

用 Hadoop 进行分布式并行编程, 第 1 部分
曹 羽中 (mailto:caoyuz@cn.ibm.com?subject=用 Hadoop 进行分布式并行编程, 第 1 部分), 软件工程师, IBM 中国开发中心
2008 年 5 月 22 日
Hadoop 是一个实现了 MapReduce 计算模型的开源分布式并行编程框架,借助于 Hadoop, 程序员可以轻松地编写分布式并行程序,将其运行于计算机集群上,完成海量数
据的计算。本文将介绍 MapReduce 计算模型,分布式并行计算等基本概念,以及 Hadoop 的安装部署和基本运行方法。
Hadoop 简介
Hadoop 是一个开源的可运行于大规模集群上的分布式并行编程框架,由于分布式存储对于分布式编程来说是必不可少的,这个框架中还包含了一个分布式文件系统
HDFS( Hadoop Distributed File System )。也许到目前为止,Hadoop 还不是那么广为人知,其最新的版本号也仅仅是 0.16,距离 1.0 似乎都还有很长的一段距离,但
提及 Hadoop 一脉相承的另外两个开源项目 Nutch 和 Lucene ( 三者的创始人都是 Doug Cutting ),那绝对是大名鼎鼎。Lucene 是一个用 Java 开发的开源高性能全文
检索工具包,它不是一个完整的应用程序,而是一套简单易用的 API 。在全世界范围内,已有无数的软件系统, Web 网站基于 Lucene 实现了全文检索功能,后来 Doug
Cutting 又开创了第一个开源的 Web 搜索引擎(http://www.nutch.org/) Nutch, 它在 Lucene 的基础上增加了网络爬虫和一些和 Web 相关的功能,一些解析各类文档
格式的插件等,此外,Nutch 中还包含了一个分布式文件系统用于存储数据。从 Nutch 0.8.0 版本之后,Doug Cutting 把 Nutch 中的分布式文件系统以及实现 MapReduce
算法的代码独立出来形成了一个新的开源项 Hadoop。Nutch 也演化为基于 Lucene 全文检索以及 Hadoop 分布式计算平台的一个开源搜索引擎。
基于 Hadoop,你可以轻松地编写可处理海量数据的分布式并行程序,并将其运行于由成百上千个结点组成的大规模计算机集群上。从目前的情况来看,Hadoop 注定会有一个
辉煌的未来:"云计算"是目前灸手可热的技术名词,全球各大 IT 公司都在投资和推广这种新一代的计算模式,而 Hadoop 又被其中几家主要的公司用作其"云计算"环境中的
重要基础软件,如:雅虎正在借助 Hadoop 开源平台的力量对抗 Google, 除了资助 Hadoop 开发团队外,还在开发基于 Hadoop 的开源项目 Pig, 这是一个专注于海量数
据集分析的分布式计算程序。Amazon 公司基于 Hadoop 推出了 Amazon S3 ( Amazon Simple Storage Service ),提供可靠,快速,可扩展的网络存储服务,以及一
个商用的云计算平台 Amazon EC2 ( Amazon Elastic Compute Cloud ) 。在 IBM 公司的云计算项目--"蓝云计划"中,Hadoop 也是其中重要的基础软件。Google 正在
跟 IBM 合作,共同推广基于 Hadoop 的云计算。
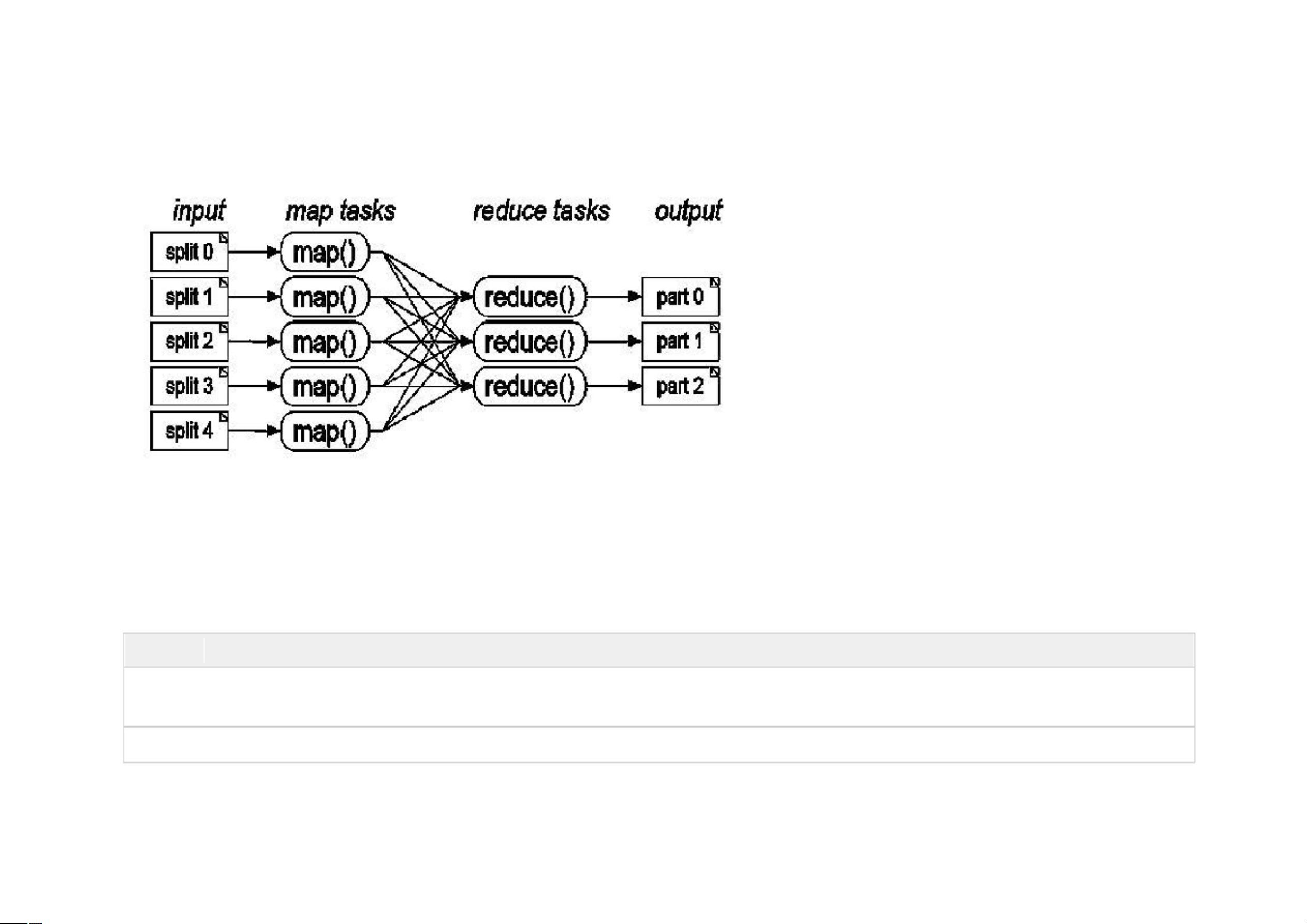
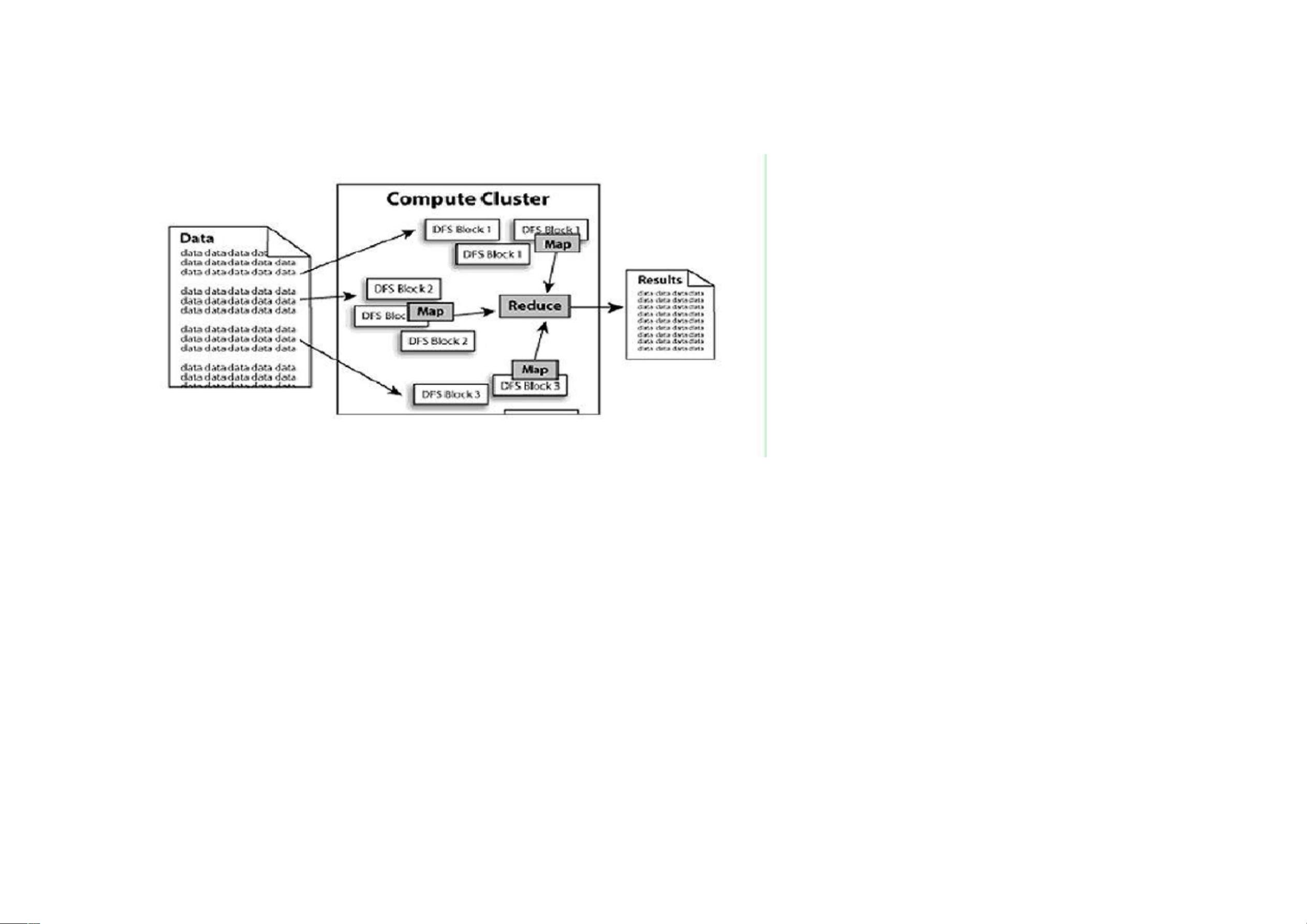
剩余40页未读,继续阅读
资源评论


xxpr_ybgg
- 粉丝: 6789
- 资源: 3万+









最新资源
- 基于Qt的上海地铁换乘系统详细文档+全部资料+高分项目.zip
- 发那科机器人二次开发 C#读取和写入数据,可以获取点位信息
- 基于QT的人脸识别,定位导航,脑电心率测算,用GPRS传到服务端的疲劳驾驶检测系统详细文档+全部资料+高分项目.zip
- 基于Qt的图书管理系统普通用户操作界面详细文档+全部资料+高分项目.zip
- 基于Qt的文件共享系统,类似百度网盘详细文档+全部资料+高分项目.zip
- 基于QT的网络视频监控系统详细文档+全部资料+高分项目.zip
- 基于QT的图书管理系统详细文档+全部资料+高分项目.zip
- 基于QT的学生成绩管理系统,QSS界面设计,SQL数据库的使用详细文档+全部资料+高分项目.zip
- 基于Qt的物业管理系统详细文档+全部资料+高分项目.zip
- 基于QT的直播管理系统详细文档+全部资料+高分项目.zip
- 基于Qt的学生信息管理系统、教师端:支持增删查改,班级成绩分析。学生端:查看成绩详细文档+全部资料+高分项目.zip
- 基于Qt的智能病房系统详细文档+全部资料+高分项目.zip
- 基于Qt构建的目标检测系统。基于dlib_rear_end_vehicles数据集详细文档+全部资料+高分项目.zip
- 基于QT的智能家居系统详细文档+全部资料+高分项目.zip
- 基于Qt和Mysql的教务管理系统详细文档+全部资料+高分项目.zip
- 基于Qt和mysql的大学生二手管理系统详细文档+全部资料+高分项目.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


