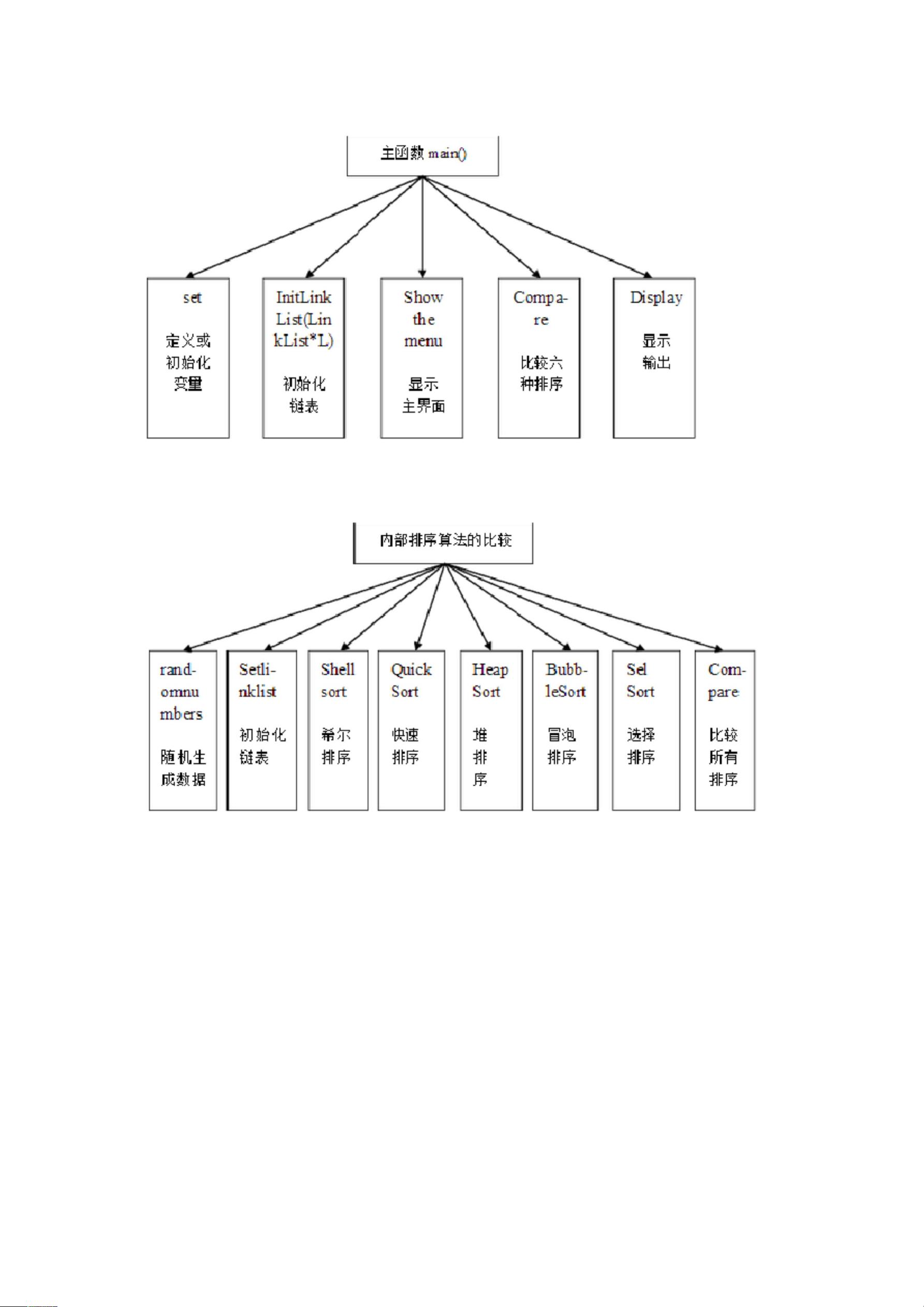
1. 程序所需的抽象数据类型的定义:
typedef int BOOL;
//说明 BOOL 是 int 的别名
typedef struct StudentData {
}
int num;
//存放关键字
//数组长度
Data; typedef struct LinkList {
Data Record[MAXSIZE];
} LinkList int RandArray[MAXSIZE];
void RandomNum()
int Length;
//用数组存放所有的随机数
//定义长度为 MAXSIZE 的随机数组
//随机生成函数
//初始化链表
void InitLinkList(LinkList* L)
BOOL LT(int i, int j,int* CmpNum)
void Display(LinkList* L)
//比较 i 和 j 的大小
//显示输出函数
void
ShellSort(LinkList*
L,
int
dlta[],
int
int*
int*
t,int*
CmpNum,
int*
int*
ChgNum)
ChgNum)
ChgNum)
ChgNum)
//
//希尔排序
void
QuickSort
HeapSort
(LinkList*
(LinkList*
L,
L,
CmpNum,
//快速排序
void
CmpNum,
CmpNum,
int*
int*
//堆排序
void
BubbleSort(LinkList*
L,
int*
//冒泡排序
void SelSort(LinkList* L, int* CmpNum, int* ChgNum)
选择排序
void Compare(LinkList* L,int* CmpNum, int* ChgNum)
比较所有排序
//

剩余18页未读,继续阅读
资源评论


xxpr_ybgg
- 粉丝: 6796
- 资源: 3万+









最新资源
- 7.(备用)180题自动计算结果(6不能用则用7).xls
- 机械设计饲料搅拌机sw18全套设计资料100%好用.zip
- DISC测试题目(详细版).doc
- DISC评分表格.xls
- Java项目:校园周边美食探索(java+SpringBoot+Mybaits+Vue+elementui+mysql)
- 明达集团招聘管理制度-终.doc
- 招聘与录用管理制度.doc
- 标准HR面试话术.doc
- 经理面试话术.doc
- 大学远程教育-计算机网络试卷题目.docx
- 技术人员面试话术.doc
- 电话邀约销售面试话术.doc
- hr电话邀约面试考察话术.doc
- 面试预约话术.doc
- python入门5个经典案例含代码示例.docx
- 基于FPGA实验板的多功能数字时钟-利用Quartus实现设计与仿真源码+课程设计报告
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


