机器学习5-分类算法之随机森林(Random Forest).pdf

随机森林(随机森林(Random Forest))
前言
一、随机森林
1.什么是随机森林
2.随机森林的特点
3.随机森林的生成
二、随机森林的函数模型
三、随机森林算法实现
1.数据的读取
2.数据的清洗和填充
3.数据的划分
4.代码的实现
总结
前言前言
随机森林(随机森林(Random Forest)) 是Bagging(一种并行式的集成学习方法)的一个拓展体,它的基学习器固定为决策
树,多棵树也就组成了森林,而“随机”则在于选择划分属性的随机,随机森林在训练基学习器时,也采用有放回采样的
方式添加样本扰动,同时它还引入了一种属性扰动,即在基决策树的训练过程中,在选择划分属性时,Random Forest
先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性,一般推荐K=log2(d)。
这样随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,从而进一步提升了基学习器之间的差异度。
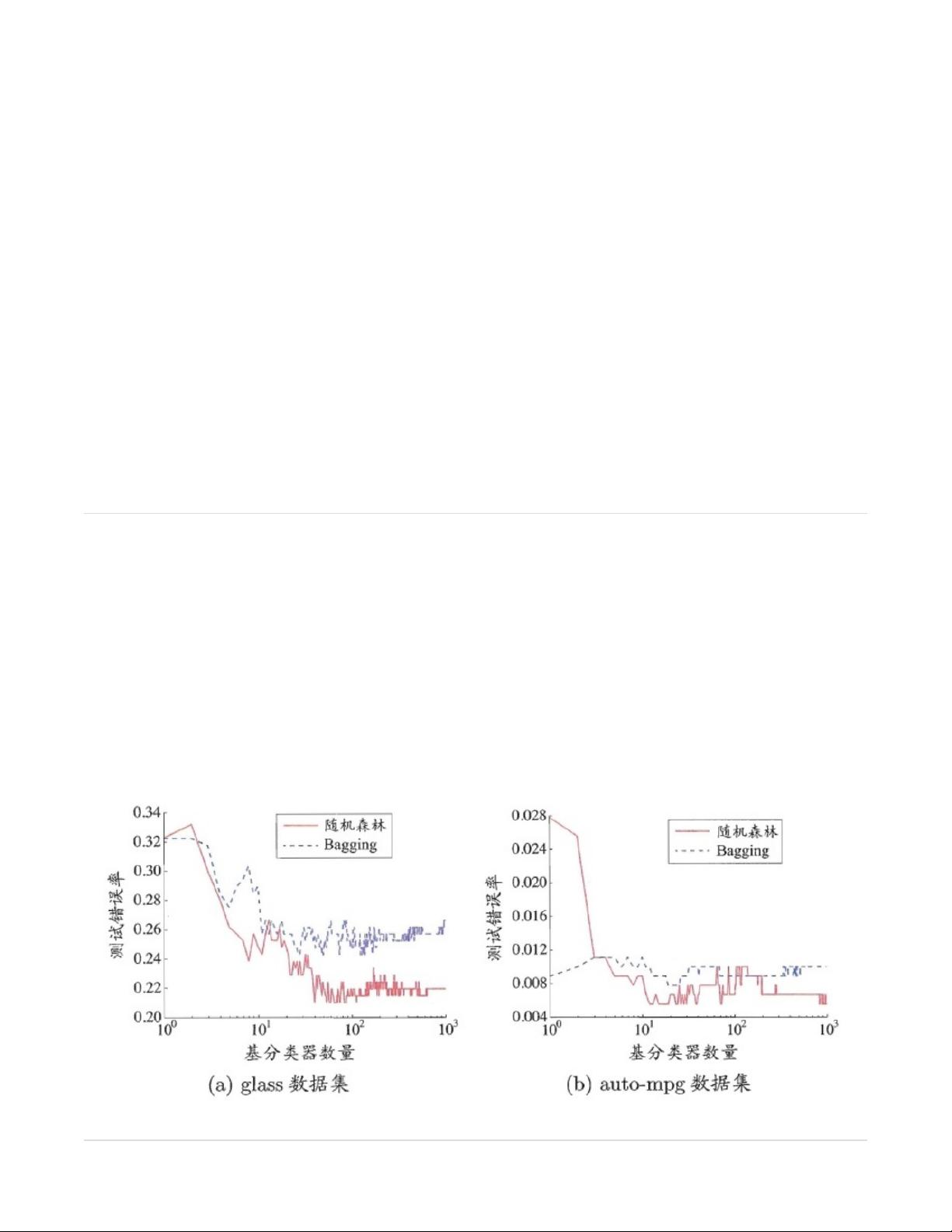
相比决策树的Bagging集成,随机森林的起始性能较差(由于属性扰动,基决策树的准确度有所下降),但随着基学
习器数目的增多,随机森林往往会收敛到更低的泛化误差。同时不同于Bagging中决策树从所有属性集中选择最优划
分属性,随机森林只在属性集的一个子集中选择划分属性,因此训练效率更高。


剩余11页未读,继续阅读
资源评论

 BJWcn2023-07-27这个文件的语言通俗易懂,让我即使是初学者也能够轻松理解其中的概念和原理。
BJWcn2023-07-27这个文件的语言通俗易懂,让我即使是初学者也能够轻松理解其中的概念和原理。 柔粟2023-07-27这个文件给出了一些常见问题和解决方案,对我理解随机森林算法的思路有了很大帮助。
柔粟2023-07-27这个文件给出了一些常见问题和解决方案,对我理解随机森林算法的思路有了很大帮助。 查理捡钢镚2023-07-27这个文件很详细地介绍了随机森林算法,让我对它有了更深入的了解。
查理捡钢镚2023-07-27这个文件很详细地介绍了随机森林算法,让我对它有了更深入的了解。 焦虑肇事者2023-07-27这个文件还介绍了一些随机森林算法的扩展和改进方法,让我对其未来的发展方向有了一些思考。
焦虑肇事者2023-07-27这个文件还介绍了一些随机森林算法的扩展和改进方法,让我对其未来的发展方向有了一些思考。 邢小鹏2023-07-27这个文件提供了很多实例和案例,帮助我更好地理解随机森林算法的应用场景。
邢小鹏2023-07-27这个文件提供了很多实例和案例,帮助我更好地理解随机森林算法的应用场景。

快乐无限出发
- 粉丝: 1126
- 资源: 7260









最新资源
- Screenshot_20240427_031602.jpg
- 网页PDF_2024年04月26日 23-46-14_QQ浏览器网页保存_QQ浏览器转格式(6).docx
- 直接插入排序,冒泡排序,直接选择排序.zip
- 在排序2的基础上,再次对快排进行优化,其次增加快排非递归,归并排序,归并排序非递归版.zip
- 实现了7种排序算法.三种复杂度排序.三种nlogn复杂度排序(堆排序,归并排序,快速排序)一种线性复杂度的排序.zip
- 冒泡排序 直接选择排序 直接插入排序 随机快速排序 归并排序 堆排序.zip
- 课设-内部排序算法比较 包括冒泡排序、直接插入排序、简单选择排序、快速排序、希尔排序、归并排序和堆排序.zip
- Python排序算法.zip
- C语言实现直接插入排序、希尔排序、选择排序、冒泡排序、堆排序、快速排序、归并排序、计数排序,并带图详解.zip
- 常用工具集参考用于图像等数据处理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


