

大数据技术之 Hadoop(生产调优手 册)
第 1 章 HDFS—核心参数
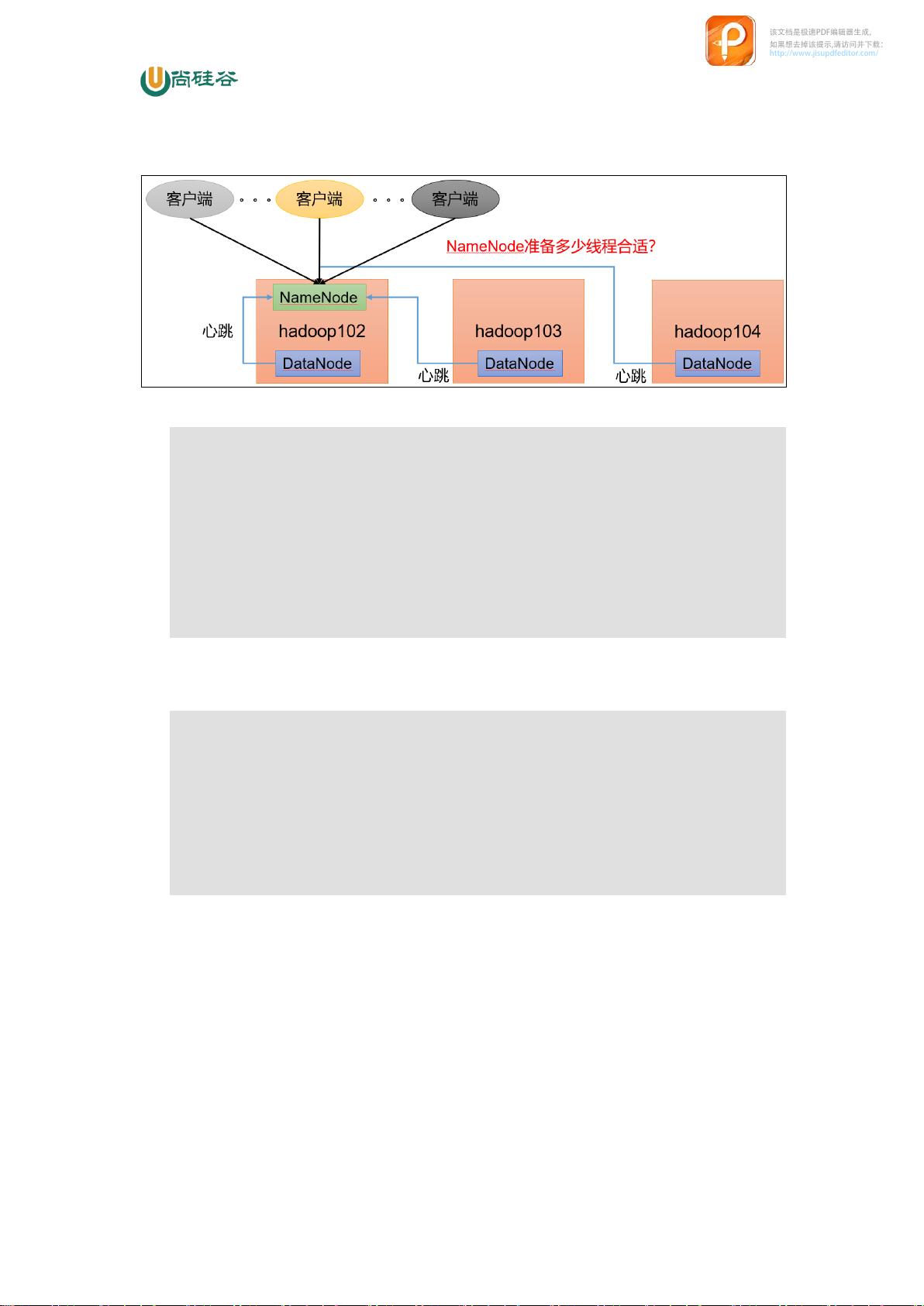
1.1 NameNode 内存生产配置
1)NameNode 内存计算
每个文件块大概占用 150byte,一台服务器 1 28G 内存为例,能存储多少文件块呢?
128 * 1024 * 1024 * 1024 / 150Byte ≈ 9.1 亿
G MB KB Byte
2)Hadoop2.x 系列,配置 NameNode 内存
NameNode 内存默认 2000m,如果服务器内存 4 G ,NameNode 内存可以配置 3g。在
hadoop-env.sh 文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m
3)Hadoop3.x 系列,配置 NameNode 内存
(1)hadoop-env.sh 中描述 Hadoop 的内存是动态分配的
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=
# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
HADOOP_NAMENODE_OPTS=-Xmx102400m
(2)查看 NameNode 占用内存
[atguigu@hadoop102 ~]$ jps
3088 NodeManager
2611 NameNode
3271 JobHistoryServer
2744 DataNode
该文档是极速PDF编辑器生成,
如果想去掉该提示,请访问并下载:
http://www.jisupdfeditor.com/


剩余40页未读,继续阅读
资源评论


锦时素年
- 粉丝: 0
- 资源: 19









最新资源
- AllSort(直接插入排序,希尔排序,选择排序,堆排序,冒泡排序,快速排序,归并排序)
- 模拟qsort,改造冒泡排序使其能排序任意数据类型,即日常练习
- 数组经典习题之顺序排序和二分查找和冒泡排序
- 基于 Oops Framework 提供的游戏项目开发模板,项目中提供了最新版本 Cocos Creator 3.x 插件与游戏资源初始化通用逻辑
- live-ai这是一个深度学习的资料
- FeiQ.rar 局域网内通信服务软件
- 172.16.100.195
- 光储并网simulink仿真模型,直流微电网 光伏系统采用扰动观察法是实现mppt控制,储能可由单独蓄电池构成,也可由蓄电池和超级电容构成的混合储能系统,并采用lpf进行功率分配 并网采用pq控制
- python编写微信读取smart200plc的数据发送给微信联系人
- 光储并网VSG系统Matlab simulink仿真模型,附参考文献 系统前级直流部分包括光伏阵列、变器、储能系统和双向dcdc变器,后级交流子系统包括逆变器LC滤波器,交流负载 光储并网VSG系
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


