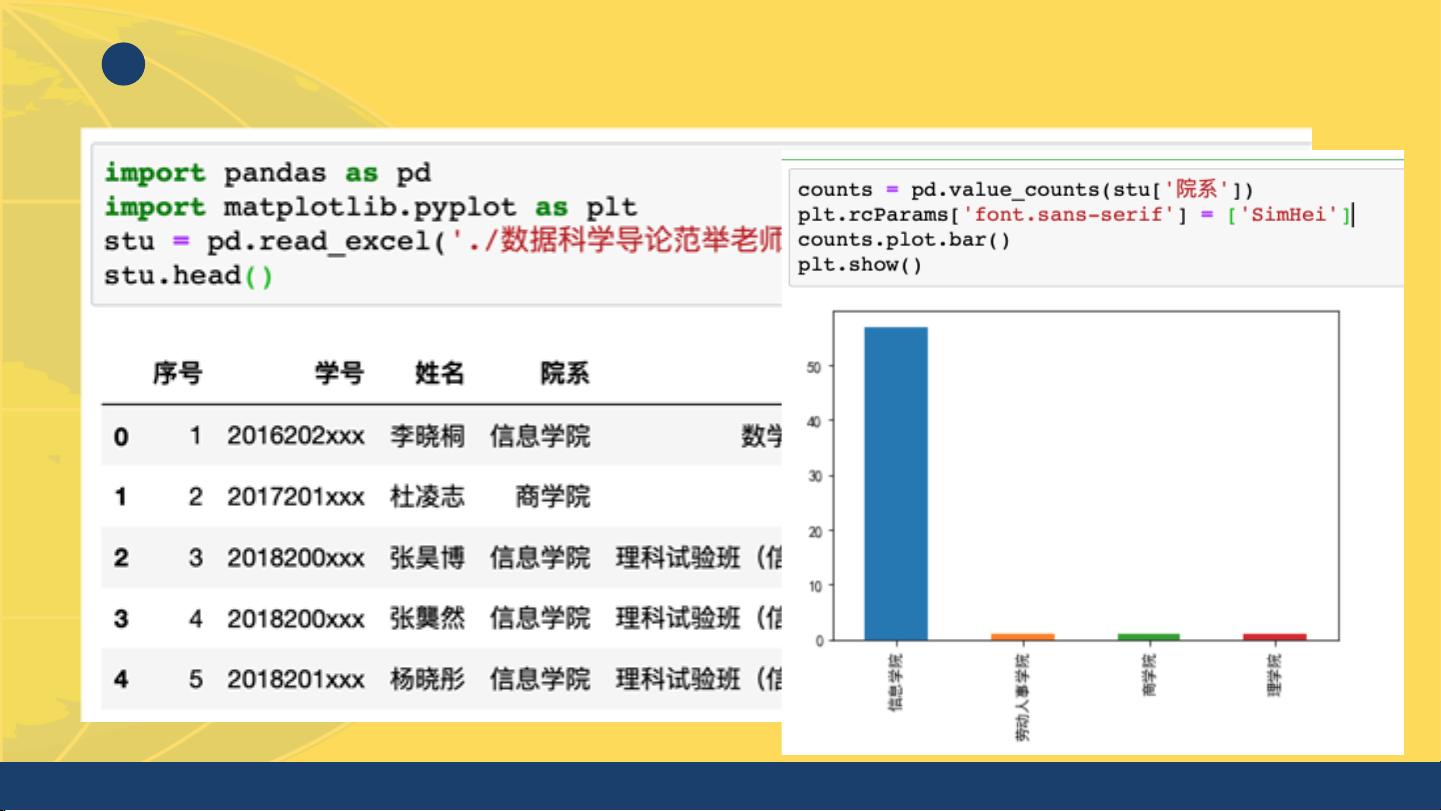
《数据科学导论》中的Python基础是学习数据科学不可或缺的一部分。Python因其简洁的语法和丰富的库支持,成为了数据科学家首选的编程语言。本讲座将深入探讨Python的基础知识,包括其历史、特性、优势以及在数据科学中的应用。
Python是由荷兰的吉多·范罗苏姆在1989年创建的,是一种解释型语言,这意味着它的代码不需要预先编译,而是由解释器逐行执行。这种特性使得Python具备了高度的可读性和灵活性,同时也降低了开发的门槛。Python被广泛赞誉为“胶水语言”,因为它能够轻松地与其他编程语言或库集成,解决了所谓的“两种语言问题”,即研究和生产系统中通常需要使用不同语言的困境。
在数据科学领域,Python的优势在于它拥有强大的生态系统,包括NumPy、Pandas等核心库,它们为数据处理和分析提供了高效且便捷的工具。NumPy是Python中用于处理大型多维数组和矩阵的库,而Pandas则是一个数据框库,提供了高级数据分析功能。这两个库共同构成了数据科学家处理数据的基本框架。
然而,Python并非在所有场景下都是最佳选择。对于需要极低延迟和高并发性的应用,如实时交易系统或高性能计算,其他语言如Java或C++可能更合适。例如,尽管Python在“双十一”等大规模在线购物活动中的应用广泛,但在处理极端并发时,可能需要其他技术来提升性能。
在开始Python的学习之旅之前,我们需要确保正确的环境配置。Python有两个主要版本,Python 2和Python 3,其中Python 3是目前的主流版本,新特性更多,更推荐学习。包管理是Python开发者经常面临的问题,尤其是安装第三方库如numpy和pandas。为了解决这些问题,可以使用Anaconda,这是一个全面的开源数据分析平台,它包含了多个Python版本和众多数据科学相关的软件包,同时提供了环境管理功能,允许在不同的项目之间切换不同的软件包环境。
安装Anaconda后,可以通过Anaconda Navigator图形界面或命令行工具创建和管理环境。此外,Anaconda还包含了Jupyter Notebook,这是一个交互式编程和文档编写工具,非常适合数据科学项目。若不在Anaconda环境下,可以使用Python自带的包管理工具pip来安装所需库,例如`pip install pandas`。
在开始编写Python代码时,了解基本的语法概念至关重要,如变量、常量和注释。变量是存储数据的容器,常量则是不会改变的值,而注释则用来解释代码的功能,提高代码的可读性。学习Python的基础还包括理解数据类型(如整数、浮点数、字符串和布尔值)、流程控制(如条件语句和循环)、函数定义和调用,以及异常处理等。
《数据科学导论》中的Python基础部分旨在帮助初学者建立起对Python语言的扎实理解,为后续的数据科学实践打下坚实基础。通过学习这部分内容,你可以熟练地配置Python环境,掌握基本语法,以及利用Python强大的库进行数据处理和分析。