
人工智能导论笔记总结(知识图谱+机器学习部分)

需积分: 0 167 浏览量
更新于2024-01-18
3
收藏 1.76MB PDF 举报
《人工智能导论笔记总结——知识图谱与机器学习》
一、知识图谱
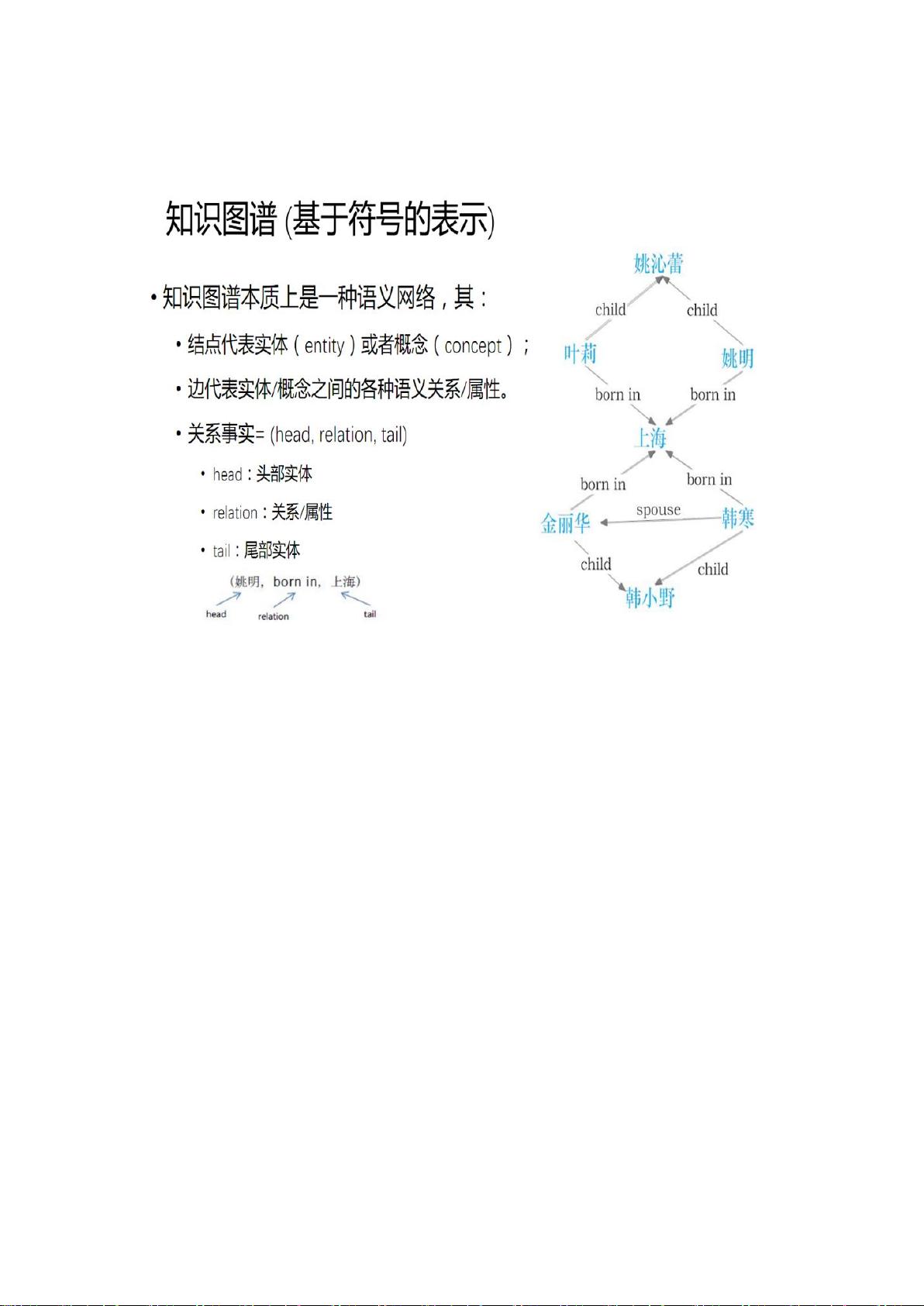
知识图谱,作为一种将知识以图形形式展示的语义网络,它揭示了实体之间的复杂关系。知识图谱通常由多种类型的节点(代表实体)和边(表示关系)构成,形成了一个多关系图。基于符号表示的知识图谱,强调逻辑结构,分为数据层和模式层。
1. 模式层是知识图谱的骨架,它以本体论为理论基础,定义了数据的组织模式和相互关系。数据模型描绘了数据的结构和组织方式。
2. 数据层则是知识图谱的血肉,包含具体的实体和它们的关系,这些数据是根据数据模型组织的。构建知识图谱有两种主要方法:自顶向下,先设计数据模型再填充数据;自下向上,先收集数据再归纳模式。
知识图谱的数据存储涉及到如何有效地存储和检索这些丰富的结构化信息。构建过程包括知识提取、知识融合(实体对齐)、数据模型构建和质量评估等多个步骤。
二、机器学习
机器学习是通过学习数据中的模式,以提升模型预测或决策的能力。理解和掌握机器学习的基本术语至关重要:
1. 数据集是所有用于学习的数据集合。
2. 样本是数据集中的每个独立记录,描述了一个事件或对象。
3. 特征或属性是样本在特定方面的表现或性质,形成特征向量。
4. 学习或训练是根据数据创建模型的过程,由特定的学习算法驱动。
5. 训练数据用于模型训练,而训练样本是训练数据的单个实例。
6. 标记是提供预期结果的信息,用于监督学习。
7. 误差是模型输出与真实值之间的差距,是评估模型性能的关键指标。
8. 验证方法如10折交叉验证,用于评估模型的泛化能力。
三、机器学习算法
1. 监督学习,包括分类和回归问题。分类如决策树、贝叶斯、SVM和逻辑回归,而回归如线性回归、岭回归和Lasso回归。
2. 无监督学习,如聚类算法,数据未标记,目标是发现数据内在的结构和规律。
3. 半监督学习介于两者之间,利用少量标记数据进行学习。
机器学习流程包括数据采集、处理、特征工程(构建、提取、选择)、模型构建(训练集和测试集划分、算法选择、模型优化和融合)、以及模型评估(如混淆矩阵、准确率、精确率、召回率等)。评估方法有留出法、交叉验证法(如留一法)和自助法等,以防止过拟合和欠拟合。
总结,人工智能导论涵盖了知识图谱的构建和理解,以及机器学习的基础概念、算法及其评估方法。深入研究这些知识点,有助于我们更好地理解和应用人工智能技术,解决现实世界的问题。



2017-12-12 上传
123 浏览量
199 浏览量
190 浏览量
117 浏览量
167 浏览量
2021-01-25 上传
189 浏览量
136 浏览量
158 浏览量
2023-07-02 上传
118 浏览量
2023-03-31 上传
189 浏览量
资源评论


碳基肥宅
- 粉丝: 8018
- 资源: 19









