






NiFi 文档

1.1 什么是 NiFi
Apache NiFi 是一个易于使用、功能强大而且可靠的数据处理和分发系统,在大数据
生态中的定位是成为一个统一的,与数据源无关的大数据集成平台。Apache NiFi 是为数
据流设计,它支持高度可配置的指示图,来指示数据路由、转换和系统中流转关系,支持从
多种数据源动态拉取数据。简单地说,NiFi 是为自动化系统之间的数据流而生。 这里的数
据流表示系统之间的自动化和受管理的信息流。 基于 WEB 图形界面,通过拖拽、连接、配
置完成基于流程的编程,实现数据采集、处理等功能。未来 NiFi 有可能替换 Flume、Sqoop
等大数据导数据的工具。
NiFi 官网地址:http://nifi.apache.org/
1.1.1 NiFi 背景介绍
2006 年 NiFi 由美国国家安全局(NSA)的 Joe Witt 创建。2015 年 7 月 20 日,
Apache 基金会宣布 Apache NiFi 顺利孵化成为 Apache 的顶级项目之一。NiFi 初始的
项目名称是 Niagarafiles,当 NiFi 项目开源之后,一些早先在 NSA 的开发者们创立了
初创公司 Onyara,Onyara 随之继续 NiFi 项目的开发并提供相关的支持。Hortonworks
公司收购了 Onyara 并将其开发者整合到自己的团队中,形成 HDF(Hortonworks Data
Flow)平台。2018 年 Cloudera 与 Hortonworks 合并后,新的 CDH 整合 HDF,改名为
Cloudera Data Flow(CDF) 。Cloudera 将 NiFi 作 为 其 新 产 品 Cloudera Flow
Management 和 Cloudera Edge Management 的核心组 件推 出,可以方 便地 使用
Cloudera Manager 进行 Parcel 安装和集成,而 Apache NiFi 就是 CFM 的核心组件。
1.1.2 传统数据流解决方案遇到的问题
传统数据流接收处理过程中存在如下问题:
1) 系统错误
包括网络错误、磁盘错误、软件崩溃,甚至是人为操作错误,造成了数据流处理不稳定。
2) 数据访问超过处理能力
当数据处理某一模块出现瓶颈问题时,不能及时处理到达的数据

3) 异常数据处理
不可避免出现数据太大,数据传输太慢,数据损坏、问题数据、数据碎片及数据格式错
误问题。
4) 业务快速演进
现实业务或需求变更快,设计新的数据处理流程或者修改已有的流程必须要迅速。
5) 多系统升级不同步引入的前后兼容
原有系统的协议和数据格式,会伴随系统的升级有一定的调整,同时单个系统的升级会
影响周边系统。数据流可以把多个大型分布式系统串边在一起,这些系统可以是松散地,甚
至设计之初就没考虑未来集成。
6) 持续改进生产系统
通常不可能在测试环境中完全模拟生产环境。一旦测试通过的流处理流程有可能针对生
产环境继续修改,耗时费力。
多年来,数据流(dataflow)一直是架构中的痛点之一。而现在有越来越多事物的兴起
让企业开始重视数据流,包括:面向服务的体系结构(SOA),API,物联网 IOT 和大数据。
此外,合规性,隐私性和安全性所需的严格程度也在不断提高。对于这些新鲜事物或概念,
数据流的需求大致相同,主要区别在于复杂性,适应业务变化的速度,以及大规模边缘用例。
NiFi 旨在帮助解决这些现代数据流挑战。
1.1.3 NiFi 特点
Apache NiFi 是一个易于使用、功能强大而且可靠的数据拉取、数据处理和分发系统,
用于自动化管理系统间的数据流。
支持高度可配置的指示图的数据路由、转换和系统中介逻辑,支持从多种数据源动态拉
取数据。
NiFi 基于 Web 方式工作,后台在服务器上进行调度,是 Apache 基金会的顶级项目之
一。
用户可以为数据处理定义为一个流程,然后进行处理,后台具有数据处理引擎、任务调
度等组件。

1.2 NiFi 架构
1.2.1 NiFi 核心概念
NiFi 的基本设计理念是基于数据流的编程 Flow-Based Programming(FBP),应
用是由处理器、连接器组成的网络。数据进入一个节点,由该节点对数据进行处理,根据不
同的处理结果将数据路由到后续的其他节点进行处理。这是 NiFi 的流程比较容易可视化的
一个原因。以下是 NiFi 的一些概念:
NiFi 术语
描述
FlowFile
FlowFile 是系统间传输的对象,FlowFile 有 attribute 和
content,attribute 属性是与数据关联的 key-value 键值对,
content 内容是数据本身相关的字节流。
FlowFile Processor
Processor 是实际操作数据的模块。Processor 负责创建、接收、
发送、转换、路由、拆分、合并、处理 FlowFile。
Processor 可以访问零到多个 FlowFile 的属性和内容,可以提交
或回退提交的任务。
Connection
Connection 用来连接 Processor,每个 Connection 充当一个队
列从而实现不同的 Processor 可以以不同的速率交互数据。这个队
列可以动态调节优先级,也可以设置负载上限,实现反压机制。
Connection 通常和 Processor 的一个或者多个 Relationship
连接,这就允许根据处理器的不同数据处理结果来路由数据。当一个
FlowFile 被发送到某个 Relationship 时,它就被加到了对应的
COnnect 队列里。
Flow Controllers
负责维护 Processors 之间的调度、管理所有流程使用的线程及其分
配。
Process Group
处理器组,一堆 Processors 及其对应的 Connection 组成了一个
Process Group,这个处理器组通过输入端口接收数据,通过输出端
口发送数据。
Process Group 可以组合其他的组件来创建新的组合。
参 照 上 述 表 格 , 简 单 来 讲 FlowFile 是 在 各 个 节 点 间 流 动 的 数 据 ; FlowFile
Processor 是数据的处理模块;Connection 是各个处理模块间的一个队列;Flow
Controllers 是复杂流程的调度;Process Group 一些相关连的 Processor 可以封装
到一个 Process Group 中,不同组用来表示不同流程的层次关系。
这种设计模式带来了很多好处,帮助 NiFi 成为构建强大的可扩展数据流高效的平台,
包括:
适用于可视化的创建和管理 Processor。
本质上是异步的,即使在处理和流量波动时也允许非常高的吞吐和自然缓冲。
提供高并发的模型,让开发人员不用担心如何实现复杂的并发。
帮助高度聚合和松散耦合组件的开发,让这些组件可以在其他环境复用,并帮助单元测
试。
资源受限的 connection 使得背压和压力释放等关键功能非常自然和直观。
错误处理做的非常好,而不是粗粒度的一把抓。
数据进入和退出系统以及如何流过的点很容易理解和轻松跟踪。
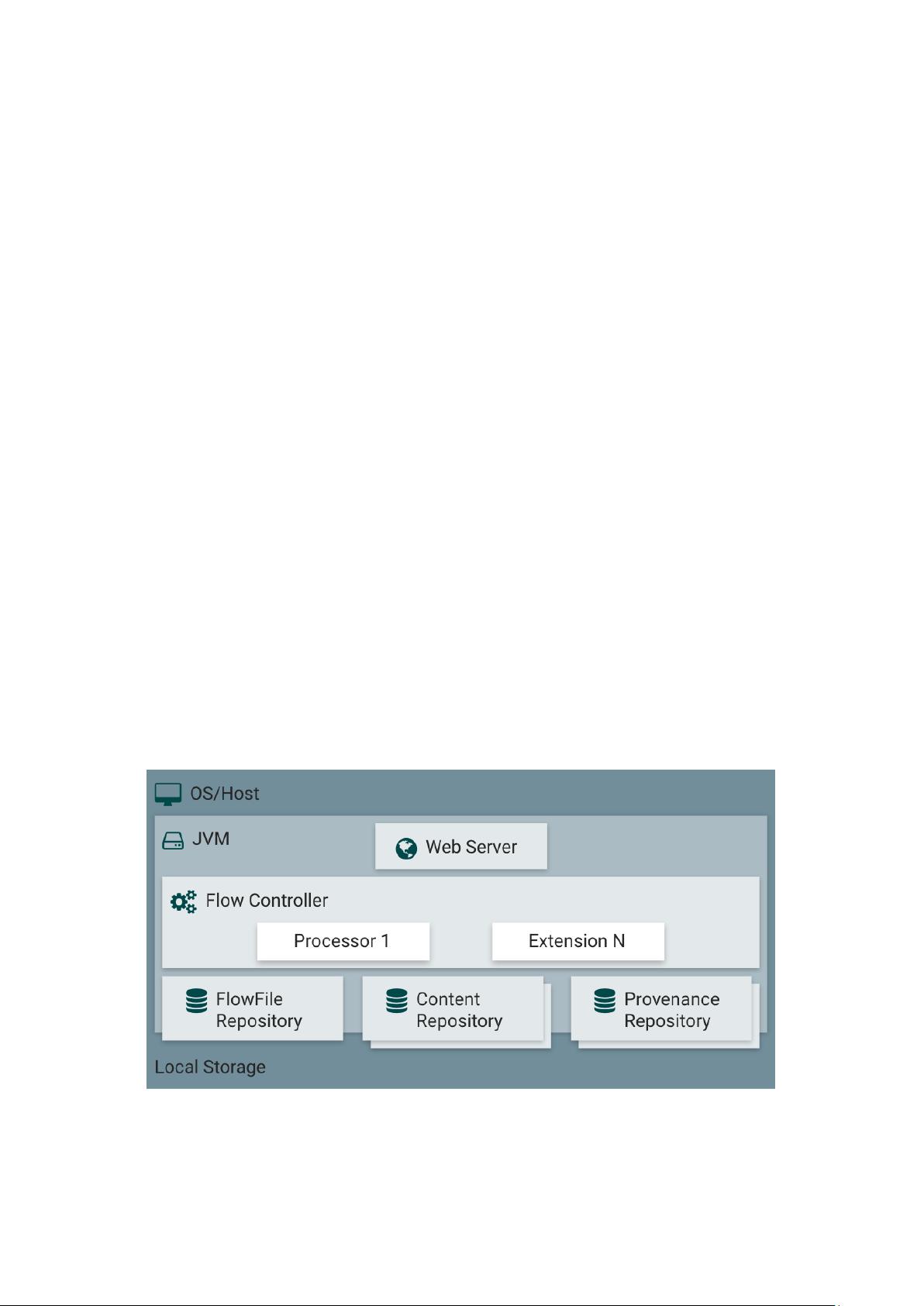
1.2.2 NiFi 架构
NiFi 是基于 Java 开发的,所以运行在 JVM 之上。NiFi 的核心部件在 JVM 中的位置
如上图:














