项目介绍11.docx
版权申诉
78 浏览量
2023-08-08
15:07:47
上传
评论
收藏 597KB DOCX 举报


项目介绍
一、自我介绍
面试官您好!
我叫 XXX,是 2019 年本科毕业于 XXXX 大学通信工程专业的毕业生。我的上
一份工作是大数据开发工程师并也是我的第一份工作,之所以这个方向首先是因
为我在大学期间学了一些计算机相关的知识,包括计算机网络、数据结构、C 语
言、Java 语言等计算机相关知识。在大二大三的时候我做的是电子信息相关的嵌
入式开发,后来在大三的时候参加了学校组织的一些大数据相关的一些讲座,并
在那之后开始对大数据这个方向非常感兴趣,于是决定想往大数据这个方向发展,
所以在后续打大学生涯里先后学习了大数据相关的框架以及各种组件,比如用于
分布式存储和计算的 Hadoop 框架及其生态(离线计算的 Mapreduce、分布式存储
系统 Hdfs、用于资源调度的 Yarn、数据层的 Hive 数据查询)、用于传输和采集数
据的 Flum、Kafka、用于任务调度的 Azkaban、以及分布式实时计算框架如 Flink
和 Sparkstreaming 实时计算。
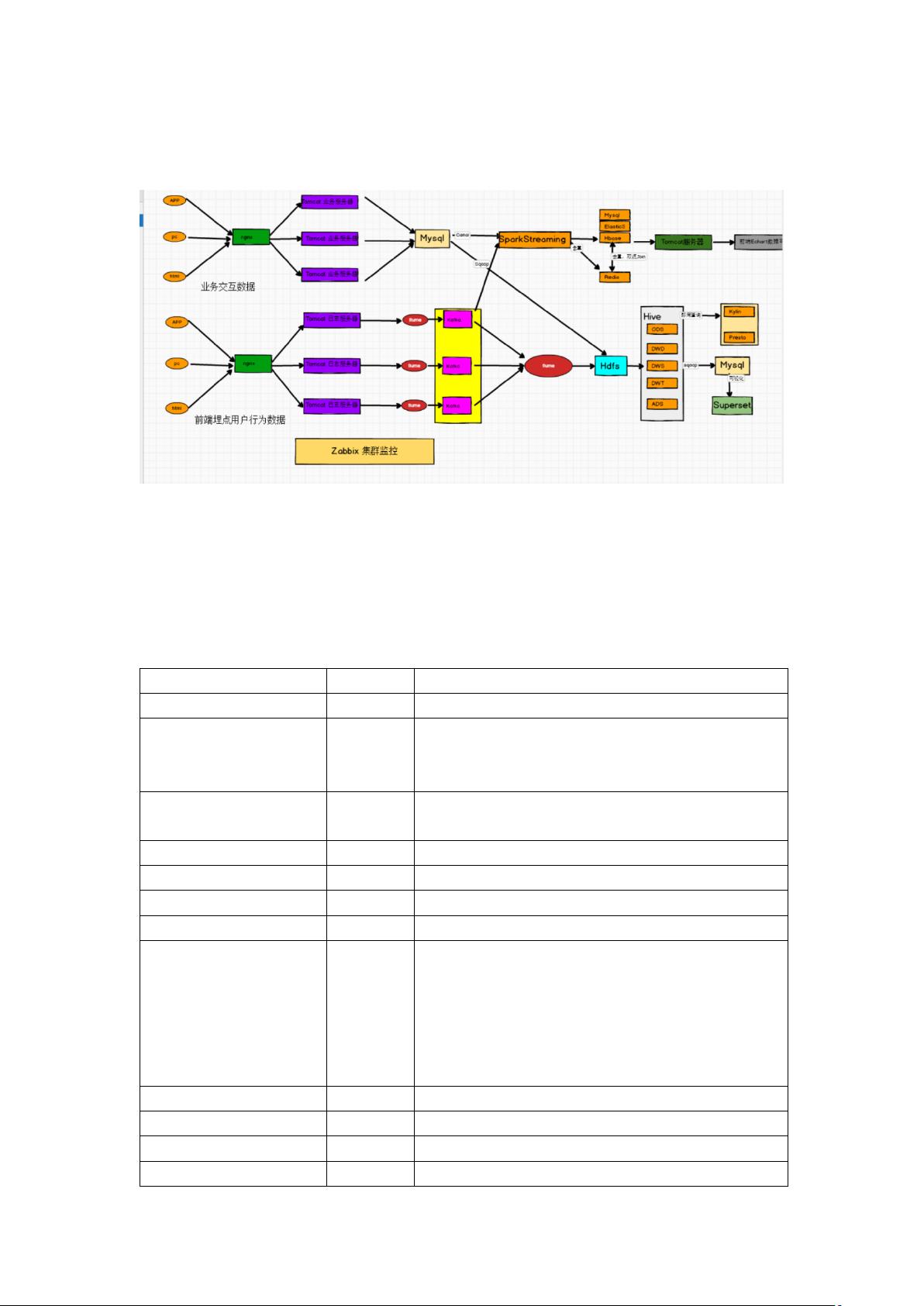
后来在毕业以后进了一家电商公司做数据开发岗,因为刚进入公司的时候公
司的数据部门是刚起步,所以经历了项目从 0 到 1 从无到有的完整开发流程。我
们部门所做的项目是对公司的电商平台的业务数据和日志数据做分析和处理为
目的。所以在这家公司的一多年里,我参与了项目的数据平台搭建、数仓项目的
离线计算和实时分析,其中包括了服务器选型、项目架构设计、框架版本选型;
数据仓库的建模、离线指标分析计算以及实时分析计算、数据质量监控等待一系
列流程。
下面是我在这家公司所做的项目的介绍与一些具体细节:
二、从服务器购买开始规划大数据
1、确定集群规模



剩余46页未读,继续阅读
资源评论



AI+Maynor
- 粉丝: 7w+
- 资源: 167

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- Python 程序语言设计模式思路-结构型模式:组合模式:将对象组合成树形结构
- 毕业设计基于python矩阵分解的推荐算法研究源码+详细文档+全部数据资料 高分项目.zip
- 基于网络的入侵检测系统源码+数据集+详细文档(高分毕业设计).zip
- 微信小程序源码 旅行故事分享 - 面包旅行App界面设计与文本展示资源下载
- 微信小程序源码 创意互动游戏 - 你画我猜App下载
- 摸底考试_学生版20230305.py
- 课程设计基于FPGA数字钟课程设计源码+课设报告(95分以上).zip
- 基于Java的企业家申报系统设计源码
- Cesium案例,集成各种模型,推演,各种Cesium效果
- 基于Python的Struts2全漏洞扫描利用工具设计源码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


