
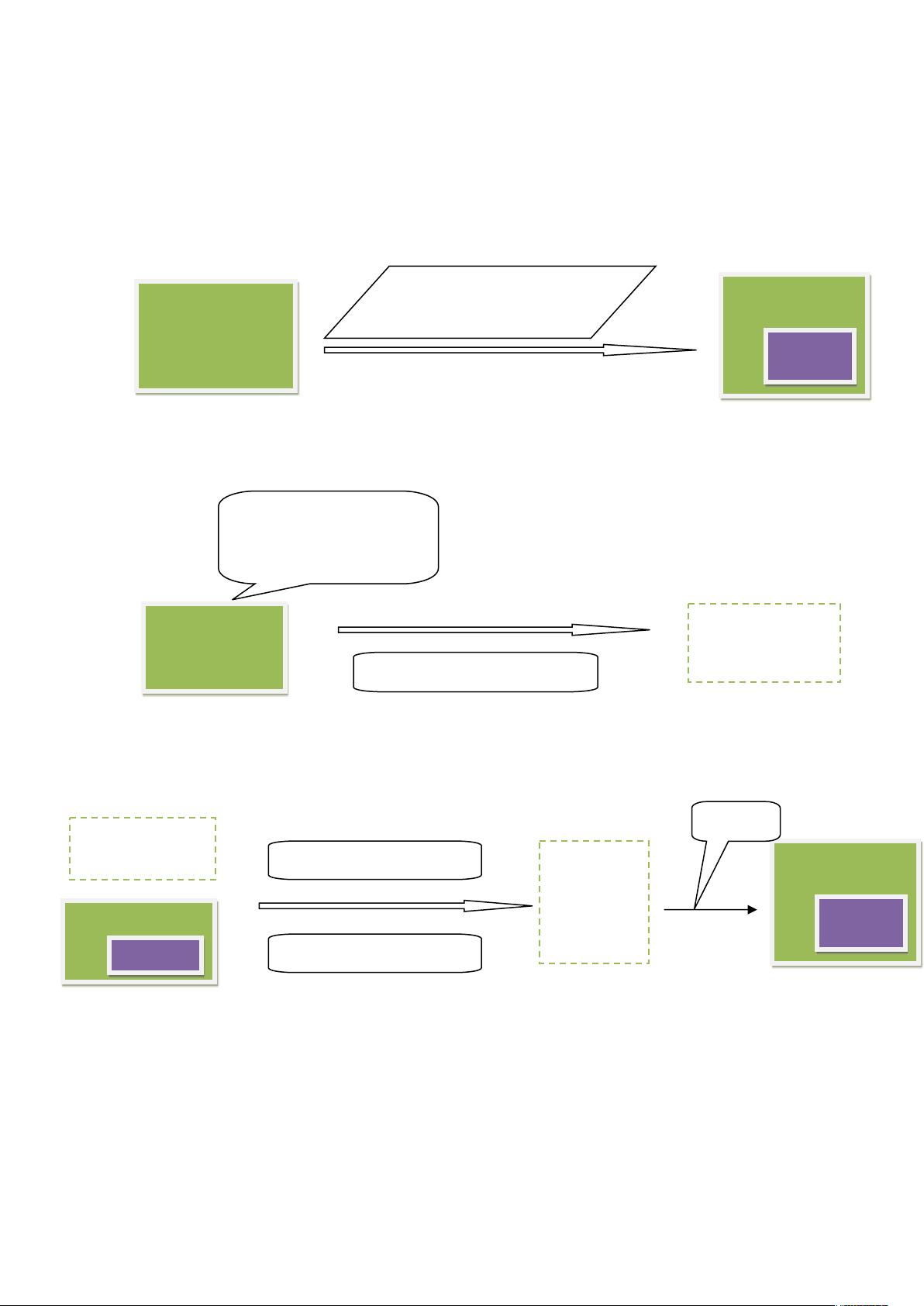
一、Injector 初始化 crawldb 的总体过程:
injector.inject(crawlDb, rootUrlDir);
第一个,还是详细点,我把上面的总体过程分为两步:
第一步:
第二步:
urlDir
urlDir+current->current
crawldb
current
urlDir tempDir
SequenceFileOutputFormat
urlDir 是程序入口时,用
户指定的那个 url 列表所
在的目录
tempDir
crawldb
current
newCrawldb
SequenceFileInputFormat
MapFileOutputFormat
crawldb
current
rename
资源评论


weizhilizhiwei
- 粉丝: 0
- 资源: 8











