
《计算机软件基础》多媒体教程
第八讲
第二章 UNIX 的软件工具
2.4 sed
※ sed概述
sed(Streamer Editor)称为字符流编辑程序,是一个非交互式的文本编辑程序,作者为
Lee E. McMahon(李 麦克马洪• )。
适用于 sed 的情况为:
⊙ 不适合vi等交互编辑程序
有的文件行数太多或某些行的字符太多,使用 vi 时读入文件和写出文件的时间很长。
⊙ 全局编辑操作
对文件进行编辑的命令是事先确定的,并且适合于对文件进行全局编辑操作。或者命
令中含有的字符数较多,为避免在键入命令时出错而不宜于进行交互编辑。
⊙ shell编程
可以把 sed 命令写入 shell 程序。更多的情况是利用 sed 可以实现流水线操作。
※ sed的执行方式
⊙ 方式1
sed '
命令
' [
输入文件
] 或者
⊙ 方式2
sed -f
命令文件
[
输入文件
]
⊙ 功能
表示可以在 shell 命令行中执行 sed
命令
(用单引号括起)。-f 表示指定的
命令文件
中含
有 sed 命令,称为 sed 命令文件。如果缺省
输入文件
,sed 的输入将指向标准输入。sed
的输出如果不在 sed 命令中描述,则将输出(编辑的结果)送至标准输出。
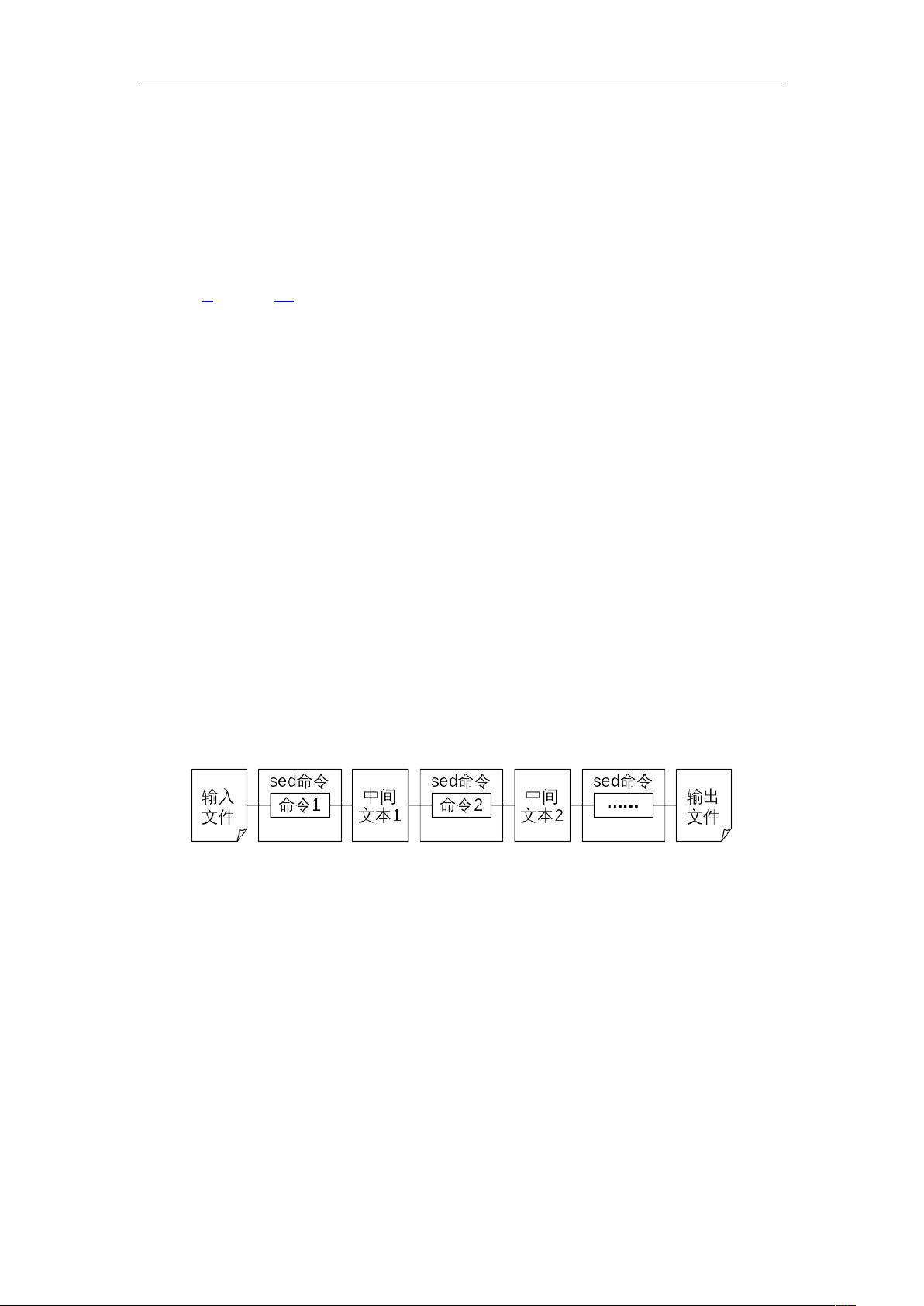
在 sed 的工作流程中,如果有多个命令,这些命令将依次执行。每执行一个命令,总
是对搜索到的匹配行进行处理,连同不匹配的行(不予处理)一起生成中间文本,传递给
下一个命令,直至最后生成输出文件。
※ sed的命令格式
[addr1[,addr2]] [!] function[/cmd]<CR>
表示用 function(命令)处理由 addr1[,addr2] (地址表达式)匹配的行。
如果缺省 addr1[,addr2],表示对所有行执行 function。
如果加!,表示对不匹配 addr1[,addr2]的行执行 function。
cmd 表示命令的辅助功能。
由于 sed 的许多基本操作也是由 ed 程序的函数实现的,因此 sed 的 addr1[,addr2]和
function 均与 vi 的全局操作命令相同。
⊙ addr1[,addr2] (地址表达式,又称行地址address)
行号
匹配对应的行
/pattern/ 匹配/pattern/的行
addr1,addr2 从匹配 addr1 到匹配 addr2 之间的行
缺省 所有行
⊙ 常用的function(命令)
d 命令 删除由 pattern 匹配的行

剩余12页未读,继续阅读
资源评论


wxg520cxl
- 粉丝: 25
- 资源: 3万+









最新资源
- 强化学习控制电动汽车储能系统的Matlab项目.rar
- 强化学习算法的基准案例:网格世界和推车上的倒立摆Matlab代码.rar
- 天邦达上位机软件2.35
- 轻型包裹运输的自主无人机递送系统附matlab代码.rar
- 深度强化学习应用无人机附python代码.rar
- 人类强化学习中的无模型过程Matlab代码.rar
- 设计和开发一种受蝙蝠启发的微型无人机,可以通过救援和监视行动协助灾害管理matlab代码.rar
- 实现分层强化学习算法Matlab实现.rar
- 使用 FDM 和 PWE 方法计算谐振微腔中麦克斯韦方程组的解matlab代码.rar
- 使用 EKF 的 Cubesat 姿态确定Matlab代码.rar
- Matlab实现TSOA-CNN-GRU-Mutilhead-Attention凌日优化算法优化卷积门控循环单元融合多头注意力机制多特征分类预测(含完整的程序,GUI设计和代码详解)
- 使用MATLAB的平方根无迹卡尔曼滤波器(SR-UKF)的简单、快速、可读的实现.rar
- 使用EKF、IECF和UKF估算非线性预测和测量Matlab代码.rar
- 基于Python语言的OpenSees算例(重点在于Python语言在OpenSees中的应用)
- 使用了随机梯度下降法(SGD)和批量梯度下降法(BGD)解决单层感知机问题Matlab代码.rar
- c语言课程设计-ktv歌曲系统
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


