谱聚类算法是一种在计算机科学领域,特别是在数据挖掘和机器学习中广泛应用的无监督学习方法。它主要用于将数据集划分为不同的组或“簇”,在这些簇中,内部元素之间的相似性较高,而不同簇之间的相似性较低。谱聚类算法的名称来源于其对数据的“谱”属性进行分析,即利用数据的特征值或特征向量来进行聚类。
### 谱聚类的基础
谱聚类的核心思想是基于图论,特别是图谱理论。在图谱理论中,一个数据集可以被看作是一个图,其中每个数据点是图中的一个节点,而节点之间的边表示数据点之间的相似度。这种相似度通常通过距离或相关性来度量。谱聚类的目标是找到一种划分方式,使得在同一簇内的节点之间的连接更紧密,而不同簇间的连接更稀疏。
### 图的拉普拉斯矩阵
在谱聚类中,关键的概念是图的拉普拉斯矩阵。拉普拉斯矩阵有两种形式:非归一化拉普拉斯矩阵(L = D - W)和归一化拉普拉斯矩阵(L = I - D^(-1/2)WD^(-1/2)),其中D是对角矩阵,其对角线元素为每条边的权重之和,W是邻接矩阵,表示节点之间的相似度。拉普拉斯矩阵反映了图的整体结构,它的特征值和特征向量包含了图的谱信息。
### 特征分解与聚类
拉普拉斯矩阵的特征分解可以得到一系列特征值和对应的特征向量。小的特征值对应于图的全局特性,而大的特征值则对应于局部特性。谱聚类的基本策略是选取前k个最小的非零特征值对应的特征向量,这些特征向量构成了数据的一种低维表示。在降维后的空间中,数据点更容易被自然地分成不同的簇,因为它们在这个空间中的分布会更加分离。
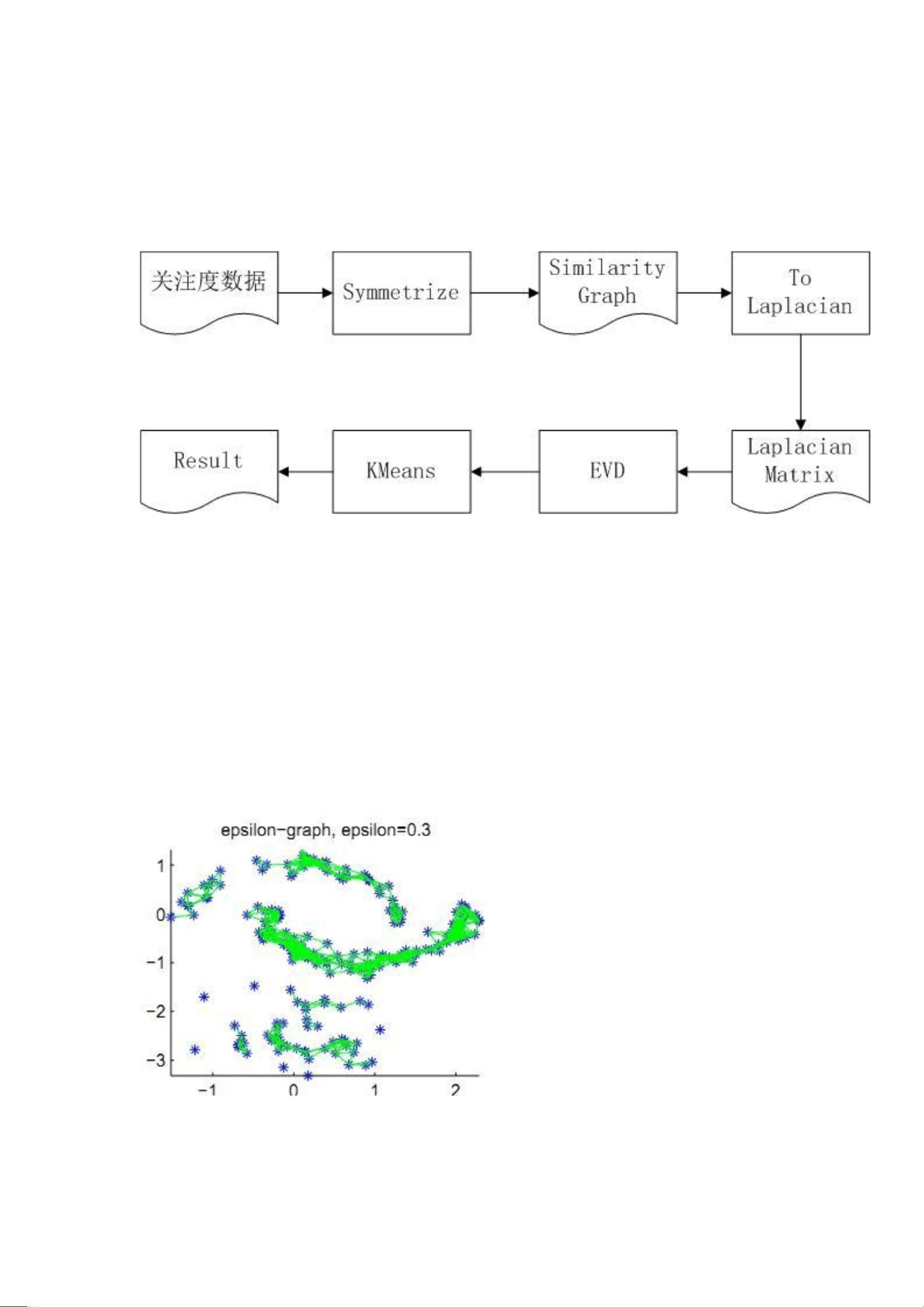
### 聚类过程
1. **构建图**:根据数据点之间的相似性构建图,可以使用欧氏距离、余弦相似度等方法。
2. **计算拉普拉斯矩阵**:根据图的结构计算非归一化或归一化的拉普拉斯矩阵。
3. **特征分解**:对拉普拉斯矩阵进行特征分解,得到特征值和特征向量。
4. **选择特征向量**:选取前k个最小的非零特征向量作为新的数据表示。
5. **执行聚类**:在新空间中应用简单的聚类算法,如K-means,将数据点分配到最近的簇中心。
### 优点与局限性
谱聚类的优点包括:
- **适应性强**:能够处理非凸和不规则形状的簇。
- **全局优化**:通过考虑所有节点的关系,寻找全局最优解。
- **鲁棒性**:对噪声和异常值具有一定的抵抗能力。
然而,谱聚类也存在一些局限性:
- **计算复杂度高**:特征分解的过程可能需要大量计算资源,特别是对于大规模数据集。
- **参数选择**:需要预先确定簇的数量k,这在实际应用中往往难以确定。
- **对初始条件敏感**:对于K-means等后续聚类算法,初始簇中心的选择可能会影响最终结果。
### 应用场景
谱聚类算法在许多领域都有应用,例如图像分割、社交网络分析、生物信息学中的基因分群、推荐系统等。它能够处理非欧几里得空间的数据,并且在处理复杂结构的聚类问题时展现出优越的性能。
谱聚类算法是一种强大的无监督学习工具,它利用图谱理论来揭示数据的内在结构。虽然存在一定的计算挑战,但其对复杂数据集的处理能力和良好的聚类效果使其在许多实际问题中得到广泛应用。