管理系统模拟是运用计算机技术对真实管理系统进行抽象和复制,以便在虚拟环境中研究和优化系统行为的一种方法。在进行管理系统模拟时,数据的处理是至关重要的一步。以下是管理系统模拟中涉及的关键知识点:
1. **原始数据**:在进行系统模拟前,需要收集到足够的原始数据,这些数据通常来自实际系统的观测或项目管理人员提供的系统运行记录。数据的质量和数量直接影响模拟的准确性和可靠性。
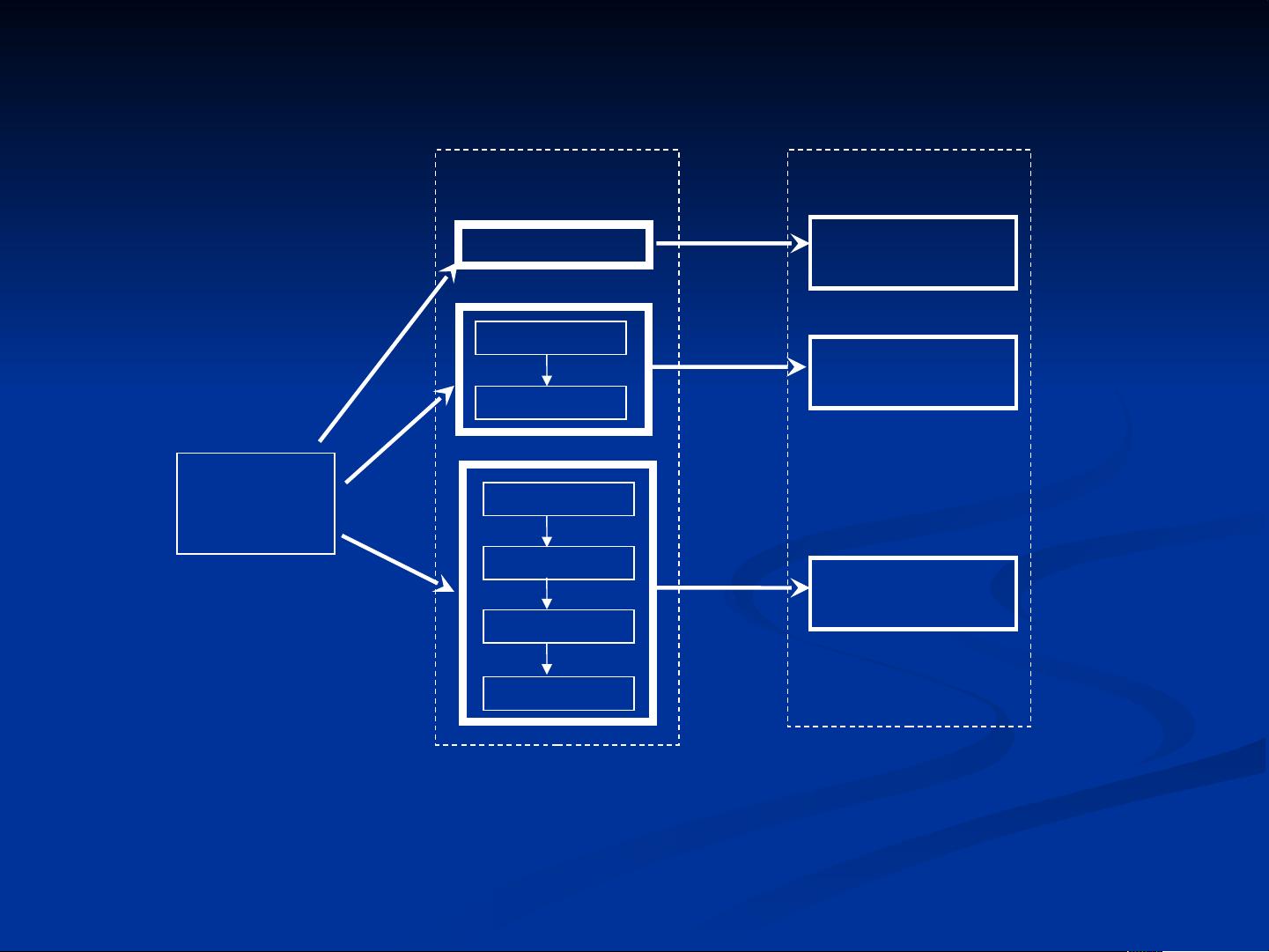
2. **数据建模**:数据建模分为几种不同的方法:
- **直接使用历史数据**:这种方法直接使用收集到的数据驱动仿真模型,可以验证模型的确定性,但可能因数据量有限而限制了多次仿真的可能性。
- **定义经验分布**:当数据量充足时,可以通过分析数据的频率和范围,生成随机变量来模拟实际数据,这样可以产生足够多的数据进行多次仿真试验。
- **拟合理论分布**:如果数据符合特定的理论分布(如正态分布、指数分布等),则可以通过参数估计和拟合度检验来构建理论分布模型,这种方法更为精确。
3. **数据收集**:数据收集应考虑以下几个要点:
- 分析数据的充分性:确保收集的数据能够代表系统的全貌。
- 数据分类:将性质相似的数据整合在一起。
- 相关性分析:检查随机变量之间是否存在关联。
- 自相关性检测:避免因样本间的自相关性导致的误差。
4. **随机变量分布的辨识**:识别数据遵循的分布类型是建模的关键步骤,主要包括连续型和离散型随机变量的分布辨识。
- **连续型随机变量**:通常使用点统计法(基于偏差系数)和直方图法。点统计法通过计算偏差系数并与理论分布比较,直方图法则通过绘制直方图并对比理论概率密度函数。
- **离散型随机变量**:辨识方法类似,但可能需要考虑更具体的分布形式,如泊松分布、二项分布等。
5. **参数估计和拟合度检验**:在确定了理论分布后,需要通过统计方法估计分布参数,如均值、方差等。然后进行拟合度检验,如Kolmogorov-Smirnov检验或Chi-squared检验,以确认实际数据与理论分布的匹配程度。
6. **应用实例**:在实际操作中,如汽车到达银行的时间间隔问题,可以通过比较偏差系数或直方图与理论分布的吻合程度来判断其是否服从指数分布。
综合以上内容,管理系统模拟的学习教案涵盖了从数据收集、处理到模型建立的全过程,通过理解这些知识点,学生可以掌握如何有效地构建和运行管理系统的模拟实验,以优化决策和解决问题。