

近来数据中台概念大火,大家对它的定义也五花八门,不一而足。但无论怎么定义,一个完善的数据技术
架构必不可少。了解这些架构里每个部分的位置,功能和含义,不仅能让我们更好了解数据产品的范围和
边界,知道技术能帮我们实现什么,能怎么实现得更好,另一方面,很多技术的设计理念对我们认知世界,
了解复杂系统也会有所裨益。因此这篇文章旨在梳理市面上常见的开源技术方案,背后原理及应用场景,
帮助产品经理对大数据技术体系有个大致全面的了解。
一般来说,我们将数据整个链条区分为四个环节,从数据采集传输,到数据存储,再到数据计算&查询,到
后续的数据可视化及分析。框架图如下:
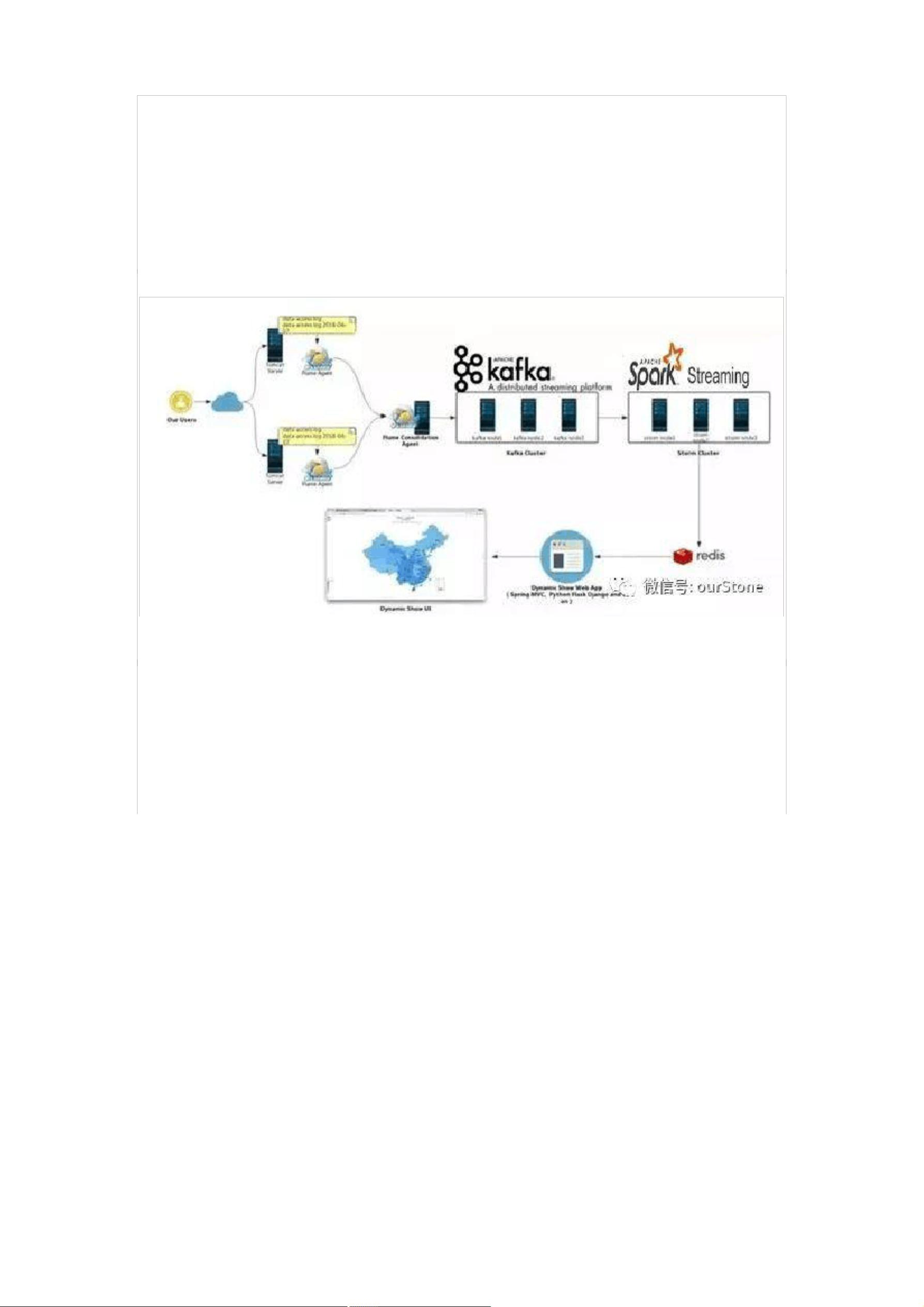
1. 数据采集传输
这个一般对应于公司的日志平台,任务是将数据采集后缓存在某个地方,供后续的计算流程进行消费使用。
针对不同的数据来源有各自的采集方式,从 APP/服务器 日志,到业务表,还有各种 API 接口及数据文件
等等。其中因为日志数据有数据量多,数据结构多样,产生环境复杂等特点,属于「重点关照」的对象。
目前市面针对日志采集的有 Flume,Logstash,Filebeat,Fluentd ,rsyslog 几种常见的框架,我们挑
应用较广泛的前两者介绍下:
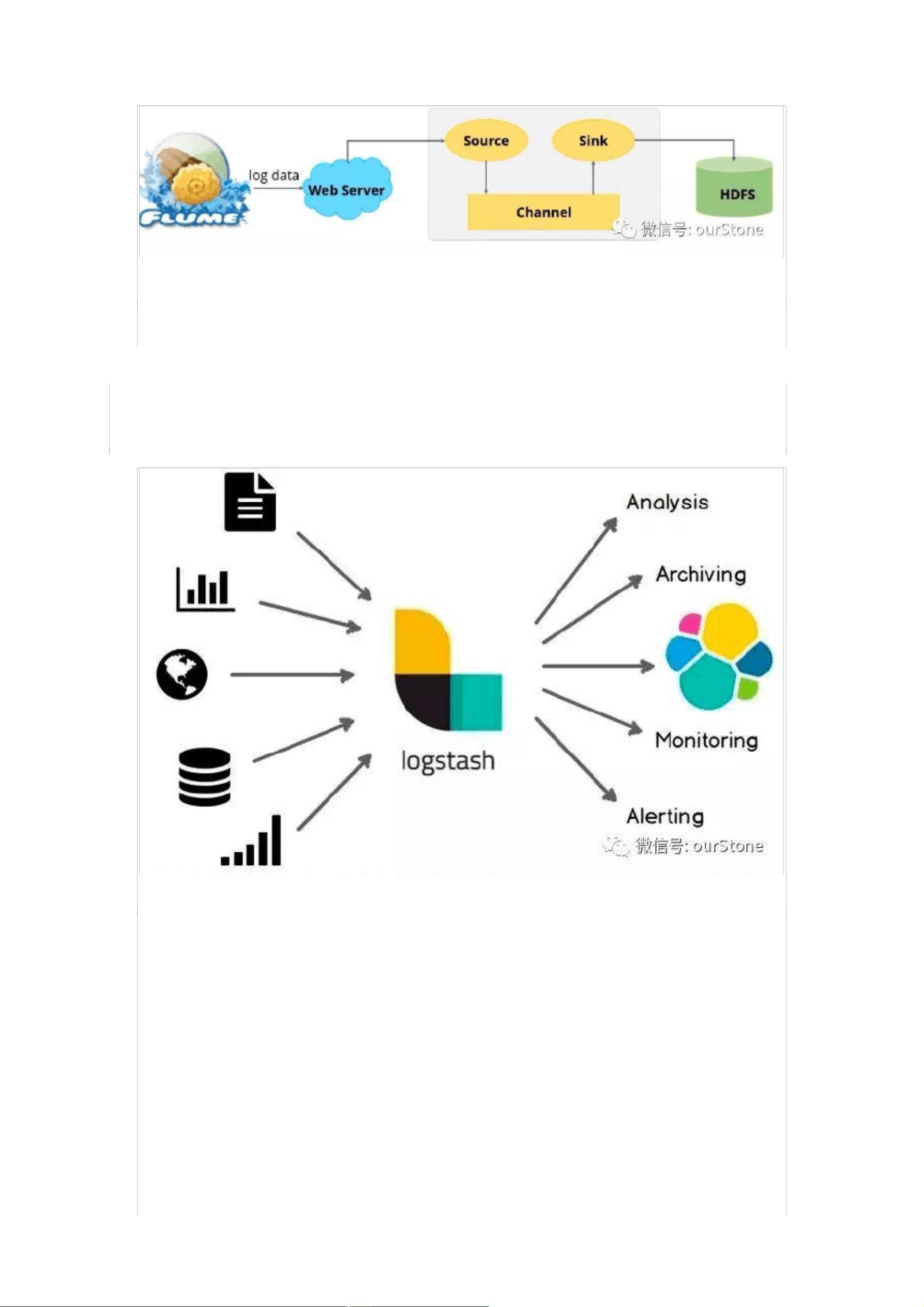
1.1 Flume 和 Logstash Flume 是一款由 Cloudera 开发的实时采集日志引擎,主打高并发,高速度,分
布式海量日志采集。它是一种提供高可用、高可靠、分布式海量日志采集、聚合和传输的系统。Flume 支
持在日志系统中定制各类数据进行发送,用于采集数据;同时,它支持对数据进行简单处理,并写到各种
数据接收方。目前有两个版本,OG 和 NG,特点主要是:
1. 侧重数据传输,有内部机制确保不会丢数据,用于重要日志场景
2. 由 java 开发,没有丰富的插件,主要靠二次开发
3. 配置繁琐,对外暴露监控端口有数据
剩余10页未读,继续阅读
资源评论


xxpr_ybgg
- 粉丝: 6789
- 资源: 3万+









最新资源
- Oracle10gDBA学习手册中文PDF清晰版最新版本
- 扒网站数据软件项目全套技术资料100%好用.zip
- AI爬虫项目全套技术资料100%好用.zip
- 倪海厦讲义及笔记,易学数据测算
- 智能图书管理系统项目全套技术资料.zip
- 基于java写的爬虫项目全套技术资料.zip
- 218) Leverage - 创意机构与作品集 WordPress 主题 2.2.7.zip
- 220) Vinkmag - 多概念创意报纸新闻杂志 WordPress v5.0.zip
- 219) Axtra - 数字机构创意作品集主题 v2.0.zip
- 217) Voice - 清洁新闻 - 杂志 WordPress 主题 v3.0.3.zip
- 215) Classiera – 分类广告 WordPress 主题 v4.0.28.zip
- 216) Creote - 企业与咨询业务 WordPress 主题 v2.7.8.zip
- 212) Outgrid - 多用途 Elementor WordPress 主题 v2.0.0.zip
- 213) Blacksilver - 摄影 WordPress 主题 v9.4.zip
- 214) Nokri - 招聘板 WordPress 主题 v1.5.9.zip
- 211) TopDeal - 多供应商市场 WordPress 主题(移动布局就绪) v2.3.15.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


