【双11背后的技术】基于深度强化学习与自适应在线学习的搜索和推荐算法研究.pdf
版权申诉
11 浏览量
2022-11-04
09:59:53
上传
评论
收藏 1.15MB PDF 举报

【双 11 背后的技术】基于深度强化学习与自
适应在线学习的搜索和推荐算法研究
本文章来自于阿里云云栖社区
摘要: 作者:灵培、霹雳、哲予 1. 搜索算法研究与实践 1.1 背景淘宝的搜索引
擎涉及对上亿商品的毫秒级处理响应,而淘宝的用户不仅数量巨大,其行为特点
以及对商品的偏好也具有丰富性和多样性。因此,要让搜索引擎对不同特点的用
户作出针对性的排序,并以此带动搜索引导的成交提升,是一个极具挑战性的问
题。传统
选自《不一样的技术创新——阿里巴巴 2016 双 11 背后的技术》,全书目录:
https://yq.aliyun.com/articles/68637
本文作者:灵培、霹雳、哲予
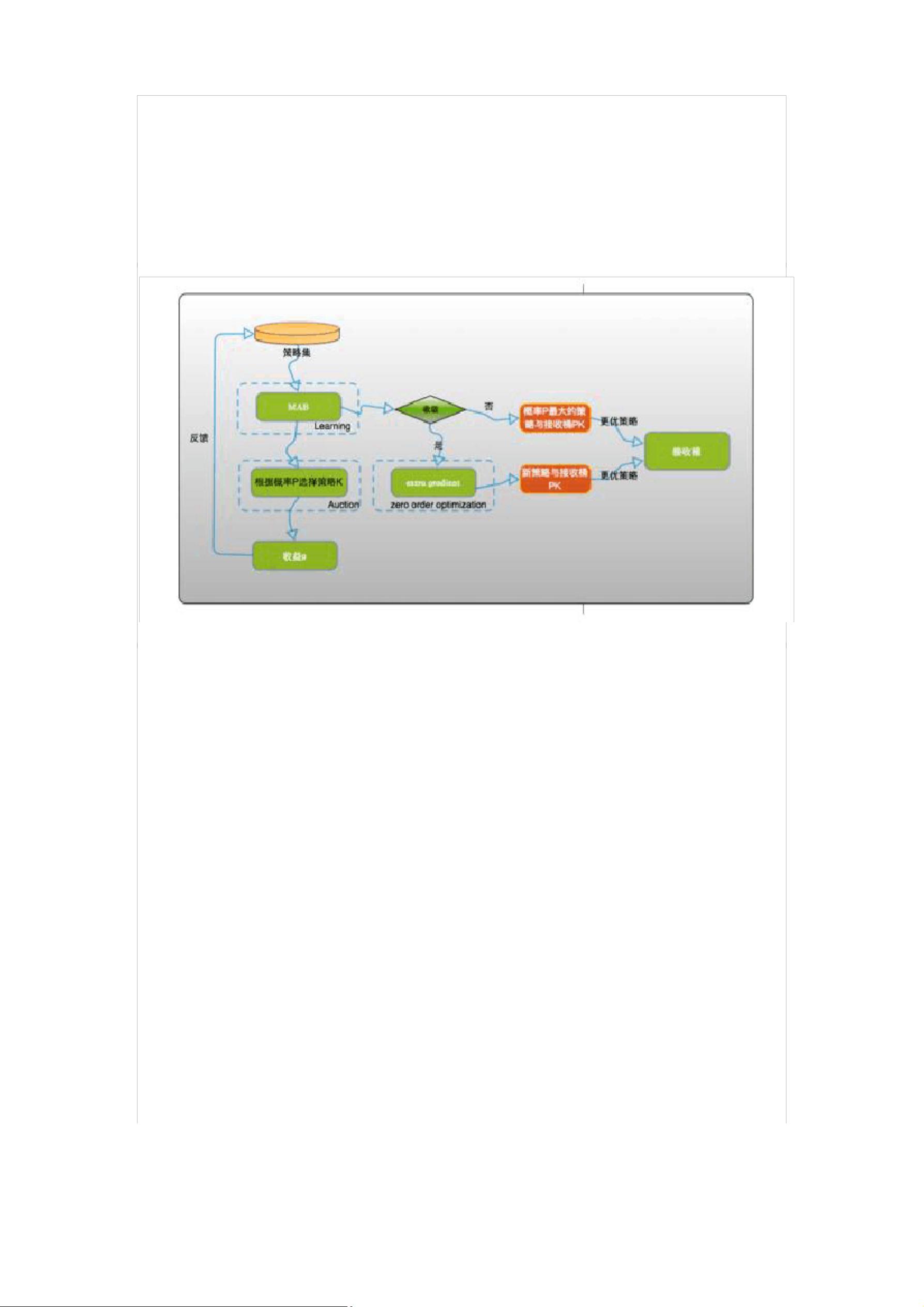
1. 搜索算法研究与实践
1.1 背景
淘宝的搜索引擎涉及对上亿商品的毫秒级处理响应,而淘宝的用户不仅数量巨大,
其行为特点以及对商品的偏好也具有丰富性和多样性。因此,要让搜索引擎对不
同特点的用户作出针对性的排序,并以此带动搜索引导的成交提升,是一个极具
挑战性的问题。传统的 Learning to Rank(LTR)方法主要是在商品维度进行学
习,根据商品的点击、成交数据构造学习样本,回归出排序权重。LTR 学习的
是当前线上已经展示出来商品排序的现象,对已出现的结果集合最好的排序效果,
受到了本身排序策略的影响,我们有大量的样本是不可见的,所以 LTR 模型从
某种意义上说是解释了过去现象,并不一定真正全局最优的。针对这个问题,有
两类的方法,其中一类尝试在离线训练中解决 online 和 offline 不一致的问题,

剩余14页未读,继续阅读
资源评论


xxpr_ybgg
- 粉丝: 6441
- 资源: 3万+









最新资源
- 农村信用社联合社计算机信息系统投产与变更管理办.docx
- 农村信用社联合社计算机信息系统数据管理办法.docx
- 利用SPSS作临床效度分析线上计算网站介绍-医学研究部统计谘.(医学PPT课件).ppt
- 利用Zabbix监控mysqldump定时备份数据库状态.docx
- 利用计算机解决问题的基本过程.doc
- 化工铁路通信工程总结.doc
- 北京大学网络教育软件工程作业.docx
- 医药公司(连锁店)计算机操作规程未新系统的自行按照旧制修改-新系统过制的编号加修模版.doc
- 医药公司(连锁店)计算机系统操作规程模版.doc
- 医药连锁门店计算机系统的操作和管理程序未新系统的自行按照旧制修改-新系统过制的编号加修模版.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


